CUDA 快速入门
CUDA 快速入门
欢迎来到 CUDA 的世界。本文集中讲述了最基本的 CUDA 知识,供自己以及各位速查。
CUDA 与 GPU 编程
近年来,AI、比特币的发展对计算能力提出了无尽的需求。而在这之前,人们就已经发现,用于渲染、加载图形的 GPU 有着不俗的计算能力,为了能更好地利用 GPU 的计算能力,使得 GPU 不仅仅局限于做图形渲染,NVIDIA 率先推出了可编程的 GPU 芯片以及相应的软件框架:CUDA。让显卡可以用于图像计算以外的目的。
在使用 CUDA 进行编程时,往往需要区分哪些数据在 GPU 上计算,哪些数据在 CPU 上计算,还需要考虑数据之间的迁移、传输和存储等。一般地,用主机一词指代 CPU 及其系统内存,而用设备一词指代 GPU 及其片上、板上内存。很多情况下,CUDA 程序里既包含运行在主机上的程序,又包含运行在设备上的程序,且主机与设备之间存在数据传输,在编程时要格外注意这点。
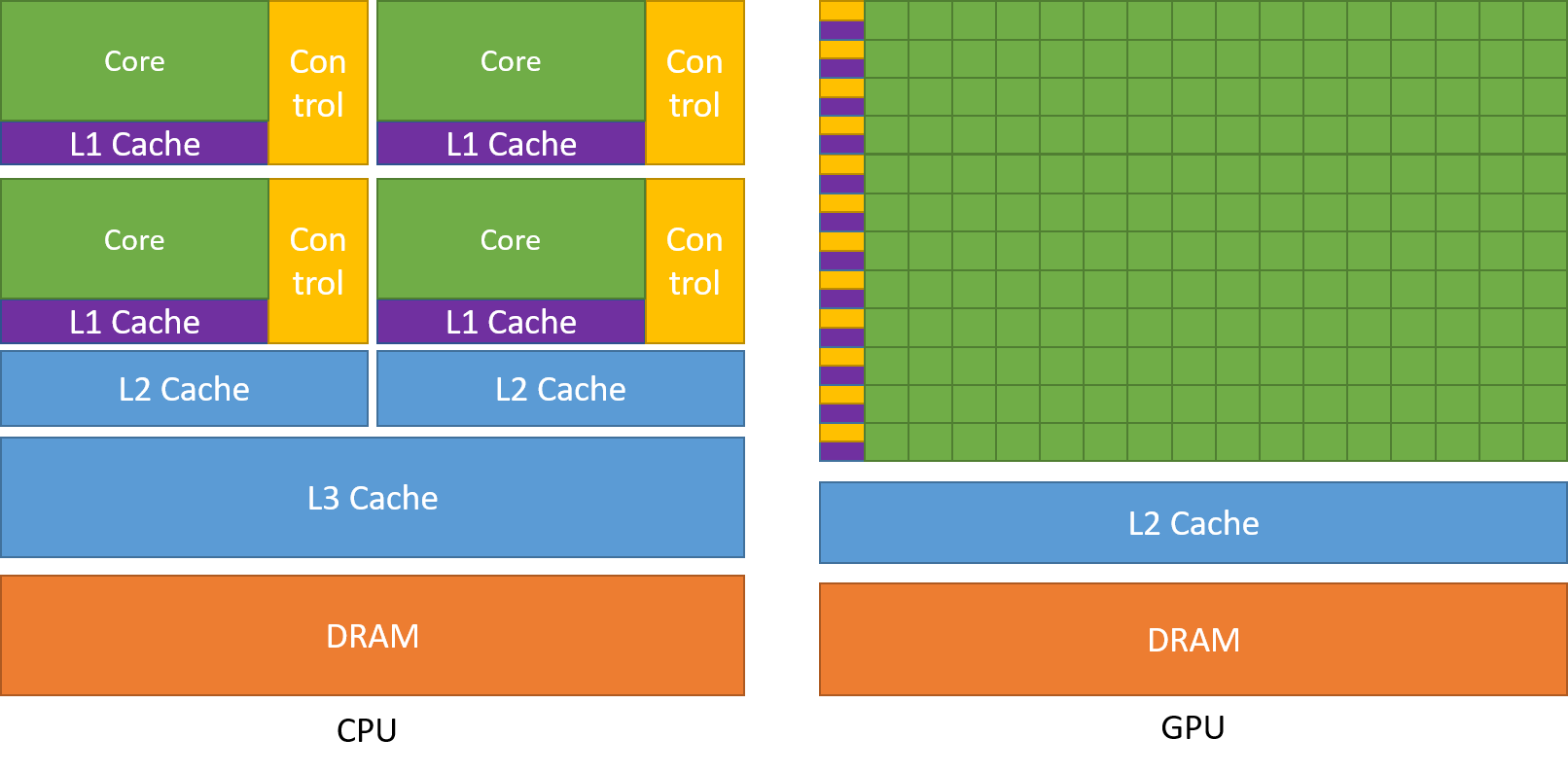
在开始前,先来简单了解 NVIDIA GPU 的并行计算的工作流程,从代码上看,分为两步:
- CPU 调用一种称为核函数的函数,该函数由 GPU 执行。
- GPU 根据给定的并行量,并行执行该函数。
CUDA 中,执行核函数的一个基本单位被称为线程(thread)。若干个 thread 组合成线程块(block),而一次调用中所有的线程块组成了一个网格(grid)。
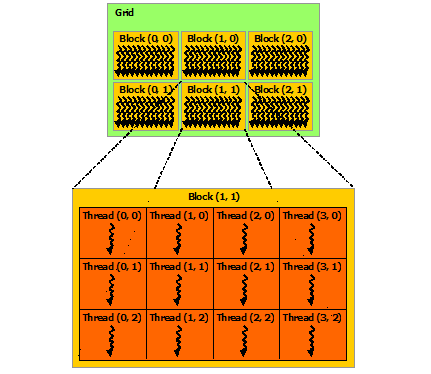
通常,CPU 调用核函数的同时,会指定执行该核函数的线程块数量和每个线程块中线程的数量。这也就意味着,核函数中的内容会被并行地执行线程块的数量 每个线程块内的线程数量次!
核函数
__global__是 CUDA C/C++ 的函数修饰符,表示该函数为核函数- 核函数会在 GPU 上执行,但由主机代码调用
- 返回类型必须为
void - 在调用kernel函数时,函数名后的
<<<b, t>>>:b代表线程块的数目,t代表每个线程块的线程数目。
CUDA 的核函数指的是需要运行在 GPU 上的函数。CUDA C 在标准 C 的基础上,增加了一些修饰符,是为了更好地区分和编译 GPU 程序。我们接触的第一个修饰符就是 __global__。该修饰符告诉编译器:被修饰的函数应当运行在 GPU 上,因此不能使用通用的 C 编译器对其编译,而是要使用 CUDA 提供的编译器(nvcc)。此外,核函数的输入和输出只能通过指针传递,因此返回类型都为 void ,且只能由主机调用。另一个修饰符 __device__ 表示函数在 GPU 上运行,且不能被主机调用,只能由其他 __global__ 修饰的函数调用。相对应地,__host__ 修饰的函数应运行在 CPU 上,每次调用运行一次,且只能被主机调用。该描述符使用较少,因为所有未显式标明函数前置修饰符的函数均默认为主机函数。
