flash attention 进化史
flash attention 进化史
flash-attention V1
论文链接:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.
前向优化
从 HBM 到分块
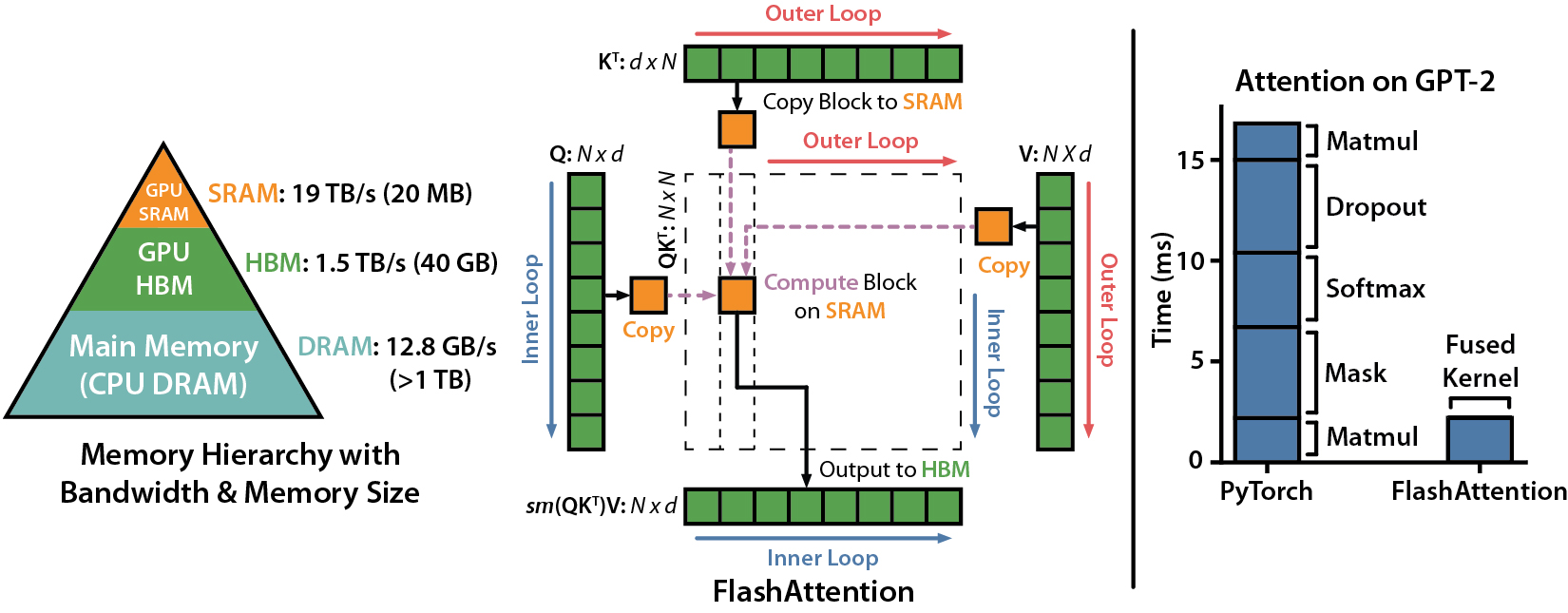
提升 Transformer 的性能和能力,使之能够处理更长的序列一直是一个非常重要课题。而 Transformer 架构中的 self-attention 计算量和访存量会随着输入序列长度呈二次增长。为了提升 Flash Attention 在 GPU 上的运行性能,特别是优化 attention 计算过程中的访存性能,Tri-Dao 提出了 Flash Attention,旨在优化 self-attention 计算时数据访存行为,因为现代 GPU 上,计算本身已经高度并行化,十分高效,而访存则因为带宽和延时进步不够快而落后。但若将小块数据量放在更小更近的高速缓存中,那么计算和访存的速度就相匹配,能更快地完成 attention 计算(如下左图)。
Tips:标准 Attention 的计算公式如下:
前面提到,Flash Attention 特别注重算法的访存行为,因此将标准 attention 算法抽象为如下图的具体流程:

不难看出,上面的算法中一共包含 8 次 HBM 的读写操作,分别为:
- 第一行对 的读取共两次,对 的写入一次,读写总共三次,访存复杂度为
- 第二行对 读取一次,对 写入一次,读写总共两次;访存复杂度为
- 第三行对 的读取共两次,对 的写入一次,读写总共三次,访存复杂度为
标准 attention 算法的访存复杂度为 ,对于较长的 N(即输入序列)来说,GPU 的内存访问压力太大了。为了减少对 HBM 的读写,Flash Attention 将参与计算的矩阵分块送进 SRAM,来提高整体读写速度(减少了 HBM 读写)。
softmax 的处理
确定了通过分块来降低对 HBM 的操作次数的思想后,一个棘手的问题挡在了我们前面,那就是 softmax。
数学上,标准 softmax 公式如下:
而在程序实现中,为了防止 exp 值过大导致的数值溢出,通常需要对 softmax 做如下修改:将每一项的幂次都减去这里的最大值 ,因为计算是相除,所以结果不变,但避免了溢出。
于是得到了 safe softmax:
但规避了数值溢出问题,另一个问题也紧接而来,如果要求出 m(x),就意味着必须先获取 这一块数据的所有值,才能完成 softmax 计算,这与我们要做分块并行的初衷相违背。
好在 Tri-Dao 等人通过巧妙地公式变换,将这一限制规避开了,接下来我们来看具体实现过程:
假设我们通过 得到了矩阵 ,该矩阵的某一行的向量为 ,因为分块的原因, 它被我们切成了两部分
定义:
- :标准场景下,该行的全局最大值
- :分块1的全局最大值
- :分块2的全局最大值
那么易知:
再定义:
- :标准场景下, 的结果
- :分块场景下, 的结果
- :分块场景下, 的结果
那么可以把幂次中的公共项提取出来,换成 就可以得到
定义:
- :标准场景下, 的结果
- :标准场景下, 的结果
- :标准场景下, 的结果
类似地,有
有了 和 的值后,softmax 的计算结果就可以完全用 替代:
看着比较复杂,其实就是一件事:用分块的最大值来暂时替代全局的最大值完成分块并行计算,如果分块的最大值不准确,那么就乘上全局的最大值与其的差来做弥补,同样可以获得与 safe softmax 一样的计算结果,而且计算变得可并行了。这种方法有时也被称为在线 softmax 算法。
结合下面的伪代码,我们来理解一下代码10-13行的计算步骤:

- 第10行: 就是当前分块 的局部最大值,相当于前面定义的 。而 ,相当于前面定义的 , 就是前面定义的
- 第11行:在循环中需要不断地更新计算 和 全局最大值
- 第12行:分块并行计算完成后,需要对计算得到的 做修正,还需要对之前累加到 的数值做修正。这其实是一个增量计算的过程,每次需要根据新的“全局最大值”来更新旧的 值。接着再处理下一个分块,然后再更新……具体地说,可以认为上一次循环求出的 是用来一个临时值求得的,which 从这个循环来看是错误。为做修正,需要让新的 在之前的 上做计算纠偏,于是有了 和 相乘,也有了 ,这些都是为了在数学上,抵消掉上一个循环得到的临时值,并让新的最大值发挥作用。
仔细观察内循环(伪代码 5-13 行),在整个计算过程中,只有 ,, 被写回到显存(HBM)中,相比于标准场景下,我们要写回到的是 ,读写量少了很多,缓解了 HBM 带宽限制。
