矩阵乘中很多计算步骤都十分相似且数据依赖不复杂,所以特别适合使用 GPU 来计算, 利用 GPU 内部的高度并行性,可极大地提高计算速度。使用 CUDA 完成矩阵乘法是一件非常有意义也有难度的事情。本篇博客从最简单最原始的实现出发,一步步地针对 CUDA 核函数进行优化,探讨 CUDA 矩阵乘中的优化与实现细节,并尝试总结出一般性原则,最后,我们粗略介绍了 cutlass 的矩阵乘步骤。
矩阵乘法 CPU 实现
先看看在 CPU 下如何实现矩阵乘法,如我们在线性代数课上学的计算方式一样,代码逻辑非常简单,直接给出如下:
1 2 3 4 5 6 7 8 9 10 11
voidmatMulCpu(float* c, float* a, float* b, int m, int n, int k){ for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { float sum = 0.0f; for (int l = 0; l < k; l++) { sum += a[i * k + l] * b[l * n + j]; } c[i * n + j] = sum; } } }
对于矩阵 Am×k⋅Bk×n=Cm×n 而言:
计算次数为 m×n×k
时间复杂度为 O(n3)
性能数据:
CUDA 的核函数实现 —— naive 版本
实现原理
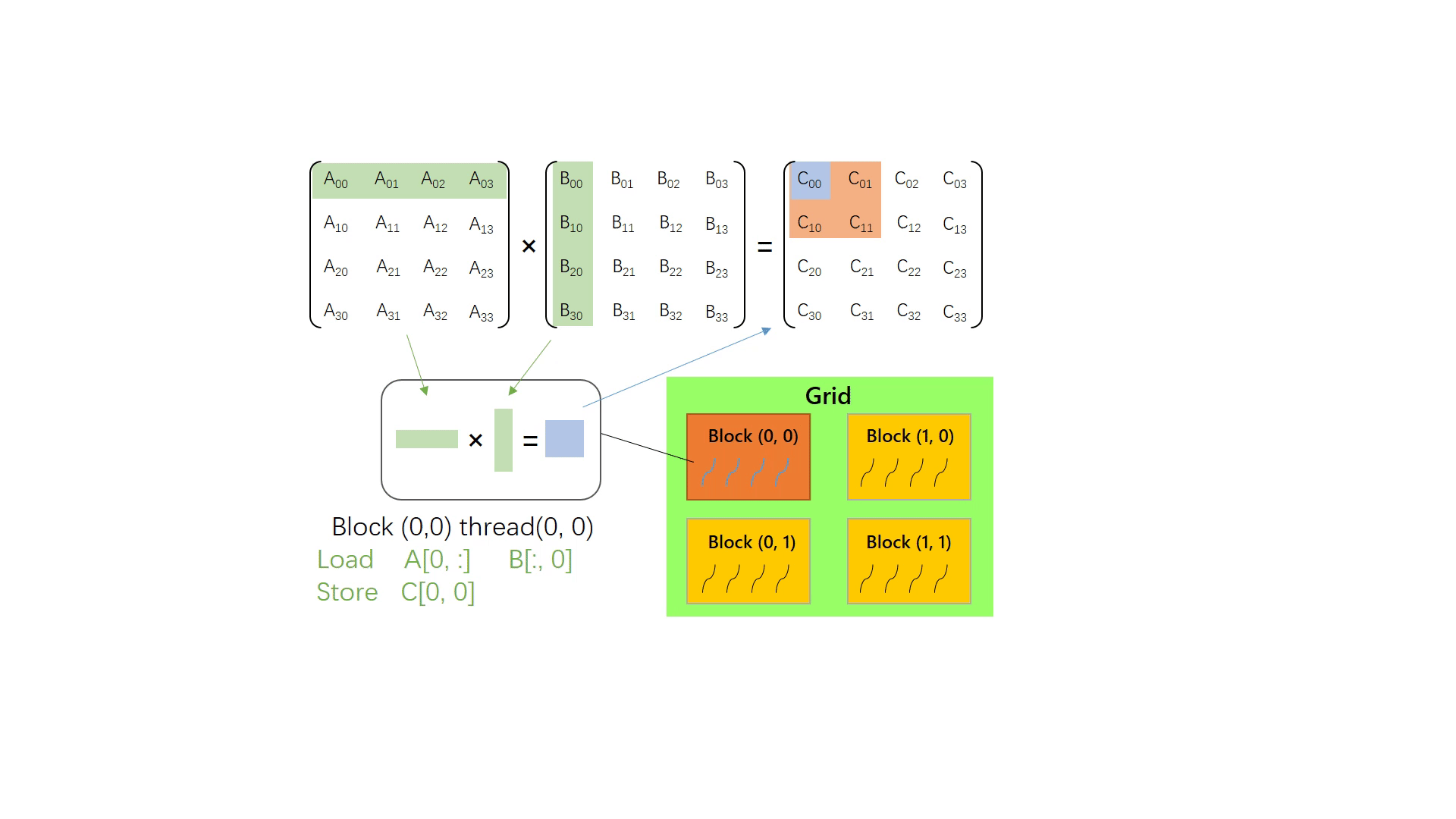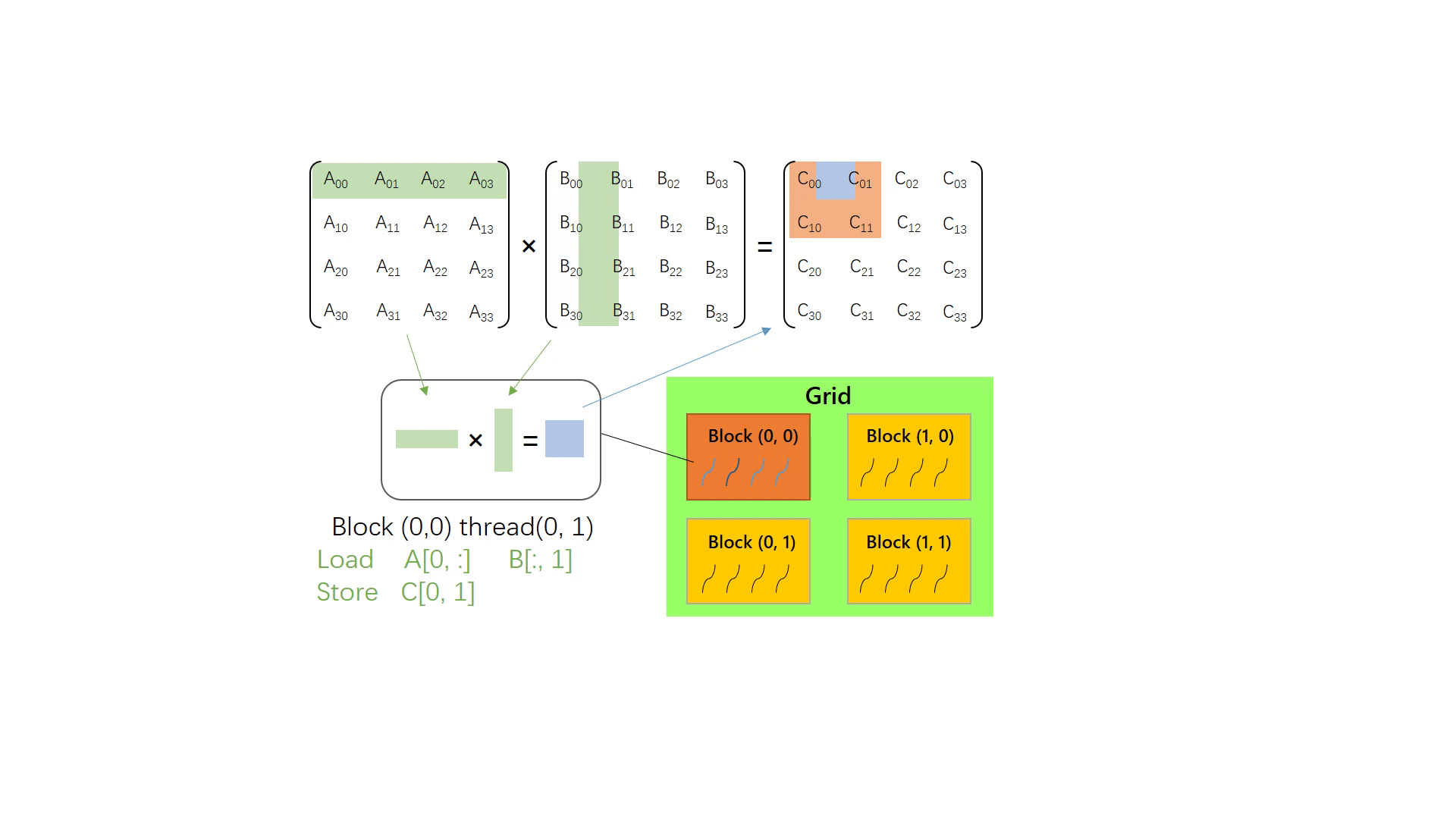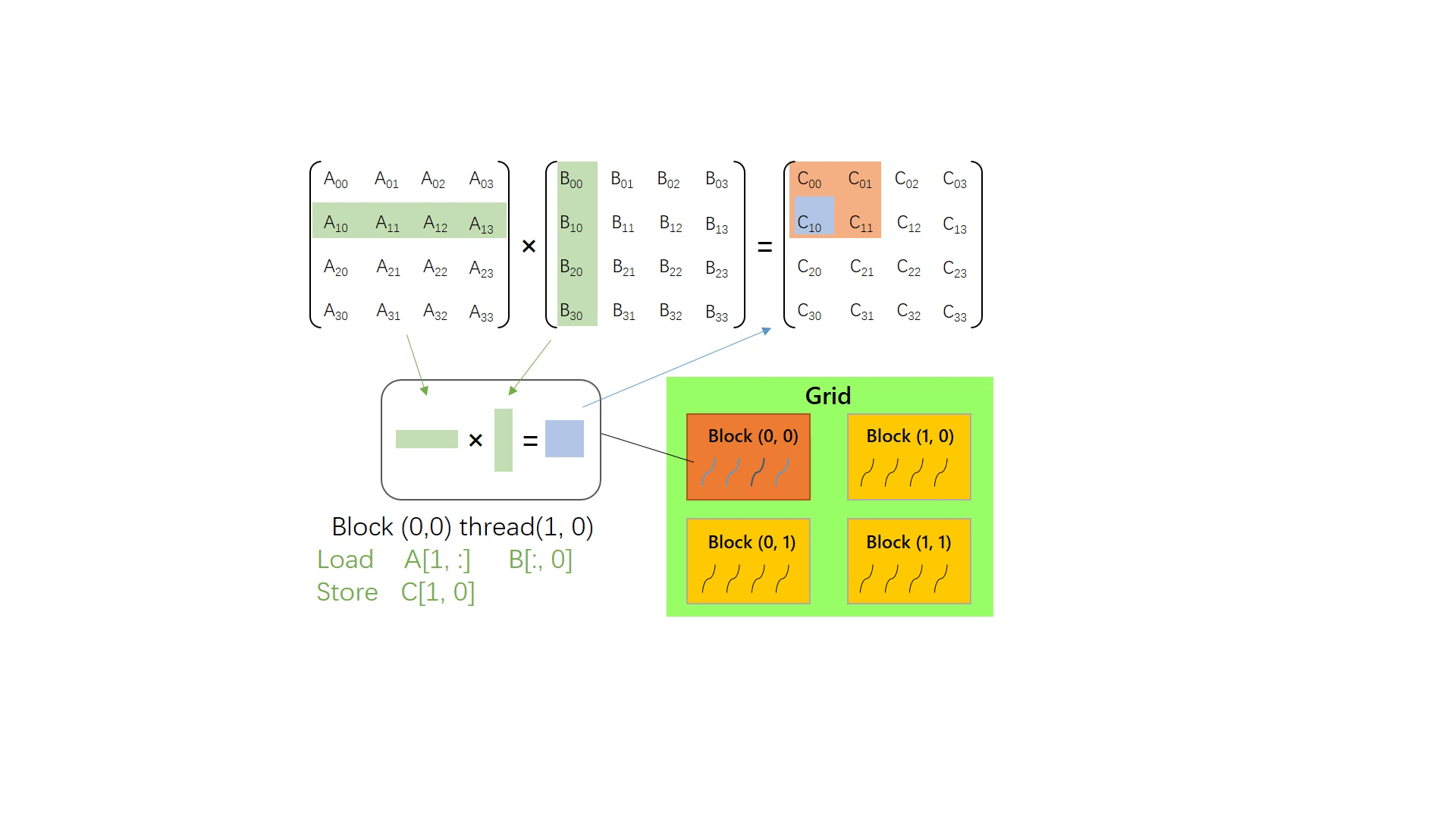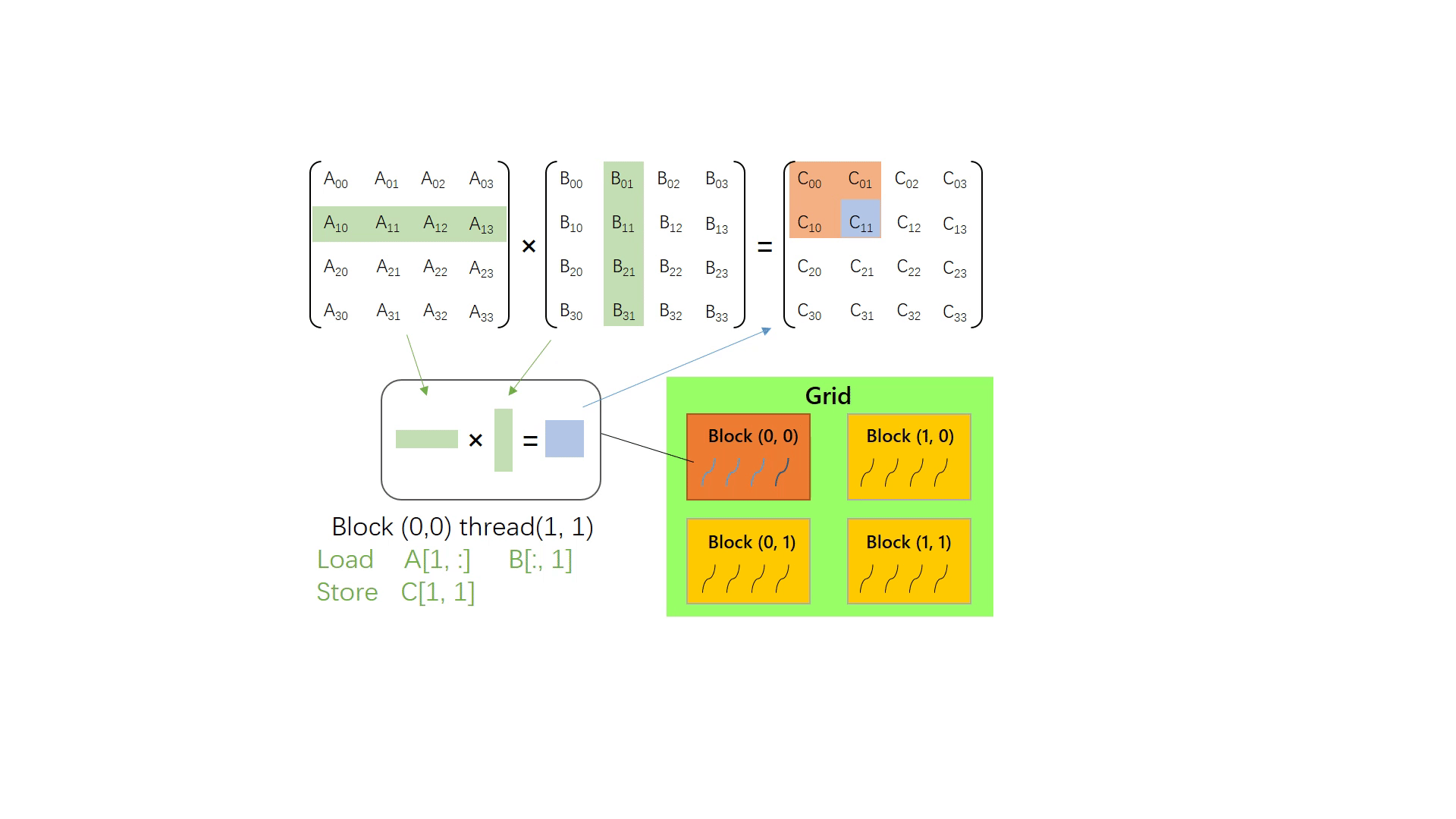
仍然计算矩阵 Am×k⋅Bk×n=Cm×n。但这次使用 GPU 计算。不难想到,可以安排 m×n 个线程,从 x 方向(行方向)看有m组线程,每组处理一行矩阵计算;从 y 方向(列方向)看有 n 组线程,每组处理 m 个线程。每个线程读取 A 中的第 m 行和 B 中的第 n 列,进而计算出 C[m, n],替换掉 CPU 实现版本中的两层外循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// cuda kernel function __global__ voidmatMulNaiveGpu(float* c, float* a, float* b, int m, int n, int k){ int y = blockIdx.y * blockDim.y + threadIdx.y; int x = blockIdx.x * blockDim.x + threadIdx.x; float v = 0.0f; for(int i =0; i < k; i++) { v += a[y * k + i] * b[i * n + x]; } c[y * n + x] = v; }
// call in host // suppose A[m, k] B[k, n] C[m, n] dim3 grid_size = dim3((m + block.x - 1) / block.x, (n + block.y - 1) / block.y, 1); matMulNaiveGpu<<<grid_size, threadsPerBlock>>>(c, a, b, m, n, k);
下图演示了上面的矩阵乘中,每个线程负责读取和计算的单个矩阵C的元素:
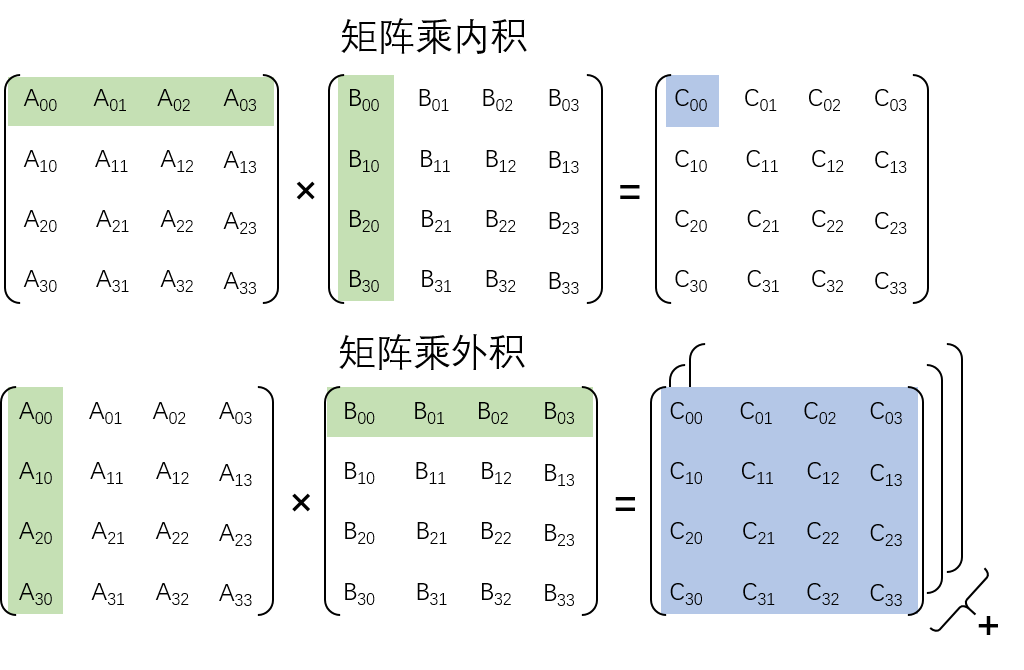
这里容我再介绍此程序的另一个实现思路,当然也是为了呼应下文。不妨设想,矩阵乘也可以如此实现,将 A 矩阵的每一列看做一个列向量,将 B 矩阵的每一行看做一个行向量,两者相乘,得到 C 矩阵的一部分,再累加起来,也能完成矩阵乘运算:
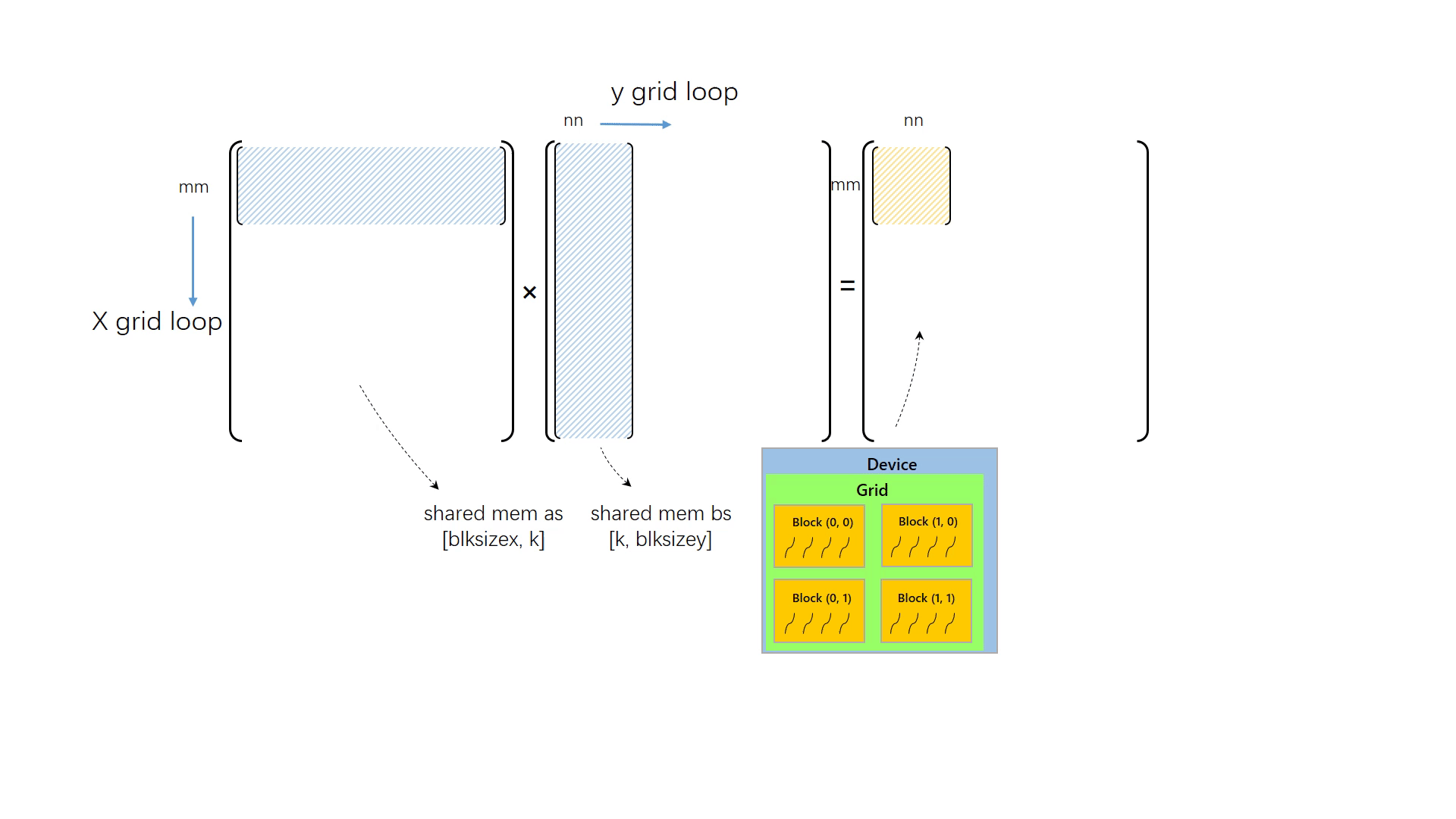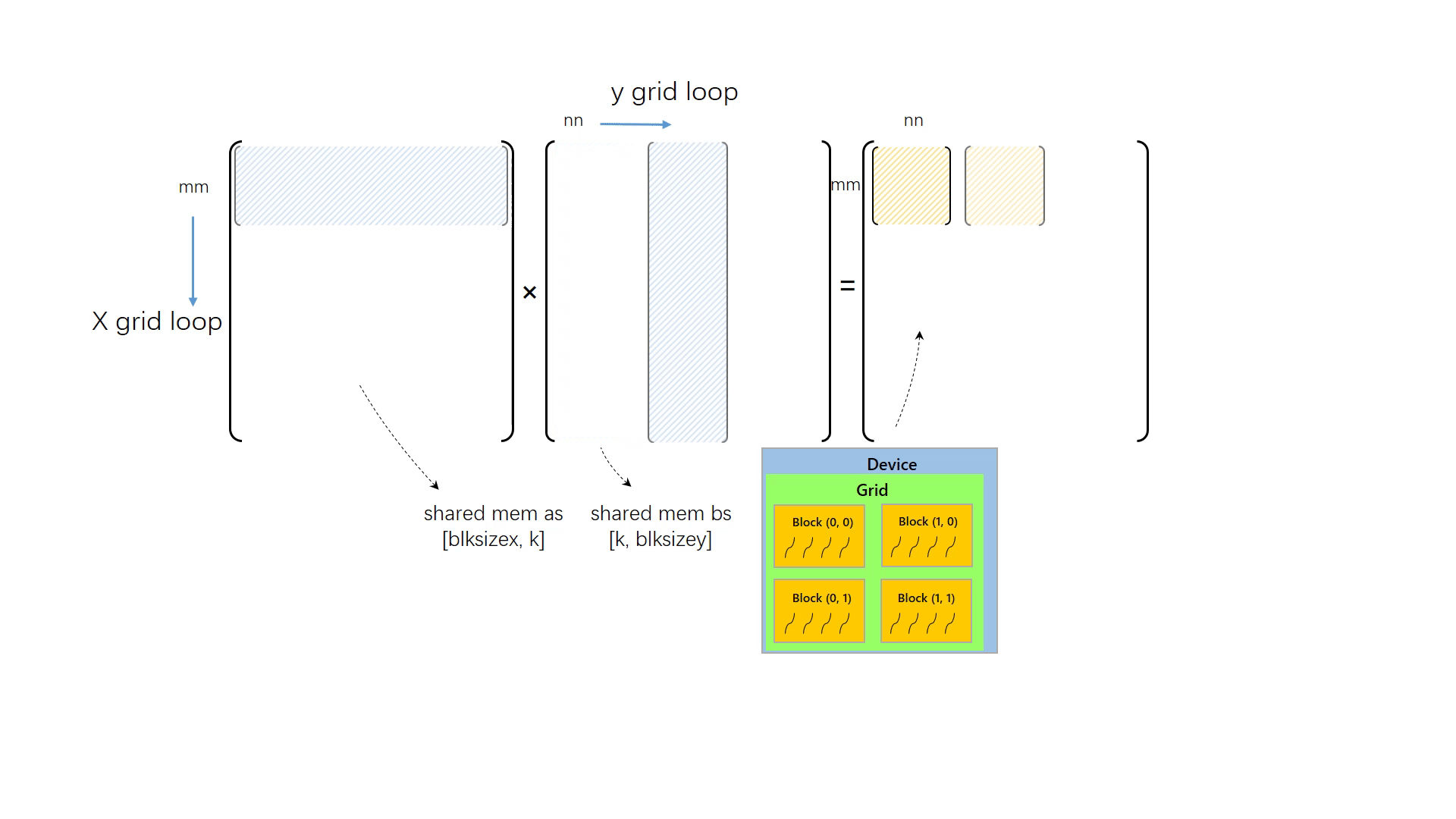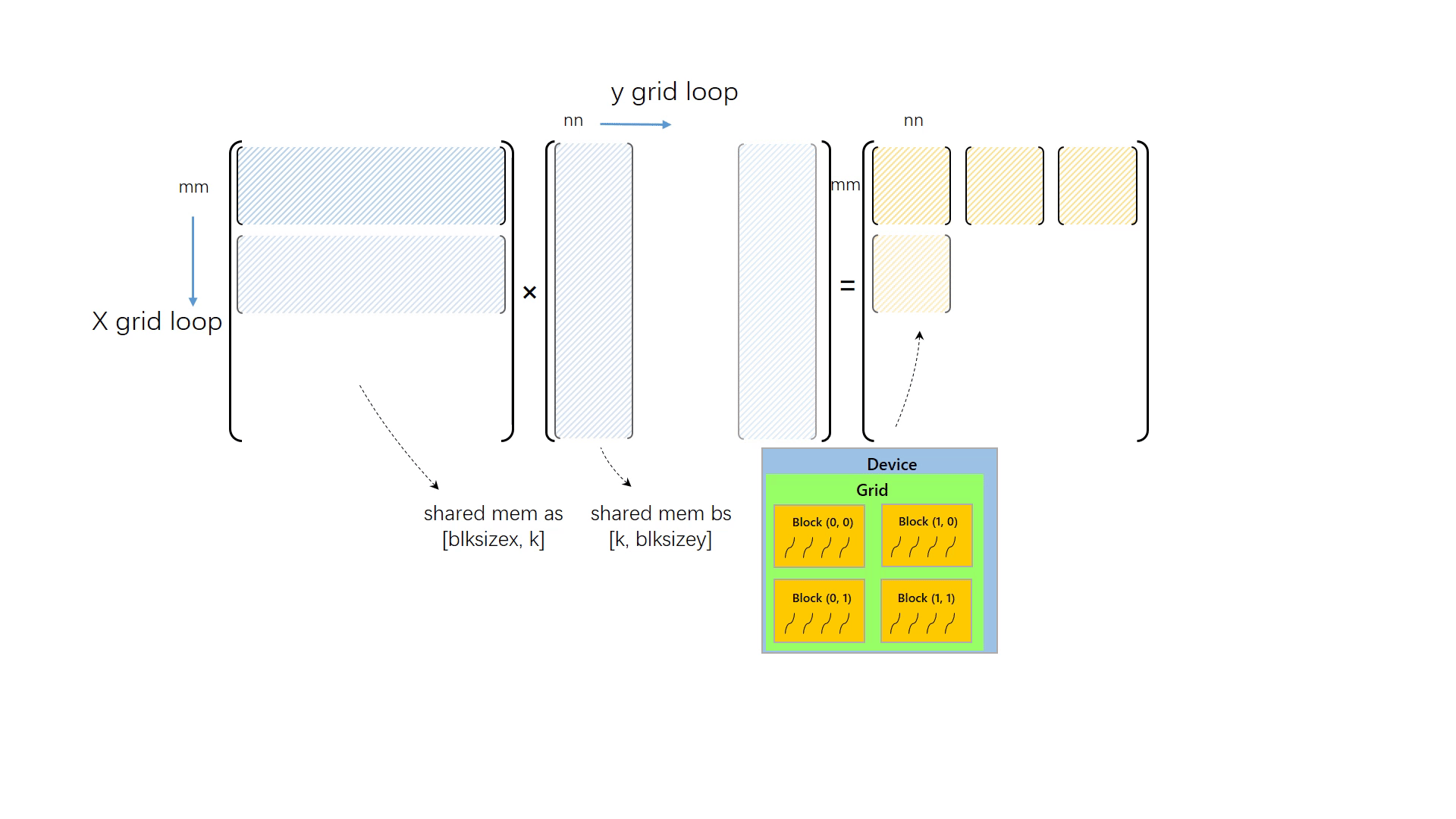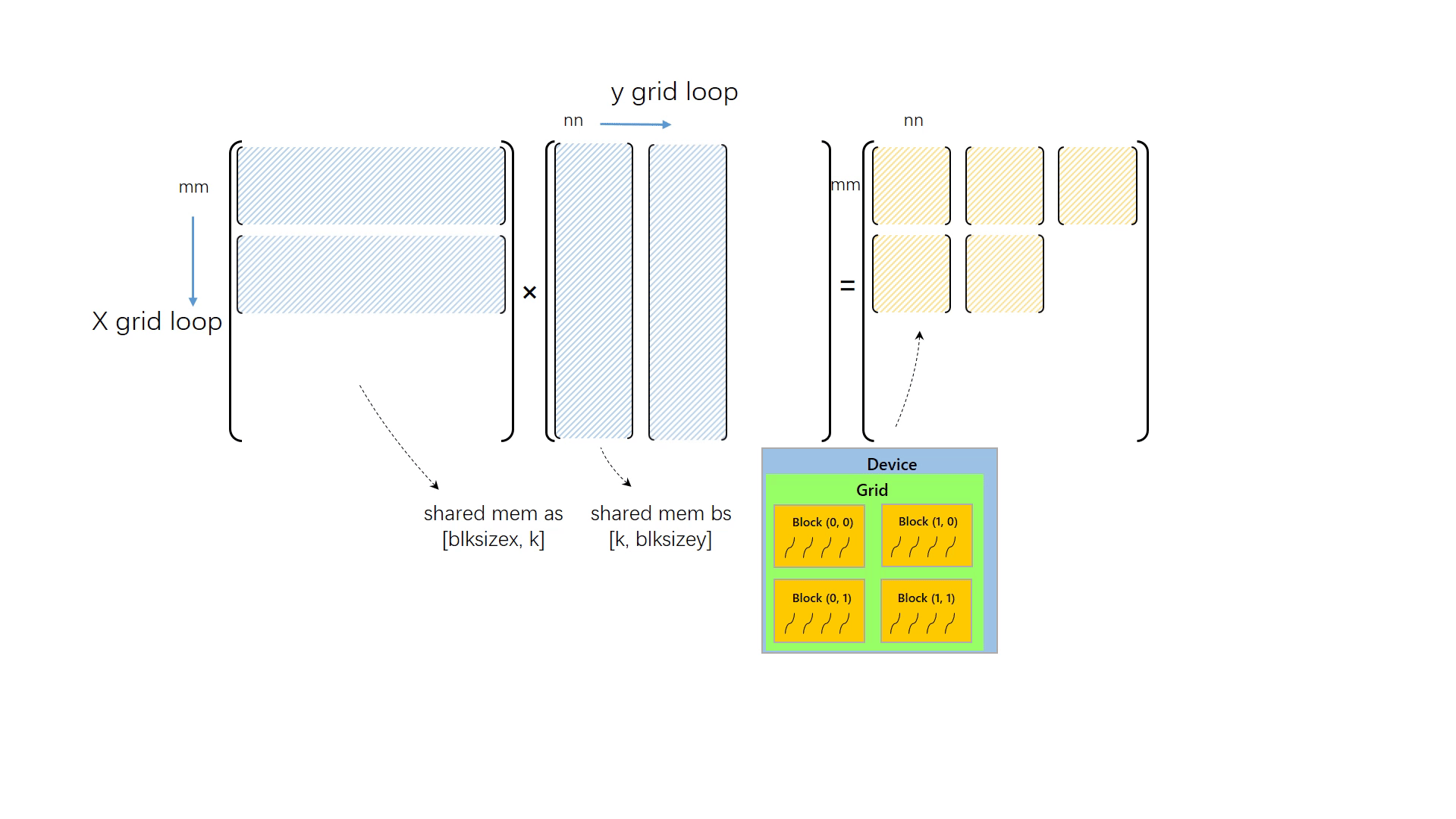
要想让程序能处理任何大小的矩阵乘,并让grid大小与矩阵大小解耦合,一定要使用循环对矩阵进行切分,再对切分后的小矩阵执行矩阵乘计算。与之前一样,我们还是让每个线程读取 A 中的第 m 行和 B 中的第 n 列,进而计算出 C[m, n],但不同的是,这次 grid 大小不再于矩阵大小相关,我们假设矩阵的大小远超设备所能支持的最大线程数,因此我们不得不将矩阵切分为各个小块,分别执行计算。
我们从 naive 的 GPU 矩阵乘实现出发,一步一步地将下面的程序改造成循环分块的样子。
1 2 3 4 5 6 7 8 9 10