调用核函数时,除了传递函数参数外,还需要指定线程块的数量和每个线程块的线程数量,用 <<<>>> 修饰。例如:
1 | |
上例表示有4个线程块,每个线程块有2个线程,参与执行了该核函数。因此会输出8个 Hello world\n。而通过 CUDA 中的内置变量 threadIdx、blockIdx 和 blockDim 等,不仅可以在核函数内区分不同的线程块、线程,也能获得线程块、线程的维度信息,使程序员能更精细地控制线程执行,关于内置变量我会在之后详细介绍。
1 | |
内存管理
内存分配与回收
cudaMalloc分配设备上的内存cudaMemcpy将不同内存段的数据进行拷贝cudaFree释放先前在设备上申请的内存空间
CUDA C 本身十分贴近 C 语言,这对我们学习 CUDA 非常友好。但也有一些需要我们注意的地方,CUDA 对内存资源做了简单的分类。将 CPU 以及系统的内存称为主机内存(host memory),而将 GPU 及其内存称为设备内存(device memory)。它们的空间分配、数据迁移、回收等都需要程序员通过调用 cuda API 函数显式地控制。
在主机内存中分配、回收空间非常简单,使用 C 语言中的 malloc() 和 free() 函数就可以了,但要在设备内存分配空间,以便 GPU 进行计算,就需要用到 CUDA C 提供的函数了。以下两个函数用于分配、回收设备内存空间最为常用:
-
cudaMalloc该函数用来分配设备上的内存,需要被主机调用(即在 CPU 执行的代码中调用)。其返回值为cudaError_t的枚举类型,该类型枚举了所有可能出现错误的情况。而如果函数调用成功,则返回cudaSuccess。第一个参数类型为void **,指向分配后得到的内存首地址。第二个参数类型为size_t,指定了需要分配的内存大小,单位是字节。1
2// 在设备上分配内存
cudaError_t cudaMalloc(void** devPtr, size_t size) -
cudaFree该函数用来释放先前在设备上申请的内存空间,但不能释放通过malloc申请的内存。返回类型仍为cudaError_t。函数参数是指向需要释放的设备内存首地址。1
2// 释放设备上的内存
cudaError_t cudaFree(void* devPtr)
这两个函数与 C 语言中的内存分配、回收函数区别不是很大,由此不难猜到这两个函数的作用。
但容易犯的错误就是,将指向设备内存的指针错误地在主机内存中解引用(dereference),这是不允许的,因为该指针内的值可是设备内存的地址,不是主机内存的地址。