因此,分块计算 safe softmax 的意义,就是抹去对 的写回。
分块计算
softmax 分块计算的棘手问题解决后,我们来看一下 flash attention 分块计算的其他流程。为了最大限度地使用片上 SRAM,flash attention 对 和 做了如下分块:
是 的列方向的分块大小, 是片上 SRAM 的大小,除以 是因为需要同时存放 四个矩阵,该计算确保了 SRAM 能同时存下所需的数据。 是 的行方向的分块大小,且不能超过 ,这是为了保证分块后计算得到的 可以被存放在 SRAM 上。
然后就是执行分块计算,如下面给出的 FlashAttention V1 示意图,图中就展示了分块计算的基本流程。 方向的分块是内循环,而 方向的分块是外循环。外循环开始时,会从 HBM 中 load 一块 到 SRAM 中,然后开始遍历 (这里假设是 prefill 阶段,q sequence length >> 1),从 HBM load 一块 后完成 的计算,随后 根据我们之前的介绍流程处理后,得到了 和 ,内循环结束后, 会被写回,再开始下一轮外循环。

让我们来计算一下 HBM 访存复杂度,每块 大小为 , 大小为 ,于是一个外循环加载 只需要 的数据量,而内循环全走一遍需要加载 ,一共有 个外循环,因此整个 flash attention V1 的访存复杂度为 ,在 LLM 中, 通常有 ,因此 flash attention V1 实现了更好的访存性能。
反向优化
很多博客文章都没有介绍 flash attention 的反向优化,虽然其思想与前向类似,但也不是完全不值得一说。在反向计算中,attention 的输入有 ,还有前向时的输出矩阵 ,以及输出矩阵的梯度 ,需要计算得到的是三个输入矩阵的梯度 。下面展示的是标准 attention 的反向计算流程。
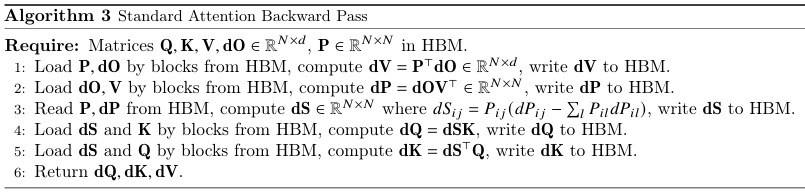
要看懂 flash attention v1 backward 的相关实现,首先需要理解 flash attention v1 backward 这些公式推导:
仍使用标准 attention 中相同的符号,其中 是显然的,但考虑到我们需要用分块思想减少 HBM 读取和存储,需要将刚刚的公式展开:
其中 $L_i=\sum_j{e^{q^T_ik_j}} $ 就是前向中计算的值,因为可以在同一个地址上重复累加,因此 计算时不需要很多内存。然后就是计算 ,这就稍微有点复杂。因为首先需要计算出 ,因为有 ,所以仍按之前的思路拆开后:
因为 ,且 的求导(Jacobian 矩阵)为 ,因此有
定义:
于是
推导出 后,我们才能通过 得到 和 ,当然, 为了分块,我们还是要将公式拆开写为 ,于是有:
对于 flash attention V1 的反向优化的技巧,结合上面的计算公式,Tri-Dao 等人在论文中明确指出:
- 对于计算得到的 的 dropout mask 矩阵,可以不需要存储下来,只需要保存在前向传播时的伪随机数生成器和其参数状态,然后用它在后向计算前重新产生一遍 dropout mask 矩阵就行了。这样可以节省 的 dropout mask 矩阵空间,只需要使用 O(N) 大小的内存。
- 从上面的计算公式可以看到,在计算 softmax 的梯度时,我们计算的 可以重写为 ,这样的好处是我们不需要在 N 方向做 reduce 操作,因为这样可能放不下 SRAM 来计算 。

flash-attention V2
提出 flash attention 后不久,Tri-Dao 等人在 V1 版本的基础上,又提出了 flash attention V2 版本,相比 flash attention V1,其运算性能又提升了一个新台阶。前面提到,flash attention V1 的重点优化在 HBM 的读写次数上,通过分块让矩阵 不再写回 HBM,而 flash attention V2 在此基础上,
- 优化计算次序,减少了非矩阵运算
- 调换循环方式,增加 seq len 维度的并行计算,提升 SM 利用率
- 优化了 GPU 内 Warp 级并行方式,减少内部通信和 shared memory 访问。
让我们一个个来看,这里先放上一张 flash attention V2 的 forward 伪算法图:

1. 优化计算次序
首先我们看 flash-attention V2 如何通过优化计算次序减少了非矩阵的计算量。
为了全面理解这一个优化技巧,我们需要回到 flash-attention V1 中对 的求值更新上,如果读者对 flash-attention V1 理解比较深的话,就会敏锐地发现对 的求值更新过于频繁且毫无必要,因为每一次循环都会把之前的旧值抵消掉!