// cuda kernel function __global__ voidmatMulNaiveGpu(float* c, float* a, float* b, int m, int n, int k){ int y = blockIdx.y * blockDim.y + threadIdx.y; int x = blockIdx.x * blockDim.x + threadIdx.x; float v = 0.0f; for(int i =0; i < k; i++) { v += a[y * k + i] * b[i * n + x]; } c[y * n + x] = v; }
由于矩阵很大,x 方向与 y 方向矩阵元素数量都多于线程数量,因此需要对矩阵做二维切分。切分的块数取决于矩阵大小和线程数量
1 2 3 4
int thread_num_x = gridDim.x * blockDim.x; int thread_num_y = gridDim.y * blockDim.y; int x_grid_loop = (m + thread_num_x - 1) / thread_num_x; int y_grid_loop = (n + thread_num_y - 1) / thread_num_y;
x_grid_loop 表示 x 方向有多少个被切分的小矩阵,同理于 y_grid_loop。
然后是内循环的改动,内循环中正确计算矩阵乘的关键是取对元素。先前的内循环没有考虑矩阵的分块。现在,我们把被切分的小矩阵的标号也考虑进去,因为一个小矩阵的大小是 thread_num_x x thread_num_y,若考虑一个第 mm 行,第 nn 列的小矩阵,其左上角的元素坐标就是 mm * thread_num_x,nn * thread_num_y。将其加入到原先的坐标变量中,即可得到正确的元素。
1 2
int x = mm * thread_num_x + blockIdx.x * blockDim.x + threadIdx.x; int y = nn * thread_num_y + blockIdx.y * blockDim.y + threadIdx.y;
最后将上面的改动整合起来,套上两层矩阵分块的循环,完成 matmul_tile2d_gpu:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
__global__ voidmatmul_tile2d_gpu(float* c, float* a, float* b, int m, int n, int k){ int thread_num_x = gridDim.x * blockDim.x; int thread_num_y = gridDim.y * blockDim.y; int x_grid_loop = (m + thread_num_x - 1) / thread_num_x; int y_grid_loop = (n + thread_num_y - 1) / thread_num_y; for (int mm = 0; mm < x_grid_loop; mm++) { for(int nn = 0; nn < y_grid_loop; nn++) { int x = mm * thread_num_x + blockIdx.x * blockDim.x + threadIdx.x; int y = nn * thread_num_y + blockIdx.y * blockDim.y + threadIdx.y; float v = 0.0f; for(int i = 0; i < k; i++) { v += a[x * k + i] * b[i * n + y]; } c[x * n + y] = v; } } }
类似于 CPU 中的高速缓存,CUDA 中也使用内存层次结构(memory hierarchy)来保证访问内存的速度。大多 GPU 中都存在容量较小的共享内存,它们位于芯片内部,访问延时是全局内存的二十到三十分之一,带宽却高了 10 倍。对应到物理层面,每个 SM 都有一个小的片上内存,被 SM 上执行的线程块中的所有线程所共享。共享内存使同一个线程块中可以相互协同,便于片上的内存可以被最大化的利用,降低回到全局内存读取的延迟。
template <int BLOCK_SIZE_X, int BLOCK_SIZE_Y, int K> __global__ voidmatmul_tile2d_shared_gpu(float* c, float* a, float* b, int m, int n, int k){ int thread_num_x = gridDim.x * blockDim.x; int thread_num_y = gridDim.y * blockDim.y; int tidy = threadIdx.y; int tidx = threadIdx.x; int x_grid_loop = (m + thread_num_x - 1) / thread_num_x; int y_grid_loop = (n + thread_num_y - 1) / thread_num_y; __shared__ float as[BLOCK_SIZE_X][K]; __shared__ float bs[K][BLOCK_SIZE_Y]; assert(x_grid_loop == y_grid_loop); for (int mm = 0; mm < x_grid_loop; mm++) { for(int nn = 0; nn < y_grid_loop; nn++) { int x = mm * thread_num_x + blockIdx.x * blockDim.x + threadIdx.x; int y = nn * thread_num_y + blockIdx.y * blockDim.y + threadIdx.y; // load data from global memory to shared memory for (int i = 0; i < k; i++) { as[tidx][i] = a[x * k + i]; bs[i][tidy] = b[i * n + y]; } // sub-matrix multiply float v = 0.0f; for(int i = 0; i < k; i++) { v += as[tidx][i] * bs[i][tidy]; } // store results into global memory c[x * n + y] = v; } } }
分析与性能数据
注意到,虽然我们将矩阵C的计算过程进行了分块,但我们的共享内存中仍存放了至少一整行的矩阵 A 和一整列的矩阵 B。这很容易导致 GPU 的共享内存溢出。也就是说,我们的矩阵分块方法还有待改进。
那么我们花这些篇幅来说明矩阵乘内积和矩阵乘外积,目的为何?其实很简单,在遇到大矩阵相乘时,我们往往会使用矩阵外积完成矩阵乘法,因为矩阵乘外积只需要加载一遍矩阵就行了,减轻了内存带宽的压力。我们指出,当它要处理大矩阵乘(尤其 k 过大时),切分出来的子矩阵无法放入到共享内存中,需要 split k 方向,增加了程序的复杂度,因此这次我们选择用更简单的矩阵乘外积来实现核函数。
也许会有这样的疑问:使用矩阵乘外积也会遇到 m 和 n 过大时,无法放入共享内存的问题,为何说矩阵乘外积实现要简单?因为矩阵乘内积的 split K 方向是在线程块内做的切分,实现起来比较复杂;而矩阵乘外积对 m 和 n 的切分是在线程块间和网格间做的,实现相对简单。
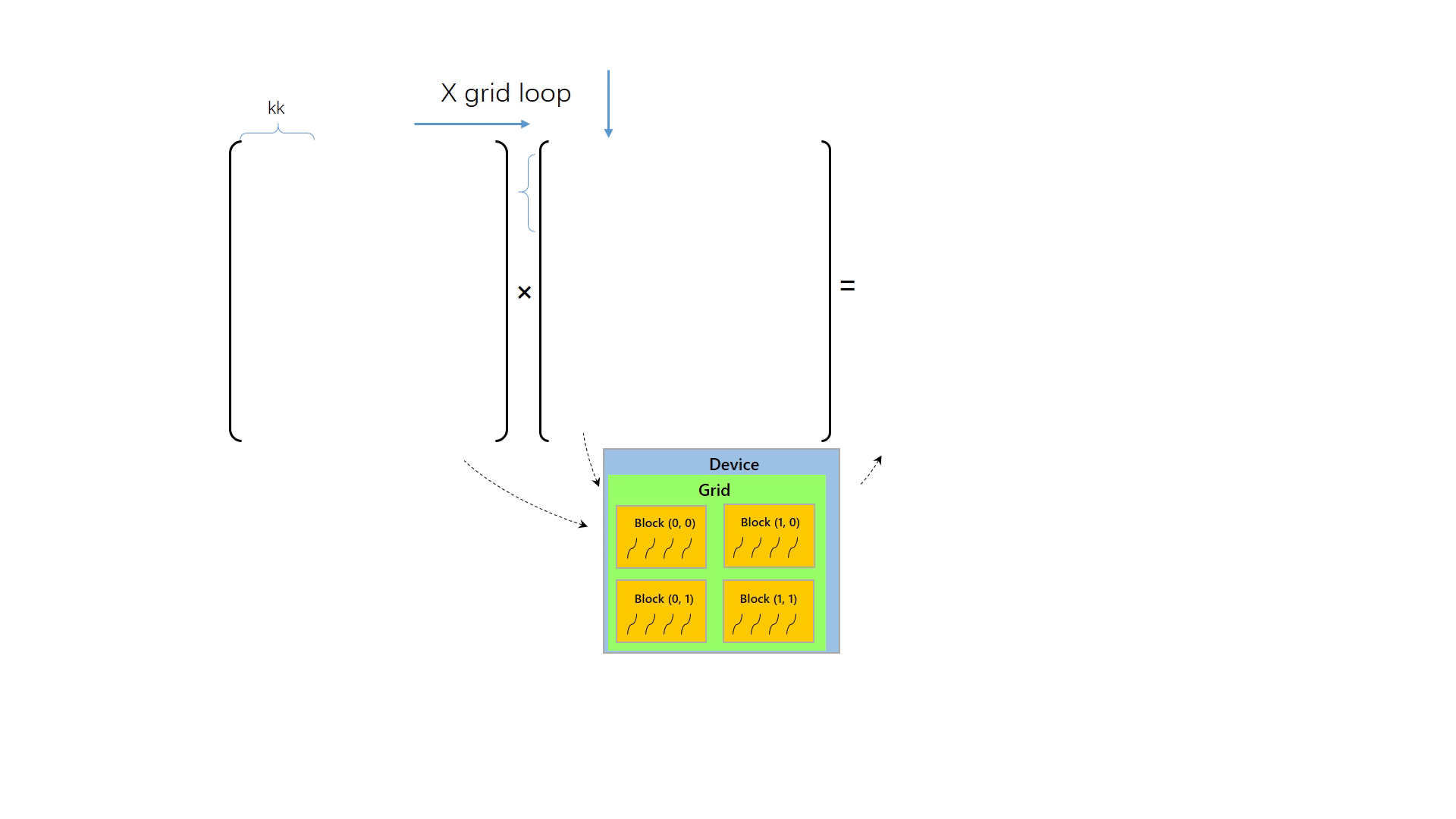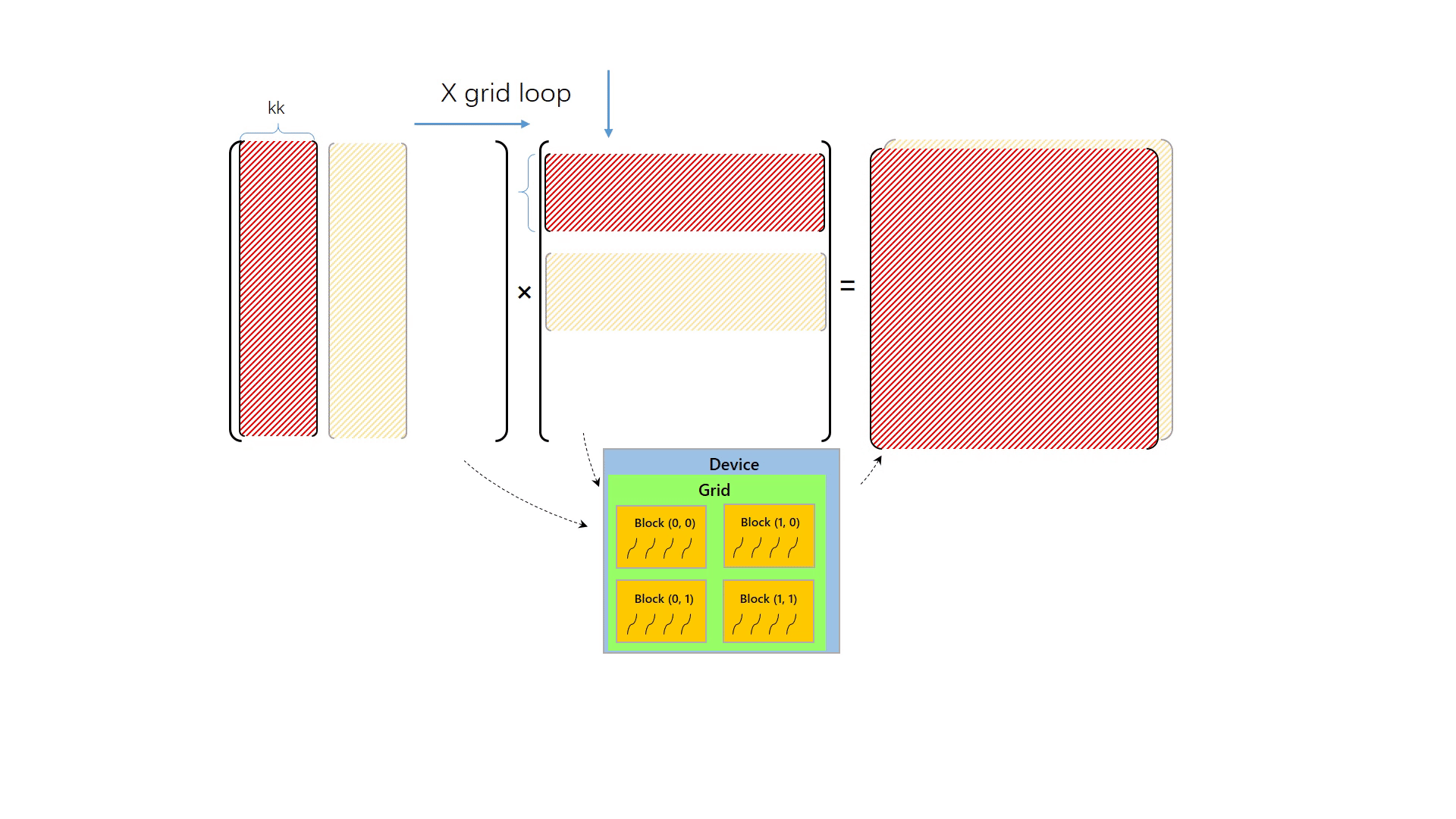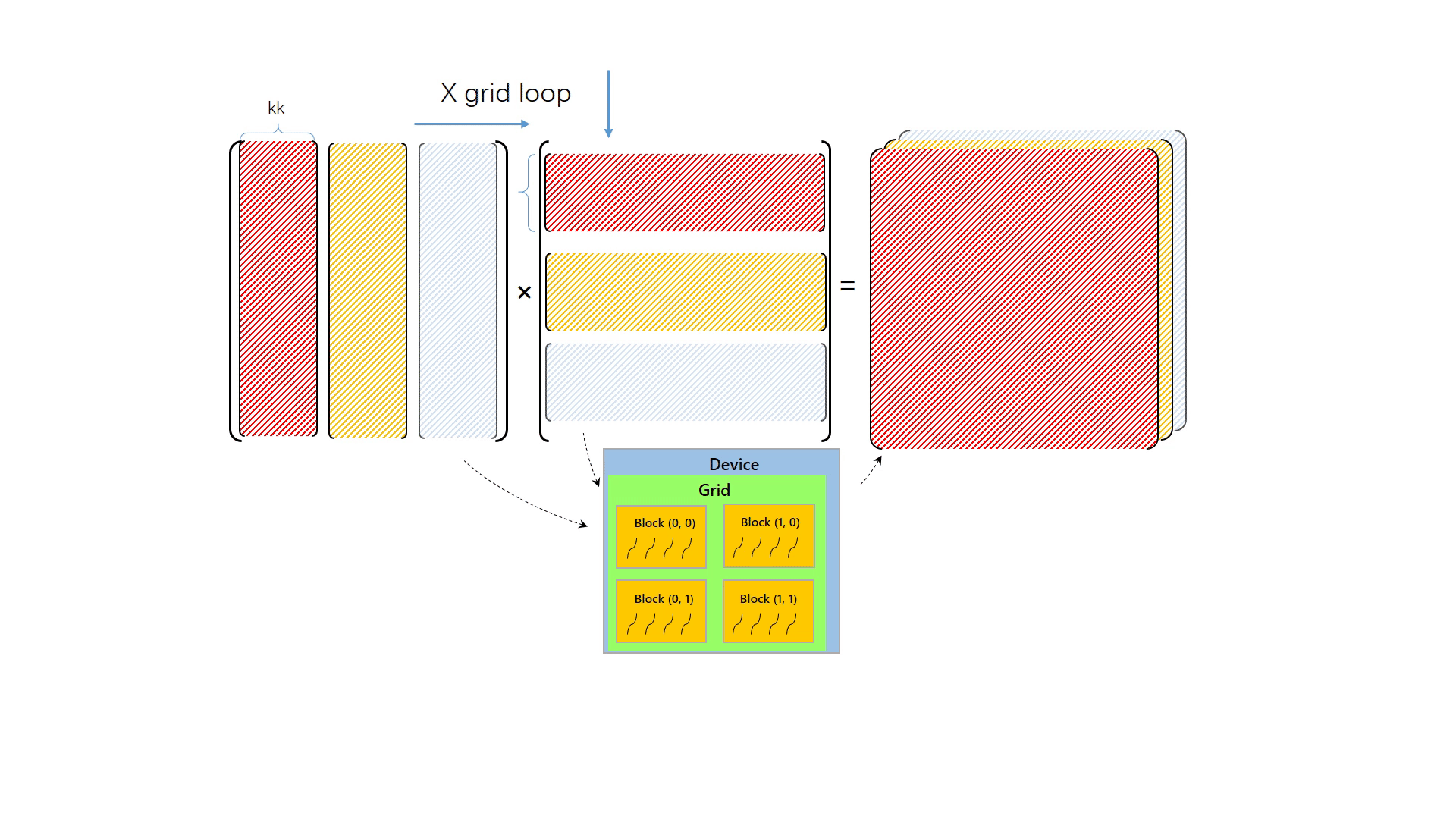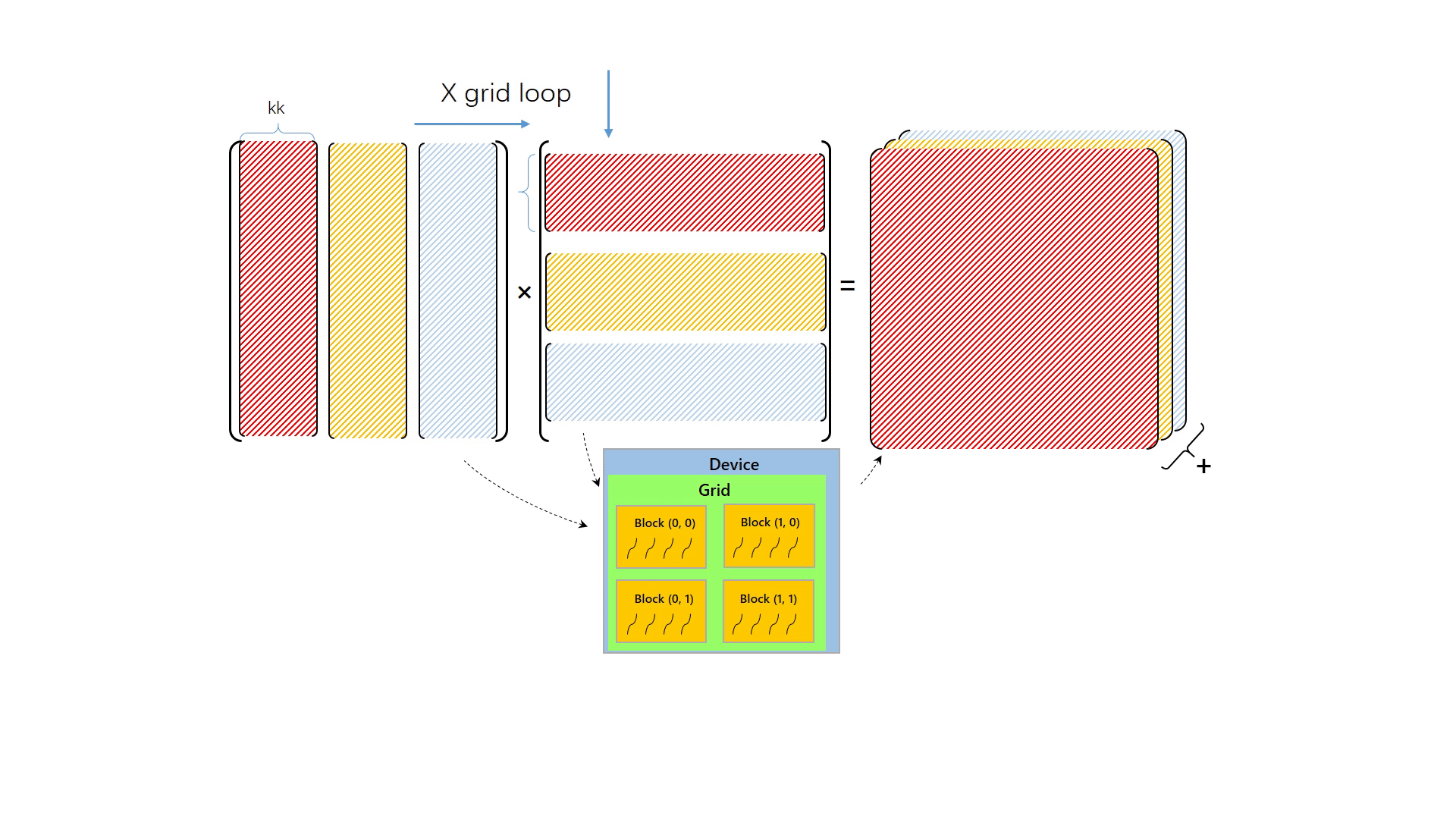