CUDA C 的简单性及其强大的功能在很大程度上都是来源于它淡化了主机代码和设备代码之间的差异。虽然主机代码可以将这个指针作为参数传递,对其执行算术运算,甚至可以将其转换为另一种不同的类型。但是,绝对不可以使用这个指针来读取或者写入内存。因此,程序员一定不能在主机代码中对 cudaMalloc() 返回的指针进行解引用。—— <<GPU高性能编程CUDA实战>>
内存数据传输
完成主机内存与设备内存之间的数据传输,需要使用 cudaMemcpy 函数:
1 | |
其用法与 C 语言中 memcpy 非常相似,想必对熟悉 C 语言的大家没有难度。唯一区别在于多了个参数来指示内存传递的方向。cudaMemcpyKind 指示了数据的传输方向,有以下几种选择:
cudaMemcpyHostToHostcudaMemcpyHostToDevicecudaMemcpyDeviceToHostcudaMemcpyDeviceToDevice
无须更多的解释,相信各位已经知道了上述常量的含义。
错误处理
从前面的例子不难发现,几乎每个CUDA API函数都会返回 cudaError_t 类型的值,用来指示此次函数调用是否成功。当返回值为 cudaSuccess 时,函数调用成功。若失败,返回值会标记失败的具体代码,程序员可通过 cudaGetErrorString 函数获得具体的报错信息。为增强程序的鲁棒性,同时又不失代码美观,方便纠错,我推荐使用如下宏函数:
1 | |
调用 CUDA API 时,就可以用该宏函数将其包裹起来:
1 | |
内置变量与函数
-
线程编号的变量为
threadIdx,类型为uint3,由三个描述不同方向上编号的整数组成,使用x、y、z和w依次访问- threadIdx.x:线程块内在 x 方向上的该线程的 ID
- threadIdx.y:线程块内在 y 方向上的该线程的 ID
-
线程块编号的变量为
blockIdx,类型为uint3- blockIdx.x:网格内在 x 方向上的该线程块的 ID
- blockIdx.y:网格内在 y 方向上的该线程块的 ID
-
线程块的线程数量使用
blockDim变量描述- blockDim.x:该线程块 x 方向上的线程总数
- blockDim.y:该线程块 y 方向上的线程总数
-
网格中线程块的数量使用
gridDim变量描述- gridDim.x:网格中 x 方向上的线程块总数
- gridDim.y:网格中 y 方向上的线程块总数
-
__syncthreads()是 CUDA 的内置命令。通常用于线程块内部的线程同步。当线程执行至__syncthreads()处时,会等待全部的线程执行完毕后再继续执行。
结合前文的 CUDA 线程层次图,可以发现,使用三维向量(二维向量)来描述一个编号,可以极大方便图形变换、模型生成的编程和调试工作。因为在实际编程时,程序员可以将 GPU 的线程网格抽象成一个矩形或立方体,将它循环映射到要计算的资源上,而不再纠结于复杂的索引计算中。