于是,可对 值的每轮循环更新做的更加精细,以减少一些计算量。比如说, 每一轮都要计算,但都会被抵消,那所幸就不在循环内计算了呗,直接在循环结束后,乘上一个 。而为了配合这样的改动,需要对之前的 计算方法也同时做优化。最终版本就是,Tri-Dao 等人在循环内干脆不考虑 softmax 的分母计算(具体可参考下面两图,分别为改进前后的公式对比),循环内不在计算 和 softmax 的分母,减少了非矩阵计算量。
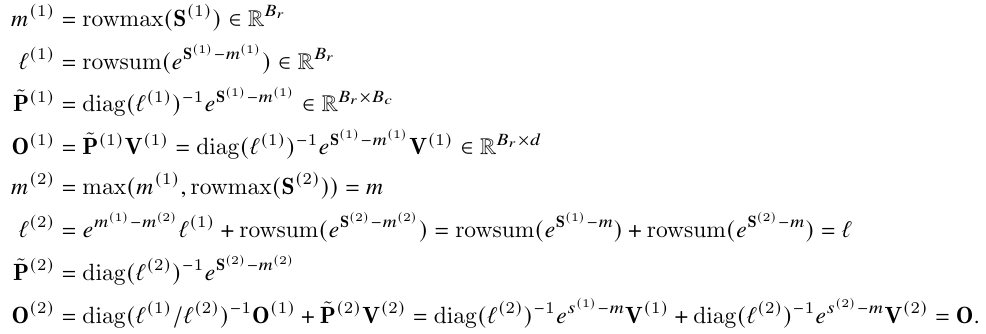
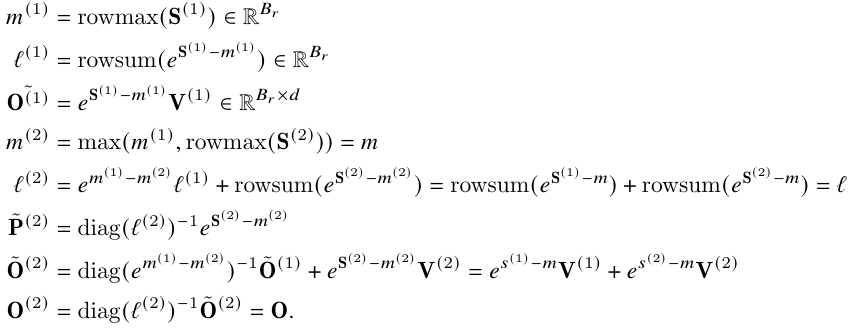
但循环内不考虑的分母,必须在循环外补上,否则计算就出错了,因此必须保留并累加 的值到最后。算法的 9 行就是实现了这一部分。
算法 12-15 行实现了对得到 值的更新。15 行和 17 行还有一个细节,就是计算了 logsumexp 的值 ,这是因为 Tri-Dao 等人注意到,将除分母计算移动到外循环后,反向传播就不需要把 都存储了,只需要保存 log-sum-exp 的值 即满足反向传播的计算要求。
这是为什么?其实还是数学的魔法:我们从下面的反向传播伪代码中可以发现,第 11 行 ,带入 logsumexp 的公式后,即可以得到真正的 值

2. 调换循环方式,增加 seq len 维度的并行计算
在 flash attention V1 上,batch size 和 num heads 两个维度上实现了并行化,GPU 通常使用一个 thread block 来处理一个注意力头,总共需要thread block 的数量等于 batch size × number of heads。每个 thread block 再被调到到一个 SM 上运行,那么当 thread block 数量很大时,这种并行运算方式是高效的,因为几乎可以有效利用 GPU 上所有计算资源。
但随着 LLM 处理的文本越来越长,batch size 就变得更小,此时的算法就很难再打满 GPU 上的计算资源了。于是,flash attention V2 设计了 seq len 这一维度上的并行,具体是如何做的稍后再说。
重新审视一下 flash attention V1 算法的两个循环,其中 分块在外循环递进, 在内循环被不断 load 到 SRAM 上。结合 flash attention V1 的伪代码,其外循环对 在 N 方向上遍历,内循环对 在 N 上遍历。flash attention V1 将 和 分别分为若干块,并在内循环中让他们都乘以不同的 ,得到 的一部分 ,然后经过局部 softmax 后还需要乘以 的一部分得到 ,下一次内循环 i++ 需要更新一遍 (对上一次 先纠正再加上当前值),写回 HBM,再读入下一个 ,这些操作导致每个内循环迭代都需要从 HBM 频繁读写 ,非常低效。
但第一点优化已经将对 的更新放到了循环外,于是整体的循环方式也可以重新设计。我们可以不让 在内循环迭代时频繁写出 HBM。我们将 移到了外循环, 移到了内循环,flash attention V2 每次内循环迭代都是针对一个 分块的计算,内循环就是可以不停地在 SRAM 上累加,等内循环结束后再除上 softmax 分母,最后写回 HBM,一锤定音。因此可以说,第二点就是针对第一点优化的具体实现。
