flash-attn 实现 prefill 阶段
初步认识好 MMA 指令后,我们来看一下 flash-attn 要怎么用 MMA 指令来实现。
问题分析
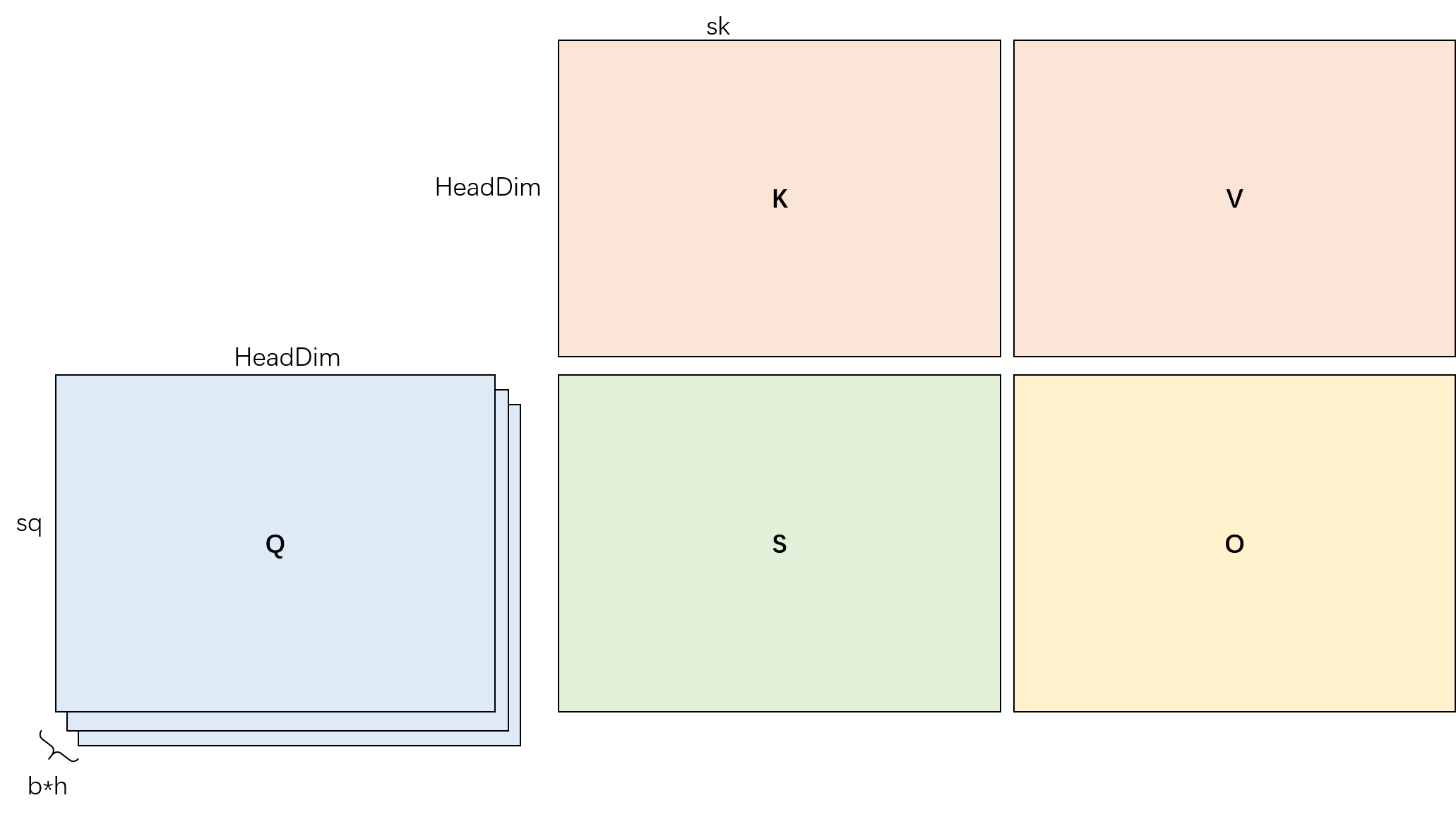
首先,需要明确 flash-attn 的输入输出,那么在很多大模型的 prefill 阶段,输入输出 Q K V O 张量的输入张量维度都是:[batch_size, num_heads, seq_len, head_dim],我们为方便起见,简写成 [b, h, sq, d]。
另外,大多模型的 head_dim 维度都是固定为 128,因此我们优先考虑 d=128 的情况。
再来看计算过程。attention 的计算公式是:
但这样的 QKV 张量实在是太大,不可能直接用一个 mma 就完成。对于四维张量,前面两维度是可以完全并行起来的,后面两维度才涉及到矩阵乘法。因此,可将前两个维度放到 GPU block 间做并行(即 grid size),反正他们完全可并行,不需要考虑这么多。
