CUDA 进阶之内存优化
CUDA 进阶之内存优化 关于主机与设备间的数据传输
前言
内存优化是性能优化主题中最重要的部分,其目标是通过最大化带宽来提高硬件的使用率和满载率。在具体实践中,我们期望尽可能多地使用快速内存,而尽可能少地使用慢速内存。本博客主要讨论主机与设备间的数据迁移以及涉及到的各种内存,并试图回答如何最好地设置、使用内存以提高 CUDA 程序的运行效率这一问题。
以英伟达的 V100 设备为例,设备间内存的理论最大带宽(898 GB/s)远比设备与主机间的理论最大带宽(16 GB/s for PCIe3x16)快得多。因此,为获得最佳性能,应尽量减少主机与设备间的数据传输,即使是 GPU 上运行的内核与主机的 CPU 相比没有任何优势。更多情况下,我们应在设备内存中创建中间数据结构, 交由设备计算,最后在没有映射到主机内存的情况下销毁。
此外,由于每次传输都有相关的固定开销,因此将许多小数据包装成一个较大的数据包进行传输,会比多次传输小数据包要好得多!即使这样做需要:1)将不连续的内存区域打包到一个连续的缓冲区,2)消耗一定资源来封装和解封。
最后,主机和设备之间的高带宽通常是通过 page-locked(或 pinned)来实现,接下来我们将重点阐述 pinned 内存。
pinned 内存
原理
pinned 内存有时也会被称作为页锁定内存,或者固定内存。本文中皆以 pinned 内存指代。
pinned 内存是相对于一般的页可分配内存而言的。一般地,主机上的内存都会被操作系统采用分页机制管理,我们平时编程中遇到的“地址”事实上都是虚拟地址,需要通过地址转换才能获得物理地址(有时甚至不在物理内存中,会发生缺页),进而获得数据。
因此对于页可分配内存,由于 GPU 获得的地址是虚拟内存的地址,不可直接获得对应物理内存页上的数据,因此要想实现主机与设备间的数据传输,必须先将页可分配内存上的数据转移到一个临时的 pinned 内存页上,再实现内存传输,如下图。

而对于 pinned 内存,操作系统不会对其进行分页和交换操作,其内存页会被“固定存储”在物理内存中,GPU 获得的地址就是物理地址,因此可直接通过 DMA 机制在主机和 GPU 之间快速传输数据。
正因如此,pinned 内存传输速率接近理论峰值。例如,在使用 PCIe3x16 的机器上,pinned 内存可以达到大约 12 GB/s 的传输速率。
使用
pinned 内存是使用 cudaHostAlloc() 分配,使用 cudaFreeHost() 回收。对于那些已经被分配的内存区域,可使用 cudaHostRegister() 来 pin 住内存,无需重新分配单独的 pinned 内存再将数据拷入其中。
虽然 pinned 内存速度快,但不应被过度地使用,因为它减少了操作系统和其他程序可用的物理内存量,从而拖累系统的整体性能。因此 pinned 内存其实是个稀缺资源,但令人头疼的是到底多少合适是很难知晓的。此外,pinned 内存分配可能会失败,因此应该始终检查错误,譬如:
1 | |
示例
使用 pinned 内存传输数据时仍可使用 cudaMemcpy() 这类函数。下面我们做个实验来看看到底 pinned 内存比一般内存要快多少。
先是分配内存:
1 | |
然后我们需要定义一个拷贝函数,让不同的内存页来分别执行:
1 | |
最后让他们分别执行:
1 | |
首先说明一下本人机器型号及规格:
- NVIDIA GeForce RTX 3060 Ti,Compute capability: 8.6
- AMD Ryzen 5 5600X 6-Core Processor 3.70 GHz
然后咱们来看看性能差距究竟如何:
1 | |
可以看到,使用 pinned 内存可以让带宽提升2-3倍,这对于内存受限的应用而言是一个巨大的福音。pinned 内存对于 CUDA 程序的内存优化有非常重要的意义,之后本文介绍的优化技术都与它相关。
异步传输
原理
常用的 cudaMemcpy() 函数实际上是一个阻塞函数,即主线程必须等待数据拷贝完毕后才会将控制返回。而使用 cudaMemcpyAsync() 这种非阻塞的异步函数,主线程会在数据传输启动后就返回,并继续执行。异步传输需要 pinned 内存(参见上节),且它需要一个额外的参数,stream ID。这个 stream ID 可以理解为 GPU 设备上按顺序执行的一系列操作(指令),设计人员很形象地将其比喻为流水,由一系列指令构成的运行流。不同流中的操作可以交错执行,在某些情况下可以重叠。所谓的重叠是指 GPU 在同一时间段内完成数据传输和计算任务,于是数据传输所花的时间被计算时间“重叠”了,花费的总时间也就少了。