为什么可以这样颠倒循环顺序?因为从数学上讲,这是因为输出结果 仅和 相关,与 均无逻辑依赖关系,所以可以并行进行。这一点观察尤为重要,因为这个特性,seq len 方向的并行实现才有数学基础。这也符合 attention 是加权平均和的语义解释,可以理解为 是 的更深语义空间的加权平均和表示。
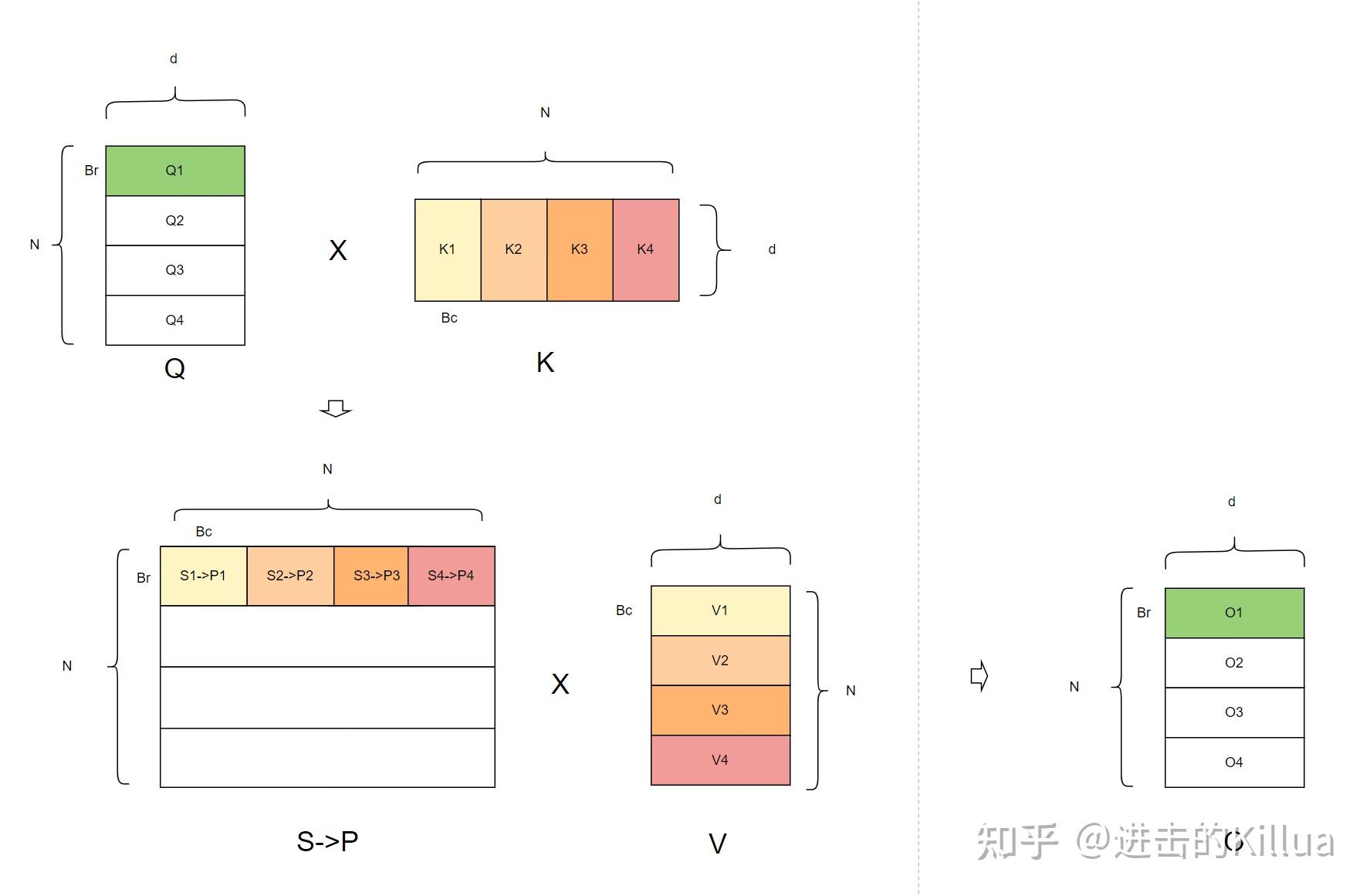
于是这就可以引出 seq len 维度并行的方法。在 flash attention V2 中一个 thread block 其实仅生成图示中结果 O 的一个子集(图中是O1),因为 仅和 相关, 于是可以安排多个 thread block load 和 ,并行计算 部分,从而增大算法整体并行度,提高了 GPU 利用率。
而在单个 thread block 内,迭代地对 (Q1,K1,V1),(Q1,K2,V2),(Q1,K3,V3),(Q1, K4, V4) 数据进行分块的 attention 运算,将结果累积至 O1 中,迭代中的 O1 值是中间结果值而最后一轮迭代后 O1 即为真实结果值。
3. 优化了 GPU 内 Warp 级并行方式
在每个 thread block 内部,也需要重新审视一下不同的 warp 的并行计算量。通常在每个 thread block 中使用 4 或 8 个 warp,如下图所示。
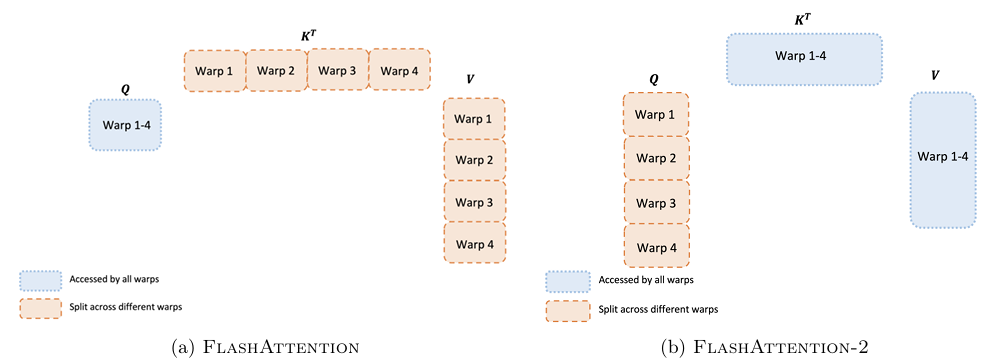
在 V2 实现中,Q 维度上按也按 warp 进行切分,如前文所述 Q 维度上的切分是互相独立的,所以这里的 warp 不存在同步开销,同时不需要在内循环中进行 HBM 写入(改为更低频的外循环写入,因为内循环一轮直接就计算完成了,不需要跨外循环同步),减少了 HBM 的读写。
我这里叽里咕噜地说了很多,甚至有点啰嗦,但我想给各位读者的 takeaway 是,其实这一二三点优化技巧都是环环相扣的,不能孤立地去看这三种优化技巧。说白了,flash attention 因为在内循环,抛弃了计算 softmax 分母,将它移动到外循环,才有了对 的反复累加利用,也才有了内外循环颠倒的操作,并且因为发现了 Q 维度的并行性,也重新设计了 Warps 的并行方式。事实上三个优化策略中,作用最大的应该是第二个,而第三个又是和第二个相辅相成的,第一个可以认为是算法逻辑上的一些小trick。总的来说,经过 flash attention V2 版本后,整个逻辑就更加通顺和易理解了。
因果掩码
最后再提下因果掩码(Causal masking),这是 attention 的一个常见操作,特别是在自回归大模型中,需要对注意力矩阵 应用因果掩码(任何 满足 的项都应为 )。由于 flashAttention 已经使用分块来计算,所以根据 row 和 column 的 index 大小可以分为三种类型:
- column_index < row_index,此时整个块都需要进行计算。
- column_index = row_index,应用因果掩码对块内数据进行处理后再计算,可避免部分运算。