为更好地说明切分和计算过程,简化问题,我们先假定 grid 的大小能覆盖整个矩阵。将矩阵按照下动图的方式切分,那么每个小块的厚度就是线程块中 x 或 y 方向的线程数量。程序仅有一层循环,循环次数就是 (k + BLOCK_SIZE - 1) / BLOCK_SIZE。
第一次循环,处理红色的数据块的矩阵乘,与矩阵乘内积不同,这次计算出来的结果维度是(m,n)。循环中,grid 内的线程块按照编号,将对应的矩阵元素放入到自己内部的共享内存中,于是第一次循环时,grid 读取了矩阵 A 的一列和矩阵 B 的一行,于是可以计算出矩阵 C 的部分和。
第二次循环,将往右移动读取矩阵 A 的一列,往下移动读取矩阵 B 的一行,那么橙色的数据块会被读入共享内存中,再计算矩阵 C 的部分和
不断循环累加,就可以计算出矩阵 C。
容易得出,对于第 i 次循环,需要加载到共享内存的数据是
1 2 3 4 5 6
int y = blockIdx.y * blockDim.y + threadIdx.y; int x = blockIdx.x * blockDim.x + threadIdx.x; int tidy = threadIdx.y; int tidx = threadIdx.x; as[tidx][tidy] = a[x][tidy + i * BLOCK_SIZE]; bs[tidx][tidy] = b[tidx + i * BLOCK_SIZE][y];
来看看 CUDA 的实现。线程块读取数据到共享内存后,需要加上 __syncthreads() 语句,确保所有线程已经读取完成,再开始下面的计算,同样也要加上 __syncthreads() 来保证所有线程都已经完成。
template<int BLOCK_SIZE> __global__ voidmatmul_outer_product_gpu(float* c, float* a, float* b, int m, int n, int k){ int y = blockIdx.y * blockDim.y + threadIdx.y; int x = blockIdx.x * blockDim.x + threadIdx.x; int tidy = threadIdx.y; int tidx = threadIdx.x; float v = 0.0f; __shared__ float as[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float bs[BLOCK_SIZE][BLOCK_SIZE];