使用
下例子展示了主机计算与数据的重叠:
1 | |
cudaMempyAsync() 函数的最后一个参数是 stream ID,这是相比 cudaMemcpy() 额外多出来的参数。在本例中使用默认流,流0。内核也使用默认流,它不会开始执行,直到内存复制完成。因此,不需要显式同步。因为内存拷贝和内核都立即将控制权返回给主机,所以主机函数 cpuFunction() 的执行会与数据传输重叠。
当然,对于异步传输,我们显然更希望将 GPU 的计算时间与数据传输时间重叠,这样这项技术才有真正的用武之地。在刚刚的例子中,数据复制和内核执行仍然是顺序发生的(先执行 MemcpyAsync 在执行 kernel 函数,而主机端的 cpuFunction() 可以先执行)。在能够并发复制和计算的设备上,可以将设备上的内核执行与主机和设备之间的数据传输重叠。设备是否具有此功能,可以通过 cudaDeviceProp() 返回的 asyncEngineCount 字段指示。在具有此功能的设备上,重叠再次需要固定的主机内存,此外,数据传输和执行计算的内核必须使用不同的非默认流(strem id非零的流)。这种重叠必须使用非默认流,因为默认流上的操作(包括内存复制、内核调用等等),只有在设备的其他所有流都“没事做”时才开始,根本无法重叠。下一个例子展示了两个流之间的重叠:
1 | |
在上面的示例中,创建了两个流,分别在数据传输和内核执行中使用,cudaMemcpyAsync 调用的最后一个参数指明使用了流1,而内核执行配置指明使用流2。此时这两个流可以并发执行,一个拷贝数据一个计算(当然前提是他们不能相互依赖)。
并发传输和执行演示了如何使内核执行与异步数据传输重叠。当数据依赖关系可以将数据分解成块并分多个阶段传输时,可以使用此技术,并在数据到达时启动多个内核对每个块进行操作。下图不严谨地展示了这一技巧的优点。其中第一个柱状图表示将数据先全体搬运到设备内存,再执行运算所需要的时间(浅绿色表示数据传输时间,红色表示数据计算时间),第二个柱状图表示使用并发异步传输任务的完成情况,可以很明显地看到使用异步传输的总时间要短不少:
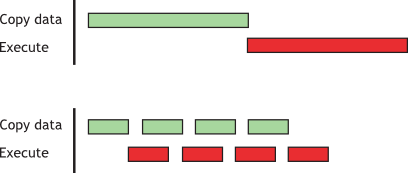
但这里出现了个问题,前言中本文说到:
由于每次传输都有相关的固定开销,因此将许多小数据包装成一个较大的数据包进行传输,会比多次传输小数据包要好得多
而在这里,我们又说将数据分解成块并分多个阶段传输可以重叠传输时间,提升性能。那么这两种叙述是否存在冲突?如何更好地理解这两句看似矛盾的话?
示例
为了证明其效率,也为了解答刚才提出的问题,我们比较下面两个例子:
1 | |
1 | |
顺序复制和执行以及阶段并发复制和执行证明了这一点。它们产生相同的结果。第一部分展示了引用顺序实现,它传输和操作一个包含N个浮点数的数组(其中N被假定可以被nThreads平均整除)。
仍然是在我的主机上做了实验,该实验中,blocksize 为 256 ,一共 4 个流,每个流处理 4KB 的数据(太小的数据结果不明显),因此总共需要处理 4x1024x256x4 Bytes 的数据。为了同时测量计算的精确度,我让 GPU 计算一个相对有意义的核函数,随后计算该结果与正确值的差距,具体如下:
1 | |
计算结果如下,精度上两者没有差别,但由于传输时间与计算时间相互重叠,异步方法的总时间更少。这一结果也证明了,一次性传大批量的数据并不能提升性能,相反可能浪费了可以利用的异步机会。但烦恼的是,到底多大的数据传输才是最佳的仍需要依靠程序员的经验决定。
1 | |
零拷贝
原理
上面提出的优化方案仍需要将数据从主机传输到设备,有没有可能让显卡直接使用主机内的数据,无需传输呢?可以的,这就是零拷贝。
零拷贝能使 GPU 线程直接访问主机内存。而通常,操作系统会使用内存分页机制将内存搞得“乱七八糟”的,因此零拷贝仍然要求使用 pinned 内存,它可将内存页固定住,从而让 GPU 能通过指针映射的方式访问数据。在集显上,映射主机上的 pinned 内存是很简单的事,且总能获得性能增益,因为集显和主机内存在物理上是相同的。只需通过 cudaHostGetDevicePointer() 便可获得映射的指针。