- column_index > row_index,此时整个块都可以skip,不需要进行计算
长文本下的 Decode 优化 —— Flash Decoding
为了更好地提升长文本下 attention 的计算速度,Tri-Dao 等人提出了 Flash-Decoding 技术,显著加快了推理期间的注意力计算速度,对于非常长的序列,生成速度可提高 8 倍。其主要思想是尽可能快地并行加载 和 ,然后分别重新缩放和组合结果以保持正确的注意力输出。
用于解码的多头注意力
在解码过程中,每个新生成的 token 都需要关注所有先前的 token,以计算
此操作在训练情况下已通过 flash attention(V1 和 V2)进行了优化,此时瓶颈在于读写中间结果(例如 Q @ K^T)的内存带宽。然而,这些优化不直接适用于推理情况,因为瓶颈不同。对于训练,flash attention 在 batch size 和 seq len 维度进行并行化。而在推理期间,Q seq len 通常为 1:这意味着如果 batch size 小于 GPU 上的流式多处理器 (SM) 数量(A100 为 108 个),此时 attention 计算只能利用 GPU 的一小部分计算资源!当使用长上下文时,这种情况尤其明显,因为长文本往往意味着更小的 batch size(这样才能装入 GPU 内存)。对于 batch size 为 1 的情况,flash attention 将只使用不到 1% 的 GPU 资源!

用于解码的更快注意力:Flash-Decoding
我们新的 Flash-Decoding 方法基于 flash attention V2,并增加了一个新的并行化维度: 序列长度。它结合了上述两种方法的优点。与 flash attention 类似,它只将很少的额外数据存储到全局内存中,但只要上下文长度足够大,它就能充分利用 GPU,即使 batch size 很小。
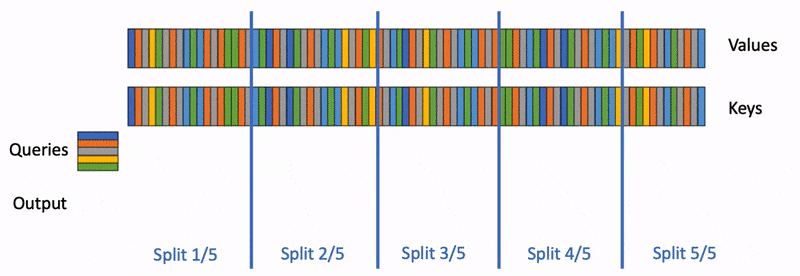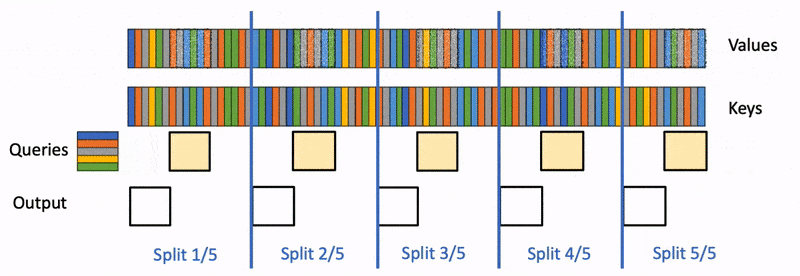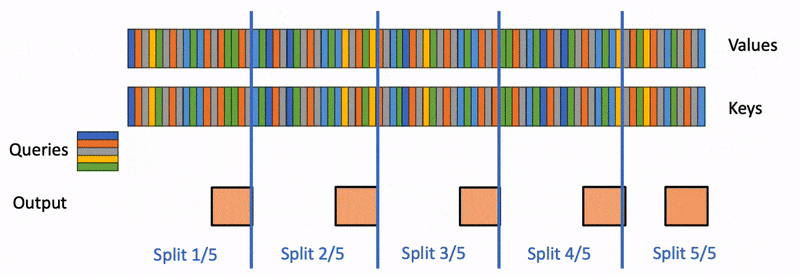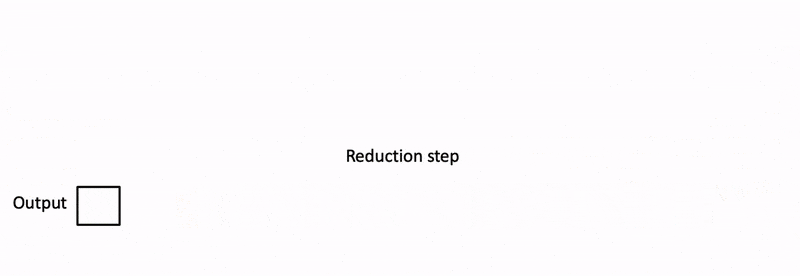
Flash-Decoding 分 3 个步骤工作
- 首先,将 分成更小的块(splits KV)
- flash attention 并行计算 与 这些 中每个块的注意力。此外,还要为每行和每个块写入 1 个额外的标量:注意力值的 log-sum-exp
- 最后,我们通过对所有块进行归约来计算实际输出,使用 log-sum-exp 来缩放每个块的贡献。
因为注意力/softmax 可以迭代计算,所以上面的所有步骤都是可行的。在 Flash-Decoding 中,它在两个级别使用:With Splits(类似于 flash attention),以及 across splits 执行最终归约。