来看一个简单向量加法的例子:
1 | |
如果线程块大小为 256,每个线程块有 256 个线程,GPU 中的线程层级结构如下图:

可见,计算一个线程的唯一全局编号,还是比较复杂的,但也很常用。在这几行代码中,每个线程都得到了它在线程块中的索引以及这个线程块在网格中的索引,并且这两个索引是二维的,要转为一维的,还需要将 y 方向乘以 x 方向的总数。
1 | |
作为对前面知识的巩固,再来看一下部分 main() 函数的书写。主机程序先分配三块用于存贮向量的设备内存,在完成初始化后,将数据移动到设备端。主机调用核函数,并等待 GPU 执行完成,再将数据从设备移动到主机上,最后从中读取计算结果,并回收设备内存。
1 | |
这其中,cudaDeviceSynchronize() 函数会将程序一直阻塞,直到前面所有请求的 GPU 任务全部执行完毕。因为主机在调用了核函数后,往往不会等待设备端任务完成就往下执行了,所以如果不加这一函数,可能会出现结果还未计算完成就被移动到主机的情况。
实践
学完了这些以后,就可以写一些简单的 CUDA 小程序了,动手体验一下 GPU 的计算能力吧!之前我们已经给出了向量加法的部分代码。现在考虑一下数组求和问题。
随机生成一个数组,需要求出该数组所有元素的和。在[之前的文章中](https://dingfen.github.io/Parallel Computing/2020/12/17/PP02.html#%E4%BA%8C%E5%8F%89%E6%A0%91%E6%B1%82%E5%92%8C%E5%AE%9E%E7%8E%B0),介绍过二叉树求和的基本算法。这里可用 CUDA 再实现一次。
略不同于之前文章的求和步骤,为了方便编程,不要求线程必须将相邻数组的元素相加,而是将步长一致的元素相加。在一开始时,规定步长为线程块大小的一半。
每次循环线程计算 v[t] += v[t+n] 的值,也就是将步长一致的累加起来。循环一次后,数组元素的部分和就出现在数组的前半部分。然后将步长缩小一半,那么下一次循环会将部分和集中到数组前半部分。如此往复,直到数组的和集中到了第0号元素上。
1 | |
注意循环中的 __syncthreads(),该句保证了上一循环全部结束后,下一轮循环才会开始。否则,线程之间步调不统一会得出错误的结果。很明显看出,算法每经过一轮循环,可执行的线程就会少一半,这显然浪费了不少计算资源。
随后就是主机部分的代码。同样的步骤,先分配设备内存,然后将数据喂给设备,随后调用核函数计算,最后将计算结果返回,并回收内存。
1 | |