而在独显上,映射 pinned 内存仅在某些情况下是有利的。当数据没有缓存在 GPU 上时,被映射的 pinned 内存只能读取或写入一次,并且读写内存的全局加载和存储应该合并。零拷贝可以用来代替流,因为 kernel-originated 数据传输会自动重叠内核计算,不需要程序员手动设置和确定流的数量。
下面的代码展示了如何使用零拷贝技术:
1 | |
在这段代码中,cudaGetDeviceProperties() 返回结构体中的 canMapHostMemory 字段用于检查设备是否支持将主机内存映射到设备的地址空间。如果可以的话,程序通过调用 cudaSetDeviceFlags(cudaDeviceMapHost) 来启用页锁定内存映射。注意,该函数必须在设置设备或进行 CUDA 调用之前使用(即在创建上下文之前,在本例中,必须在分配内存执行核函数之前)。启用页锁定内存后,系统就知晓设备需要使用主机的内存。此时使用 cudaHostAlloc() 分配主机 pinned 内存,再通过 cudaHostGetDevicePointer() 函数,GPU 就可获得指向主机内存的指针。于是,在上面的代码中,kernel() 可以直接使用指针 a_map 使用主机内存上的数据。
示例
本人使用的显卡是独显,我想试试在这种情况下使用零拷贝会发生什么,核心代码:
1 | |
我们仍在之前的平台上运行示例程序,获得的结果如下。可以看出,使用零拷贝技术所需的时间大大减少,尤其是后续的运行,由于数据已存在于 GPU 缓存中,拷贝执行时间会变得非常少!也就是说,只要主机内存只会被写入一次(不被频繁地更新),那么 pinned 内存页上的数据会被放入缓存中,且不会失效。即使使用独显(显存和主机内存不同),系统也会先将数据放入 GPU 缓存中,只要不在程序运行时被主机频繁更改,那么零拷贝方案也是可行的。
1 | |
统一虚拟地址空间
统一虚拟地址空间(Unified Virtual Address, UVA)将主机物理内存和设备物理内存统一在同一个虚拟地址空间下。因此,无论pinned 内存实际驻留在系统中的何处,所有设备和主机看到的指针值都是一样的。
于是,GPU 内运行的指针可以访问非设备内存空间上的数据,可以认为,在运行时指针对数据在哪个物理内存是无感知的。当然,程序员也可以通过 cudaPointerGetAttributes() 函数来知晓指针指向的物理内存空间。
在 UVA 中,将数据从任何设备的内存空间移出或者移入时,cudaMemcpyKind 参数可以设置为 cudaMemcpyDefault,以让 CUDA 自己根据指针确定数据拷贝方向。这也适用于没有通过 CUDA 分配的主机指针,只要当前设备使用了 UVA 技术。
在 UVA 中,使用 cudaHostAlloc() 分配的 pinned 内存获得的指针在主机和设备上都是一致的且有效的,此时指针可以直接在 CUDA 内核函数使用。然而,通过 cudaHostRegister() 在事后固定的主机内存,就不会有与主机指针相同的设备指针,因此在这种情况下使用 cudaHostGetDevicePointer() 仍然是必要的。
其实,无论是所谓的 pinned 内存还是零拷贝技术,可以说都是通过 UVA 机制实现的。因为 UVA 很强大,只要 pinned 内存按照上文介绍的方式分配,那么无论它们驻留在系统中的何处,所有设备和主机看到的指针值都是一样的。然而,虽然零拷贝技术允许设备代码直接访问主机内存,提供了统一内存的一些便利。但由于它实际上是通过PCIe传输数据的,因此PCIe的低带宽和高延迟拖累了它的性能。
正因为它使用 PCIe 传输数据,所以 UVA 机制也是实现多卡间点对点(P2P)数据传输的必要前提,GPUs 可绕过主机内存,通过 PCIe 总线或NVLink 传输数据。
注意:
UVA 是统一虚拟地址空间,不是 nvidia 在 CUDA 6 时加入的统一内存(UM)机制。统一内存可以在 CUDA runtime 将数据从一个物理位置迁移到另一个物理位置,对程序员透明。由于统一内存能够在主机和设备内存之间的单个页面级别自动迁移数据,因此这其实需要大量工程代码来实现。因为它需要在CUDA运行时,设备驱动程序甚至操作系统内核中提供新功能。
总结
针对内存带宽的优化利用是高性能计算中永恒不变的主题。本博客主要罗列了几个CUDA中常用的针对内存优化的编程技术,主要包括了两方面:其一是使用固定内存来缩短设备获得数据的时间,这主要是通过优化内存地址转换实现的;其二是使用异步方法,这主要通过隐藏数据传输时间实现。当然,对于内存优化的方法不止一种,之后我会再更新其他的优化方法。