大话 transformer 架构
大话 transformer 架构
前言
去年 OpenAI 发布的 ChatGPT3 开启了新一轮对 AI 研究的热潮,不过,这一切的故事还要从 2017 年(甚至更早)说起。自从 deepMind 团队发表的 “Attention is all your need” 论文提出了 transformer 架构后,绝大部分有影响力模型的基础架构都基于的 transformer(比如基于 decode 的GPT、基于 encode 的 BERT、基于 encode-decode 的 T5 等等),具体有哪些模型可以来看看 huggingface 罗列的
故事的开始
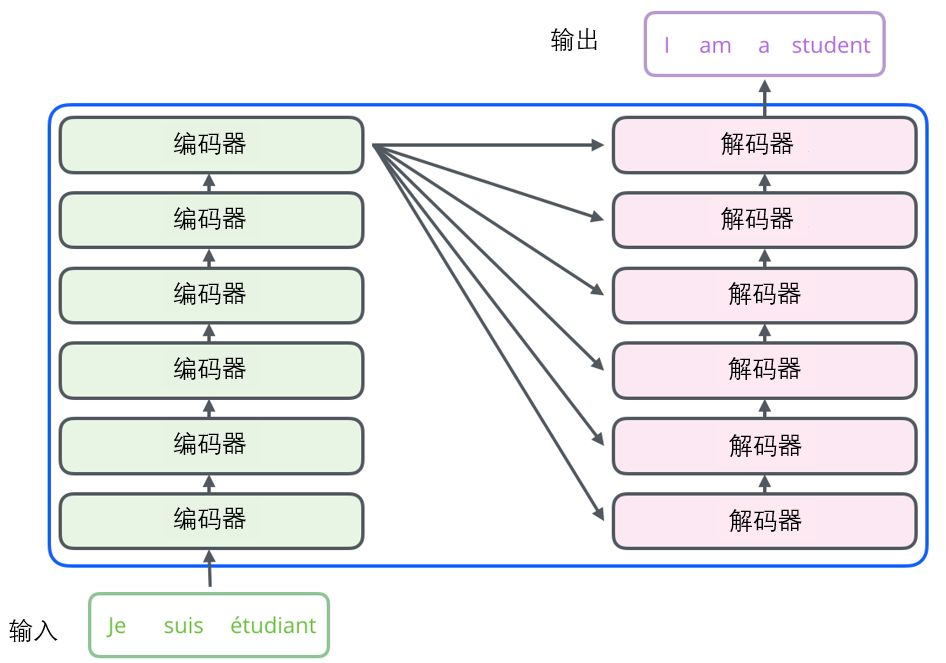
与大多数博客一样,我们需要请出论文中最有名的架构图来解释 transformer:
上面的架构图可以简单地分成两个部分,encoder(左边)和 decoder(右边)。而组成他们的组件又有一些共通之处,因此 transformer 架构其实没有大家想的那样复杂。
虽然现在 transformer 被应用于非常多的 AI 领域,但起初它是在自然语言处理 (NLP) 中针对序列到序列 (seq2seq) 的任务被提出的。所谓的 seq2seq ,可以简单地理解为自然语言翻译:将一串中文翻译成一串英文,对于计算机而言就是程序将一串字符串转换到了另一串字符串。我们将以此为背景讨论 transformer,希望能对刚入门的新人有所帮助。
encoder & decoder 初理解
在翻译外语时,我们的大脑通常先读入原语言的文字,并理解出文字的大意,然后再输出成对应的语言。而 transformer 的运行过程与上述情况很类似。transformer 的 encoder(中文译:编码器)负责流程的前半部分,读入文字,“编码地”理解文字大意,而 decoder(中文译:解码器)负责在知晓文字大意后,“解码地”将意思用目标语言输出。
将上述过程用数学描述,即为:
encoder 将输入的文字序列 {$ x_1, x_2, … x_n } 映射为 { z_1, z_2, …, z_n }(transformer 自己的理解大意),decoder 拿到 encoder 的输出,在知晓文字大意后,会生成一个文字序列 { y_1, y_2, … , y_m $}。
注意到,encoder 可以一次性看到所有的输入(就如同人们翻译文字时必须根据上下文意思理解原文)但 decoder 只能一个一个的输出,并且还需要根据自己上一个的输出确定自己的本次输出(像极了翻译时一字一句写下外文的样子),因此是一个自回归模型。
深入编码器
基本数据流
将目标聚焦到架构图的左边,注意到,encoder 由 N 个相同的模块组成,而最下面是模型的入口。输入 inputs 可以简单地理解为读入的文字序列,它需要经过 Input Embedding 和 Positional Encoding 地处理(这些我们稍后会讨论),再进入到编码器中。数据流进入编码器后,一方面会兵分三路进入到多头注意力块 (multi-head Attention),另一方面会使用残差连接将原始输入添加到输出中,最后执行归一化操作。随后,数据会进入第二个子层 Feed Forward,也就是全连接层,然后再执行残差连接和归一化操作。得到的输出作为下一编码层的输入,再重复上述运算,如此操作 N 次,即完成了对文本的编码。
注意力机制
多头注意力
随后,数据会进入第二个子层 Feed Forward,也就是全连接层。
残差连接需要输入和输出的维度一致,所以每一层的输出维度在transformer里都是固定的,都是512维。
可以看到整个结构的超参数设计非常的简单,只需要调节N和输出的维度就可以了,可以衍生出后续的一系列网络设计,诸如BERT和GPT等等。
残差连接在 Transformer 架构中至关重要。
1、首先,与 ResNet 类似,Transformers 层级很深。某些模型的编码器中包含超过 24 个 blocks。因此,残差连接对于模型梯度的平滑流动至关重要。
2、如果没有残余连接,原始序列的信息就会丢失。多头注意力层忽略序列中元素的位置,并且只能根据输入特征来学习它。删除残余连接意味着该信息在第一个注意层之后(初始化之后)丢失,并且使用随机初始化的查询和键向量,位置 i 的输出向量与其原始输入无关。注意力的所有输出都可能表示相似/相同的信息,并且模型没有机会区分哪些信息来自哪个输入元素。
归一化层在 Transformer 架构中也发挥着重要作用,它可以实现更快的训练速度。
除了多头注意力之外,模型中还包括一个小型全连接前馈网络,应用于每一个 block。它增加了模型的复杂度,并允许单独对每个序列元素进行转换。