在实际实现时,第一步不涉及任何 GPU 操作,但需要实现 2 个单独的 kernel 分别执行第二步和第三步。参考代码 flash-attention v2.8.3,这两个 kernel,我没理解错的话应该就是:flash_fwd_splitkv_kernel 和 flash_fwd_splitkv_combine_kernel。
请注意,这里特别提到了 log-sum-exp,回顾 flash attention V2 的实现伪代码,我们说这是用来给反向传播准备的,但这里又说是给衡量每个块的“贡献”而准备的,那怎么理解这个值的含义呢?遗憾的是,原博客中没有说明这一点,而其他很多博客也对其只字不提。为此,笔者深入研究代码,发现 lse 值在 splitsKV 的场景下,还需要经过 flash_fwd_splitkv_combine_kernel 将各段的局部输出归一化,最终得到全局的注意力输出。当使用 flash_fwd_splitkv_kernel 得到各个分段的 时,还需要计算全局的 LSE 值(通过累加各分段的 lse),然后最终加权求和得到最终的注意力分数。但笔者数学水平有限,尚无法给出精确详细的数学证明,只能说从代码实现来看这一结果没有问题。
flash-attention V3
虽然 flash attention V2 在 Ampere (A100) GPU 上可以达到理论最大 FLOPs 的 70%,但尚未充分利用 Hopper GPU 的新功能来最大化性能。我们在此介绍 Hopper 的一些新特性以及它们为何重要。
Hopper 架构新特性
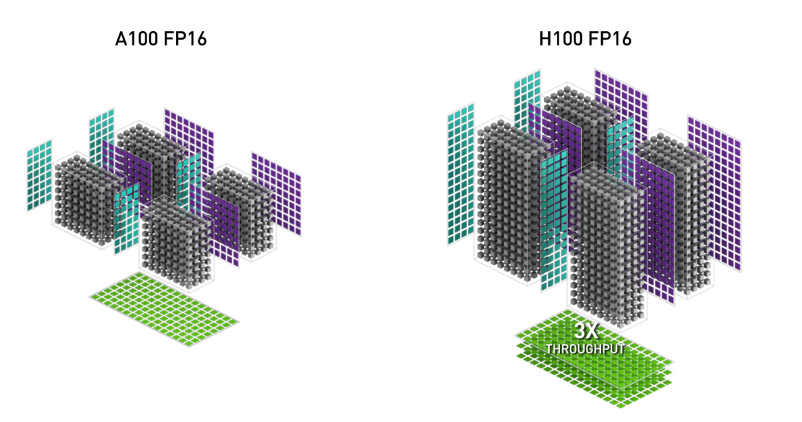
- WGMMA (Warpgroup Matrix Multiply-Accumulate)
这项新功能利用了 Hopper 上新的 Tensor Cores,其吞吐量比 Ampere 中较旧的 mma.sync 指令高得多
- TMA (Tensor Memory Accelerator)
这是一个特殊的硬件单元,用于加速全局内存和共享内存之间的数据传输,负责所有索引计算和越界预测。这释放了寄存器资源,这对于增加块大小和提高效率非常宝贵。
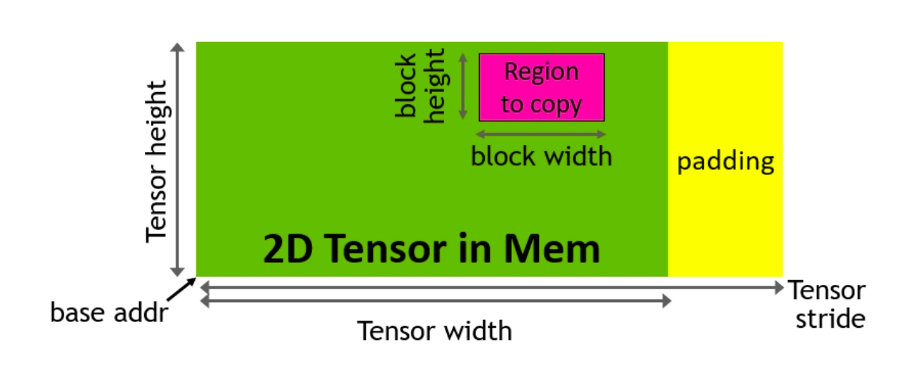
- FP8 Low Precision
这使 Tensor Core 的吞吐量翻倍(例如,FP16 为 989 TFLOPS,FP8 为 1978 TFLOPS),但通过使用更少的位数来表示浮点数来牺牲精度。
flash attention V3 利用了 Hopper 的所有这些新功能,并使用了 NVIDIA 的 CUTLASS 库提供的强大抽象。
通过重写 flash attention V3 以使用这些新功能,我们已经能够显著加速它(例如,FP16 前向传播从 flash attention V2 的 350 TFLOPS 提升到约 540-570 TFLOPS)。此外,Hopper 上新指令(WGMMA 和 TMA)的异步性质为重叠操作提供了额外的算法机会,从而实现更高的性能。
我们将解释重点两种针对注意力的优化技术。warp 专门化的通用技术,具有独立的生产者和消费者 warp 来执行 TMA 和 WGMMA,在 GEMM 的背景下 已有充分的介绍 ,并且在这里也适用。
异步执行
为什么需要重叠?