于是,我们得到了这样一张矩阵乘法图,首先计算 QK,得到矩阵 S,然后 S 与 V 相乘获得最后的结果 O(softmax 和 scale 等先略去)。
然而,这样的矩阵乘还是太大了,一个线程块都无法处理。我们需要进一步将矩阵切分,这里涉及到矩阵乘法时要如何切分的问题。对 M 和 N 方向切分还是对 K 方向切分?让我们回到实际问题,M 和 N 方向相当于是 seq_len 的长度,显然它是不确定的,它可能会非常长,也可能会非常短,而 K 方向的长度是一定的,我们只考虑 K=128 的情况,因此,我们选择在 M 和 N 方向切分,将不确定的长度切分成确定的大小,才有利于我们后续实现矩阵乘,否则 seq_len 要适配所有情况,难度太大。
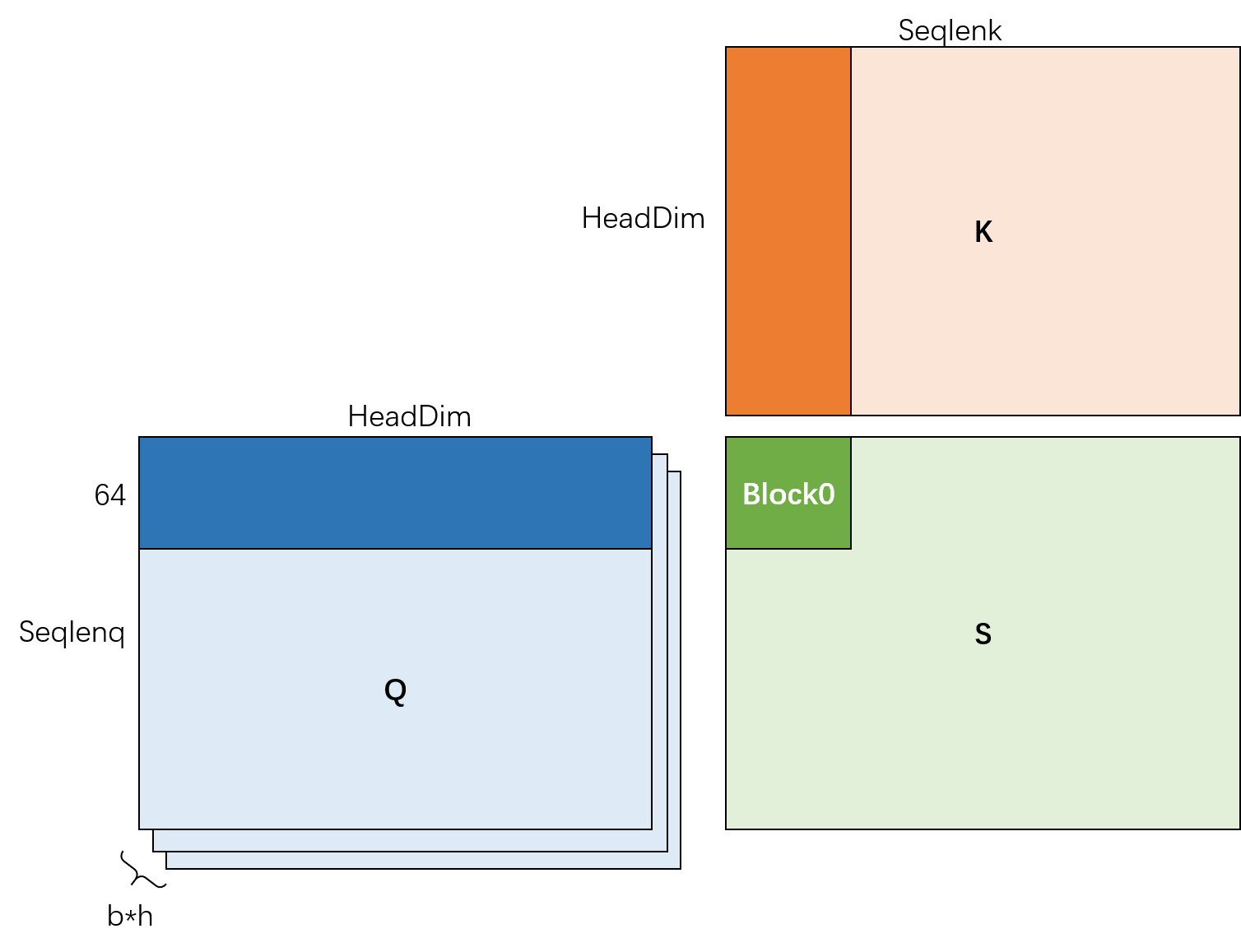
那么我们现在一拍脑袋,先把 Seqlenq 和 Seqlenk 切分成等长 64 的吧(这些值的最有配置需要后续实现完成后 tune 一把,现在实现不考虑性能优劣):
1 | |
切分完成后,我们终于可以让一个 CUDA 线程块来处理深色部分的区域了,得到的计算结果会填充到深绿色地方。