int tilesx = (k + BLOCK_SIZE - 1) / BLOCK_SIZE; for(int i = 0; i < tilesx; i++) { // load data from global memory to shared memory as[tidx][tidy] = a[x * k + i * BLOCK_SIZE + tidy]; bs[tidx][tidy] = b[(i * BLOCK_SIZE + tidx) * n + y]; // sync to wait for all threads in one block to finish loading datas __syncthreads(); // sub-matrix multiply for(int l = 0; l < BLOCK_SIZE; l++) { v += as[tidx][l] * bs[l][tidy]; } // sync to wait for all threads in one block to finish compute __syncthreads(); } // store results into global memory c[x * n + y] = v; }
更大的矩阵相乘——内积与外积的合用
若 grid 的大小无法覆盖整个矩阵,我们就需要再用双重循环来切分过大的 m 和 n。
聪明的读者可能已经想到,切分过大的 m 和 n 已经在 matmul_tile2d_gpu 矩阵乘内积做过了。的确,我们又可以使用矩阵乘内积的方法将矩阵沿两个方向切分,如下图。但这回,每个小条状的矩阵乘其实是由 matmul_outer_product_gpu 矩阵乘外积计算得到的。也就是说,面对这样的大矩阵,我们选择使用矩阵乘内积 + 矩阵乘外积的组合方式完成矩阵乘计算。
template<int BLOCK_SIZE> __global__ voidmatmul_outer_product_tile2d_gpu(float* c, float* a, float* b, int m, int n, int k){ int tidy = threadIdx.y; int tidx = threadIdx.x; int thread_num_x = gridDim.x * blockDim.x; int thread_num_y = gridDim.y * blockDim.y; int x_grid_loop = (m + thread_num_x - 1) / thread_num_x; int y_grid_loop = (n + thread_num_y - 1) / thread_num_y; for(int mm = 0; mm < x_grid_loop; mm++) { for (int nn = 0; nn < y_grid_loop; nn++) { int y = nn * thread_num_y + blockIdx.y * blockDim.y + threadIdx.y; int x = mm * thread_num_x + blockIdx.x * blockDim.x + threadIdx.x; float v = 0.0f; /** * matrix outer product * matmul_outer_product_gpu() part */ } } }
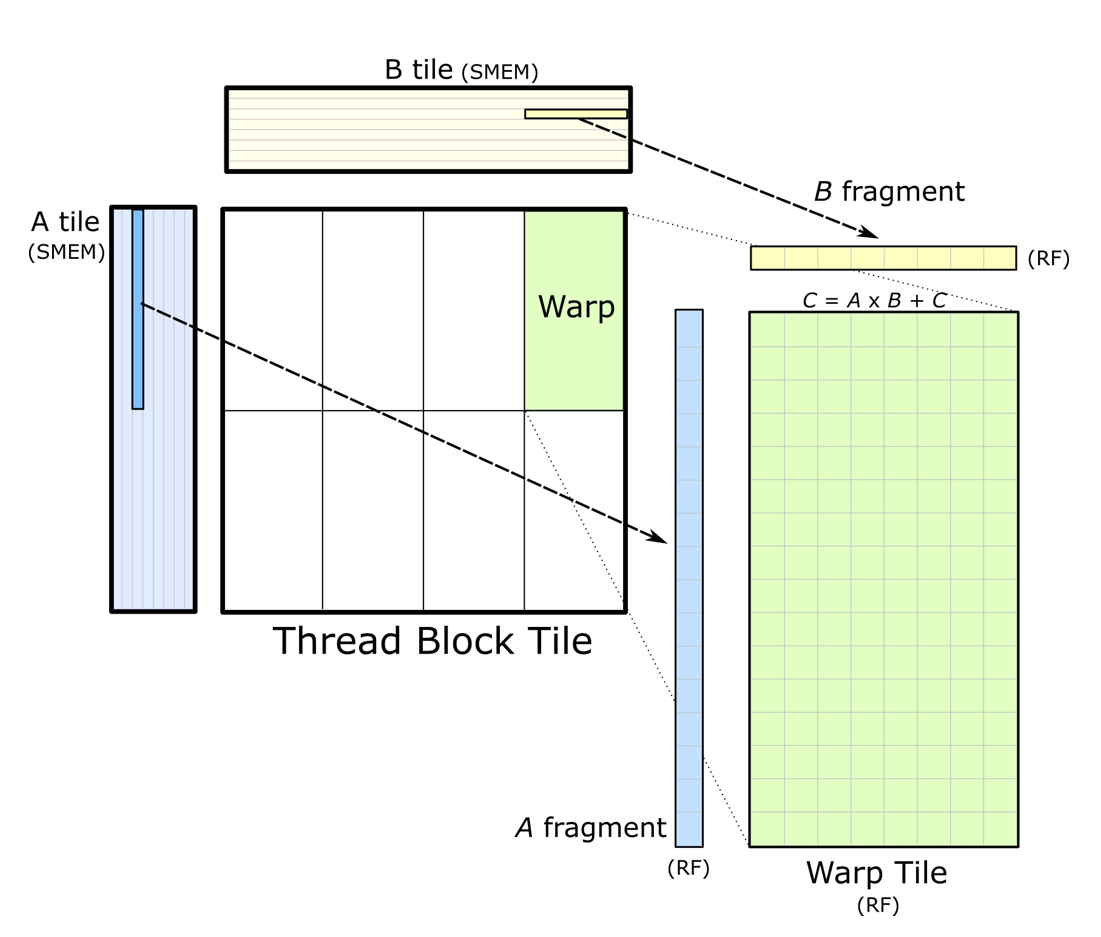
现在我们来看一下 cutlass (CUDA Templates for Linear Algebra Subroutines),它是一个基于 CUDA C++ 模板实现的 gemm CUDA kernel 开源库,它分别实现了各个层级和尺度的高性能 GEMM kernel,现被广泛用于各个大模型的底层计算中。我们来看看它是如何将矩阵一步步分割计算的:
为了能充分压榨 GPU 的计算资源,cutlass 引入了一个设计精巧的 gemm 复杂层次结构,这个层次结构精确地与 CUDA 编程模型 相配,如图上图所示。
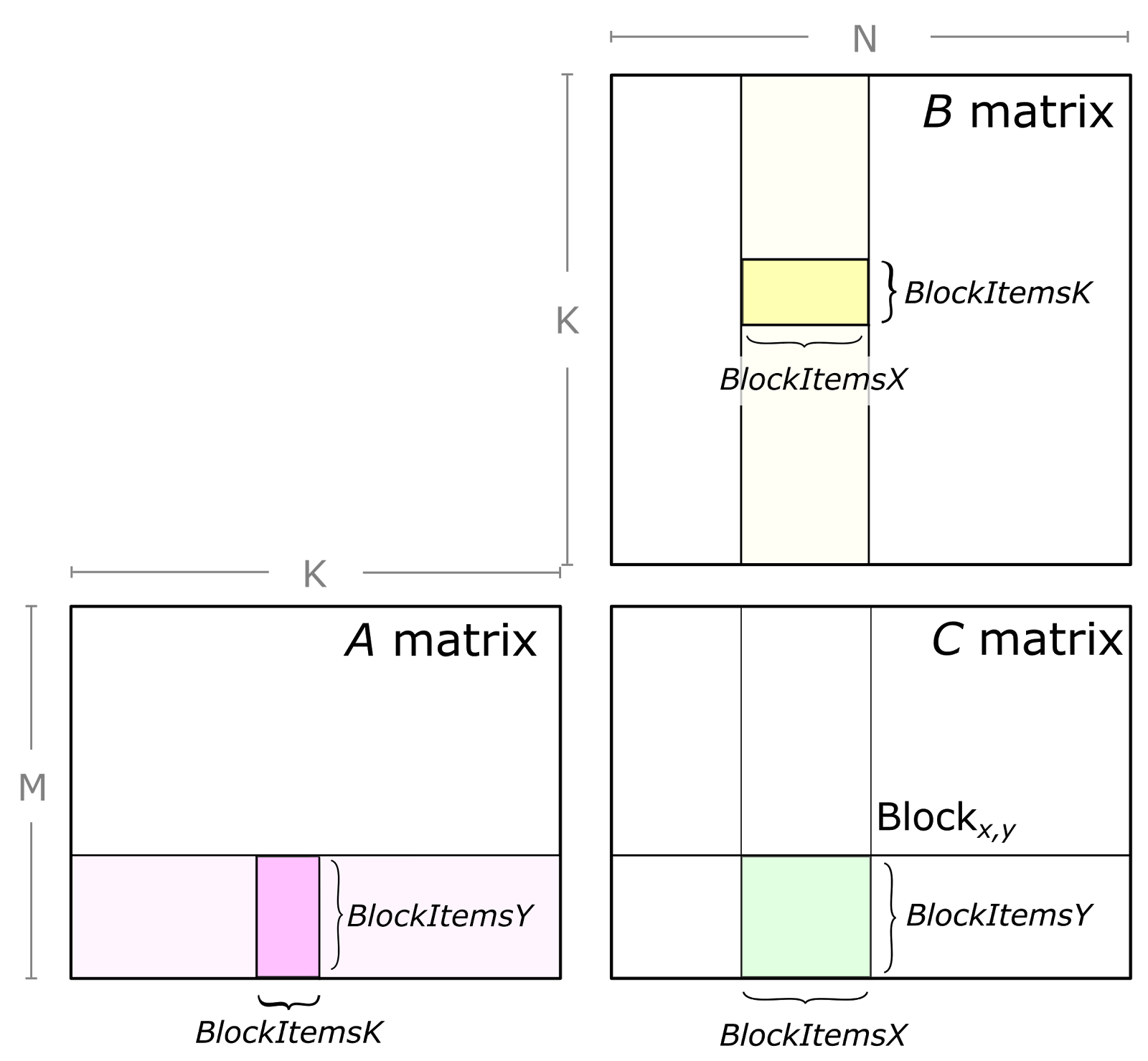
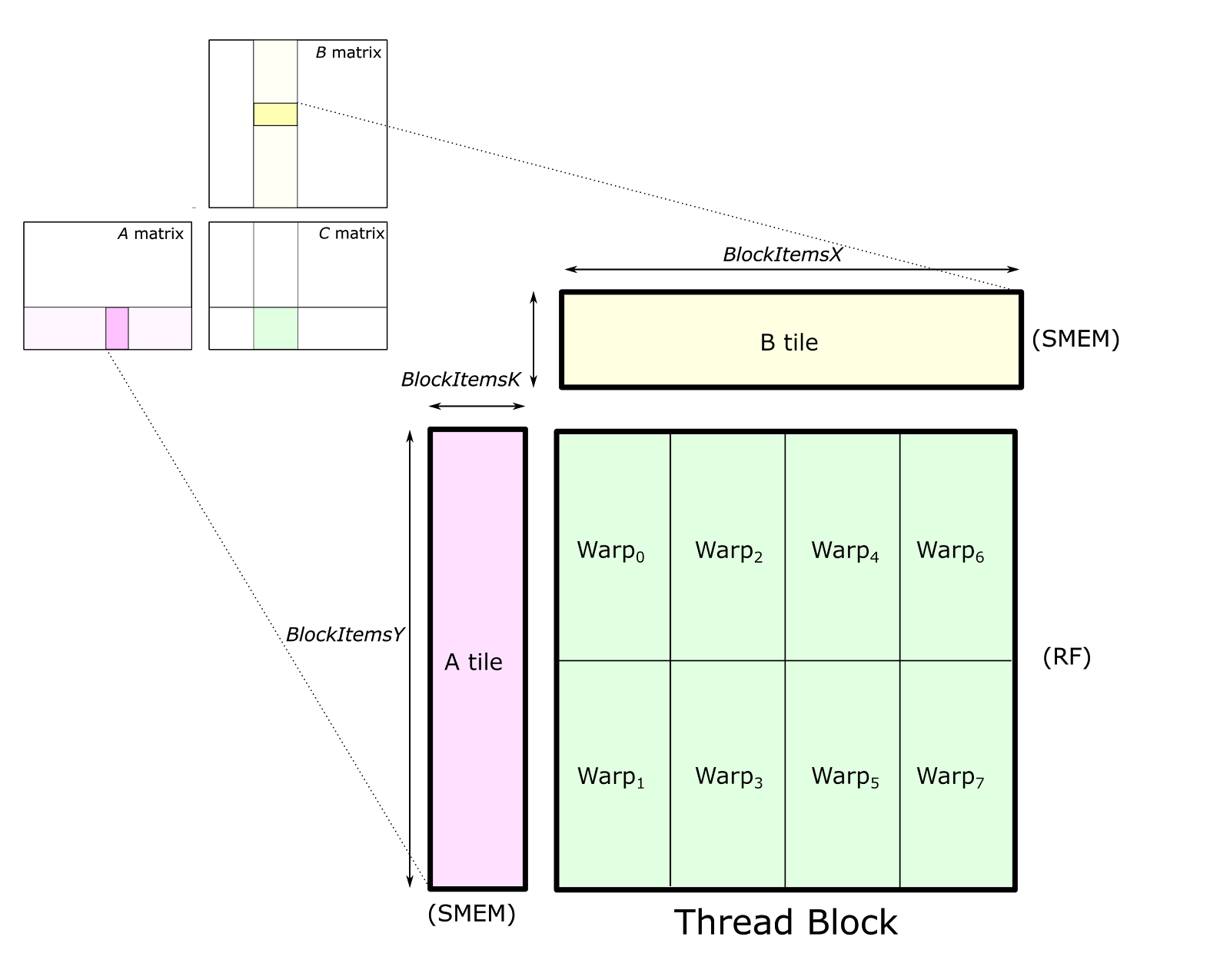
CUTLASS 将矩阵的计算过程自上到下分解成 Blocked GEMM, Thread Block Tile, Warp Tile, Thread Tile 四个层次,它们分别与 CUDA 编程模型中 Global grid, blocks, warps, threads 相对应。让我们一个一个来看:
首先是 Blocked GEMM,cutlass 首先使用矩阵乘内积划分方式,将矩阵 A 的 m 方向和矩阵 B 的 n 方向切分,切分后的每块由每个 grid 完成计算。然后,每个 grid 中,计算时会使用矩阵乘外积的划分方式沿 k 方向切分,grid 内的每个 block 负责完成其中高亮部分的计算,然后累加得到矩阵 C 的结果。可见,仍然遵循着先内积再外积的分割原则。