注意力的两个主要操作是 GEMMs(Q 和 K 之间的矩阵乘法,以及注意力概率 P 和 V 之间的矩阵乘法)和 softmax。为什么我们需要重叠它们?难道大部分 FLOPS 不都在 GEMMs 中吗?只要 GEMMs 够快(例如,使用 WGMMA 指令计算),GPU 不就应该“全速运转”了吗?
问题在于,在现代加速器上,非矩阵乘法操作比矩阵乘法操作慢得多。指数函数(用于 softmax)等特殊函数比浮点乘加运算的吞吐量更低;它们由多功能单元(MFU)计算,该单元独立于浮点乘加或矩阵乘加单元。例如,H100 GPU SXM5 具有 989 TFLOPS 的 FP16 矩阵乘法能力,但特殊函数的吞吐量仅为 3.9 TFLOPS(低 256 倍)2!对于头维度为 128 的情况,matmul 的 FLOPS 是指数函数的 512 倍,这意味着指数运算可能需要占用到与 matmul 相等的时间(50%)。对于 FP8 来说,情况更糟,matmul 的 FLOPS 快两倍,而指数运算的 FLOPS 速度保持不变。理想情况下,我们希望 matmul 和 softmax 并行运行。当 Tensor Cores 忙于 matmul 时,多功能单元应该在计算指数!
通过乒乓调度实现跨 warp-group 的重叠
重叠 GEMM 和 softmax 的第一种也是最简单的方式是——什么都不做!warp 调度器已经尝试调度 warp,以便当某些 warp 被阻塞时(例如,等待 GEMM 结果),其他 warp 可以运行。也就是说,warp 调度器免费为我们完成了部分重叠工作。
然而,我们可以通过手动进行一些调度来改进这一点。例如,如果我们有两个 warpgroups(标记为 1 和 2——每个 warpgroup 是 4 个 warp 的集合),我们可以使用同步屏障(bar.sync)使 warpgroup 1 首先执行其 GEMMs(例如,一次迭代的 GEMM1 和下一次迭代的 GEMM0),然后当 warpgroup 1 执行其 softmax 时,warpgroup 2 执行其 GEMMs,依此类推。这种“乒乓”调度在下图中有说明,相同的颜色表示相同的迭代。
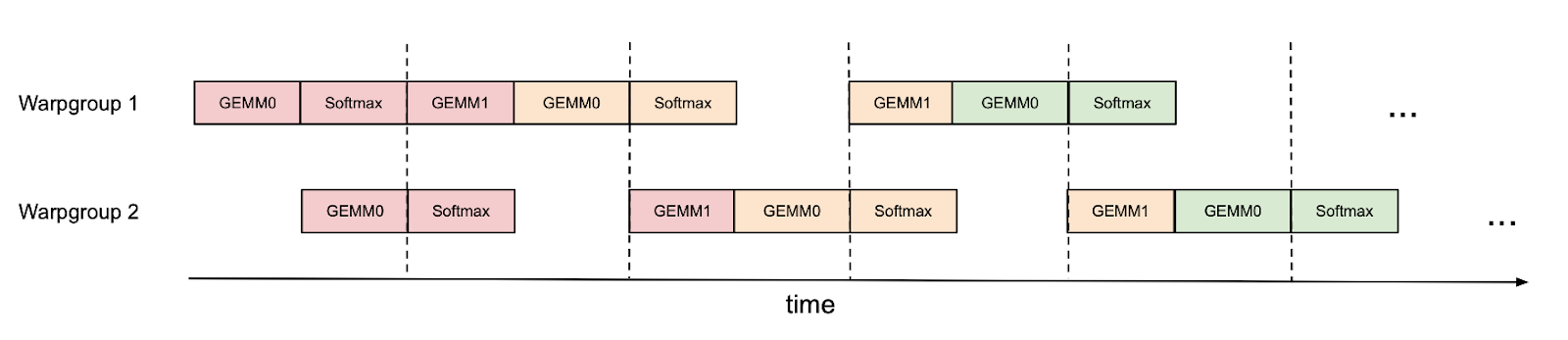
这使得我们可以在另一个 warpgroup 的 GEMM 运算的“阴影”中执行 softmax。当然,这张图只是一个简化示例;实际上,调度并非如此清晰。尽管如此,乒乓调度可以将 FP16 注意力前向传播的吞吐量从大约 570 TFLOPS 提高到 620 TFLOPS(头维度 128,序列长度 8K)。
跨 warp-group 内部的 GEMM 和 Softmax 重叠
即使在一个 warpgroup 内部,我们也可以让部分 softmax 在该 warpgroup 的 GEMM 运行时进行计算。下图说明了这一点,相同的颜色表示相同的迭代。
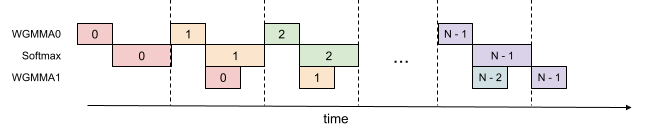
这种流水线处理将 FP16 注意力前向传播的吞吐量从大约 620 TFLOPS 提高到约 640-660 TFLOPS,代价是更高的寄存器压力。我们需要更多的寄存器来同时容纳 GEMM 的累加器以及 softmax 的输入/输出。总的来说,我们发现这种技术提供了一个有利的权衡。
低精度:通过不连贯处理降低量化误差
LLM 激活可能包含 离群值,其幅度远大于其余特征。这些离群值使得量化变得困难,产生更大的量化误差。我们利用了不连贯处理,这是一种在量化文献中使用的技术(例如,来自 QuIP),该技术将查询和键与一个随机正交矩阵相乘,以“扩散”离群值并减少量化误差。特别是,我们使用 Hadamard 变换(带随机符号),该变换可以按注意力头进行,时间复杂度为 O(d log d),而不是 O(d^2),其中 d 是头维度。由于 Hadamard 变换受内存带宽限制,它可以与之前的操作(如旋转嵌入,也受内存带宽限制)“免费”融合。
在我们进行 Q、K、V 来自标准正态分布但 0.1% 的条目具有大值(模拟离群值)的实验中,我们发现不连贯处理可以将量化误差降低 2.6 倍。下表显示了数值误差比较。

flash-attention V4
不得不说时代发展的很快,尤其是 AI 时代。Tri-Dao 就在前不久发布了 flash attention V4。论文指出,Blackwell GPU 这样的现代加速器延续了非对称硬件扩展的趋势(asymmetric hardware scaling),所谓非对称硬件扩展,指的是 Tensor Core 的吞吐量增长速度远超其他资源,例如共享内存带宽、用于指数等超越运算的特殊功能单元(SFU) 以及通用整数和浮点(ALU)。这也就意味着,随着 GPU 硬件在不对称扩展, Tensor Core 不断变快,attention 计算瓶颈发生了变化,非 matmul 单元因没有同步变快导致了新的瓶颈,为此必须重新设计 flash attention 算法和流水线,压榨 GPU 的所有资源。