于是,让我们考虑一个线程块内的事情,由于 MMA 指令都是指挥一个 Warp 做事情,因此我们还需要考虑一个线程块内所有 Warp 要如何切分。
这里的关键在于 m16n8k16 的矩阵方块对应一个 Warp,需要用这个16行16列的颗粒度铺满整个矩阵 A,用16行8列颗粒度铺满矩阵 B,进而完成矩阵乘法计算。
在纸上画一下,使用 mma 分割方式只有一种,但用 Warp 分割的方式可以有很多种。比如说,我们假定一个线程块有 8 个 Warps,即 256 个线程,那么可以按下面任意方式将矩阵分成 8 份,每份由一个 Warp 来负责计算,每种 Warps 的切分实现的代码就会不一样。若再考虑到 block size 可以改变的话,实现的方案会更多,至于哪种性能最优,最简单的办法就是 tune 一遍看。
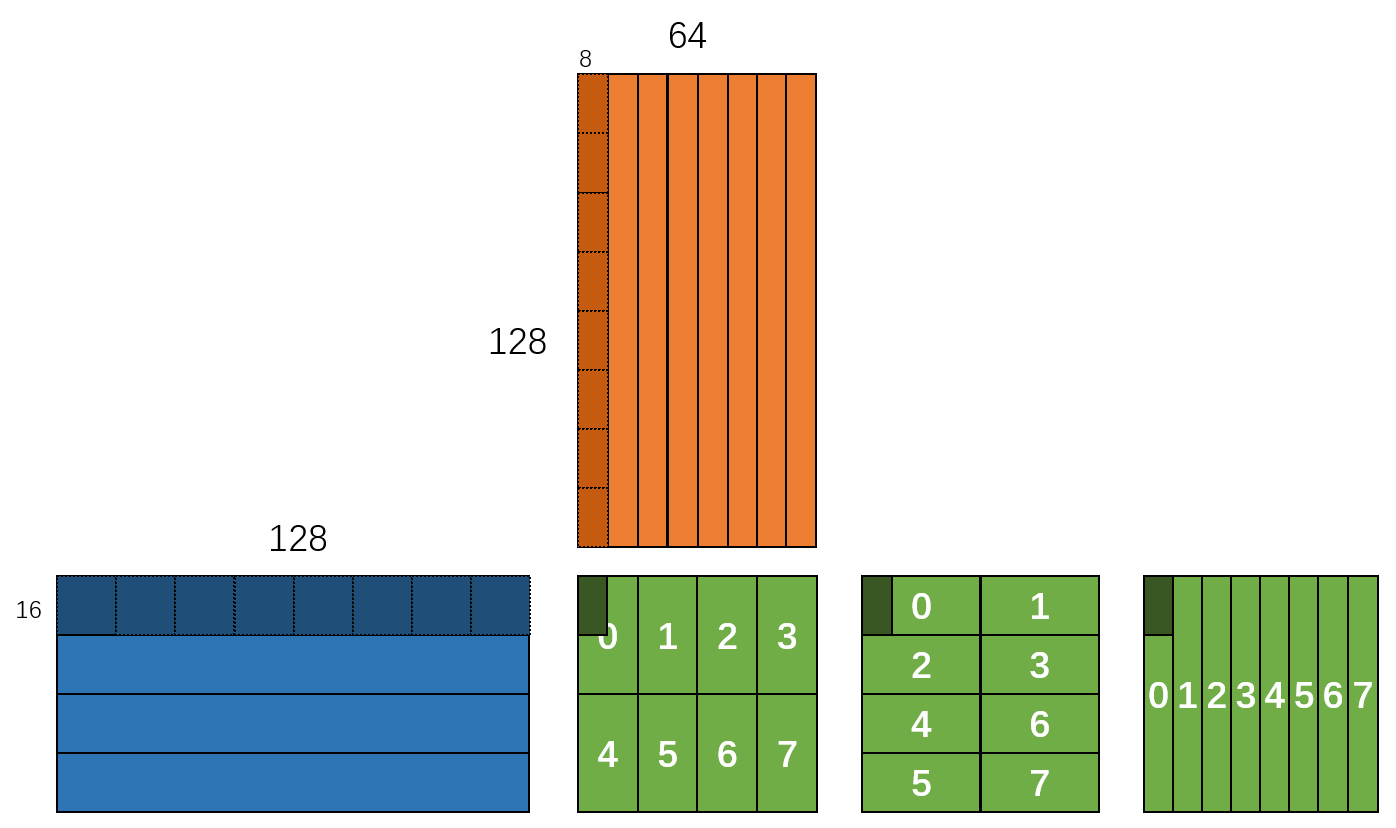
那么,我们就取图中第一种分割方法来实现 mma 吧。
线程与数据的映射
写 CUDA 马虎不得,尤其是处理哪个线程对应处理哪块数据时更加马虎不得。我们仔细地按照上图第一种方式做切分。调用函数情况如下:
1 | |

假设我们已经拿到了 QKV 三个 global tensor 指针:
1 | |
那么首先,要确定哪个线程块对应哪块数据,然后把他们的部分装到 shared memory,否则就在一开始就 load 错数据了。
考虑矩阵 Q,注意它是四维的,[b, h, sq, d],所以寻址会非常复杂。我们之前说过,前两个维度是用 grid 切的 grid(b*h, (sq+nrow)/nrow)。
所以图中,矩阵 A 的一页大矩阵就是一个 blockIdx.x ,它将矩阵 A 切分成了 b*h 份,因而一个 blockIdx.x 对应的大小是 sq*d,所以这块的偏移量是:blockIdx.x * sq * d,然后再考虑 blockIdx.y 它用于寻址页内的block id 数,因此它对应的大小是 64 * d,所以这块偏移量是 blockIdx.y * nrow * d,那么总偏移量就是:
1 | |
对于 K 而言,也是一样的道理:
1 | |
然后要确认线程块内每个 Warp 负责区域的偏移量,要明确每个线程属于哪个 warp:
1 | |