例如,从 Hopper H100 到 Blackwell B200,BF16 张量核心吞吐量从 1 PFLOPS 提升至 2.25 PFLOPS,而 SFU 数量和共享内存带宽均保持不变。flash attention V3 主要针对 Hopper H100 设计,到了 Blackwell 上不再是最优,非 matmul 部分开始主导执行时间,尤其是
forward 里的 softmax exp 计算。这点其实在 flash attention V3 也已有察觉,为了充分打满计算资源设计,V3 设计了 GEMM 和 softmax 的 ping-pong 调度,而 backward 里的 shared memory 读写和原子加也是新的瓶颈。
Blackwell 新架构
1. 张量内存(TMEM)
Blackwell 引入了新的硬件架构叫 Tensor Memory (TMEM),一个程序员可见的可快速存储 Tensor Core 中间结果的暂存器(scratchpad)。在 B200 上,148 个 SM 中的每一个都有 256 KB 的 TMEM,连接到 Tensor Core,用于 warp 同步中间存储。
2. 全异步 Tensor
tcgen05.mma 可全异步运行,并在 TMEM 中进行累加。对于 BF16 和 FP16 编码,最大的单个 CTA UMMA tile 为 128×256×16,约为最大 Hopper WGMMA 原子的两倍。UMMA 由单个线程启动,减轻了寄存器压力,使得更大的 tile 和更深的流水线成为可能,而不会像 Hopper WMMA 那样出现寄存器溢出问题。这也使得 warp specialization 更加可行。比如,一些 warp 可以做一些同步工作比如 softmax,这些需要寄存器来完成,而另一些 warp 可以发出 load 指令和 MMA 指令,以进行重叠矩阵加载和乘法累加,从而让更多的操作同时进行,隐藏时延。
3. 2-CTA MMA
Blackwell 允许同一 cluster 中的 2-CTA 上执行一个 UMMA 操作,该操作能读取写入两个对等 CTA 的 TMEM,但这要求两个 CTA 都必须在 MMA 执行期间保持活动状态。与将 M 维度限制为 128 的单 CTA MMA 相比,2-CTA 模式支持 M = 128 或 256,它在 M 维度上将 A 矩阵块和累加器分配给这 2-CTA,而在 N 维度上将 B 矩阵块分配给两个 CTA,从而支持 M=128 或 256;这样每个 CTA 只需在其自身的共享内存中暂存一半的 B,而硬件在执行乘法时会消耗合并后的完整 B 矩阵块。这不仅减少了共享内存容量和带宽的冗余,但由于这些操作涉及跨 CTA 对的张量内存访问,内核必须以固定的成对方式启动 CTA,并在整个内核中对张量内存和张量核心操作使用一致的双 CTA 模式。
参考链接
[1] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. https://arxiv.org/abs/2205.14135
[2] https://zhuanlan.zhihu.com/p/642962397
[3] 大模型优化-FlashAttention-v1 https://baoblei.github.io/2024/12/07/da-mo-xing-you-hua-flashattention-v1/
[4] FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning https://arxiv.org/pdf/2307.08691
[5] https://zhuanlan.zhihu.com/p/682441154
[6] https://pytorch.ac.cn/blog/flashattention-3/
[7] https://tridao.me/blog/2024/flash3/
[8] https://pytorch.org/blog/flash-decoding/
[9] FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling https://arxiv.org/pdf/2603.05451v1
[10] Blackwell: bigger tensor cores, bigger problems https://pytorch.org/blog/flexattention-flashattention-4-fast-and-flexible/
[11] We reverse-engineered Flash Attention 4 https://modal.com/blog/reverse-engineer-flash-attention-4
[12] https://zhuanlan.zhihu.com/p/2013279867173626503