Ray 框架初步认知与理解
Ray 框架内部原理理解
本文参考 Ray 论文
Ray 框架解决的需求
最新的强化学习(RL)算法强调让 AI 通过与环境的不断交互来学习提升自己。其核心目标是要让 AI 学习一个策略,这个策略将根据环境的变化,让 AI 自主做出相关的应对动作,并在环境中不断提升应对策略,久而久之 AI 将学会一个有效的任务(例如赢得游戏或驾驶一架无人机)。在大规模的应用中,寻找有效的策略需要三大能力:
-
模拟仿真(或者说 Rollout)。RL方法通常依赖于大量模拟来评估一个策略。仿真能够让智能体去探索众多不同的动作选择序列,并能够了解这些选择对于实现目标有怎样的长期影响。
-
分布式训练。在强化学习中,完成策略评估后,需要对策略做改进,这些改进通常是通过训练深度神经网络的方法来进行的,训练使用的数据来自 1 中仿真过程或与物理环境的交互。
-
服务部署。RL 策略的最终目的是要为控制问题提供解决方案,因此在训练完成之后还需要将策略作为服务部署,应用于交互式的闭环或开环的控制问题场景。
强化学习的上述特征对框架提出了新的系统需求:
-
支持细粒度的计算。即单次计算任务非常轻量,但是所需计算的次数十分庞大,例如与真实世界进行大量的动作交互,或进行大量的仿真。
-
支持对于时间和资源的非均匀使用 (heterogeneity)。例如一次仿真可能只需要几毫秒,也可能需要好几个小时;仿真主要使用CPU,而训练则主要使用GPU.
-
支持动态执行。仿真结果或与环境交互的结果可能会实时地影响后续的计算任务。
Ray 框架简介
Ray 是为满足上面这些需求而开发的通用集群计算框架,既支持模型的训练,又支持对环境的仿真或与环境的交互,还支持模型服务。
Ray 所面临的任务涵盖了从轻量级、无状态的计算任务(例如仿真)到长时间运行的、有状态的计算任务(例如训练)。
为此,Ray 实现了一套统一的接口,这套接口既能表达基于任务的并行计算(task-parallel),又能表达基于行动器的并行计算(actor-based)。
前者使得 Ray 能高效地、动态地对仿真、高维状态输入处理(如图像、视频)和错误恢复等任务进行负载均衡,后者行动器的设计使得 Ray 能有效地支持有状态的计算,例如模型训练、与客户端共享可变状态(如参数服务器)。Ray 在一个具有高可扩展性和容错性的动态执行引擎上实现了对任务和行动器的抽象。
Ray 编程模型
正如上文需求分析中所述,Ray 中有两个重要的概念:任务(Task)和行动器(Actor)。Ray 编程模型是指 Ray 框架基于任务和行动器这两个重要需求所向用户提供的一套 API 及其编程范式。下表展示了 Ray 提供的核心API,详细参考 Ray 文档。
| API | Description |
|---|---|
| ray.init() | 初始化 Ray |
| @ray.remote | 函数或类的装饰器,加上后可以在其他进程上执行 |
| .remote() | 每个 remote 函数的后缀,remote 函数会被异步调用 |
| ray.put() | 将传入的参数同步地保存起来,返回 ID |
| ray.get() | 阻塞直到远端将计算得到的值传回来 |
| ray.wait() | 等待返回已经就绪的值 |
具体来说,使用时需牢记:任务是无状态的远程函数。远程函数被调用时无法立即返回值(因为它是远端的),只能先给一个 future 对象,真正的返回值需通过 ray.get(<future对象>) 的方式来获取。
这样的编程模型既允许用户编写并行计算代码,同时又提醒用户要关注数据之间的依赖性。
任务的编程范式如下:
- 注册任务:在需要注册为任务的函数上加上
@ray.remote装饰器 - 提交任务:在调用具有
@ray.remote装饰器的函数时,需要带上.remote()而不是直接调用 - 非阻塞提交:无论任务的运行需要多少时间,在提交任务后都会立即返回一个 ObjectRef 对象
- 按需阻塞获取结果:在你需要函数的返回值时,可以通过
ray.get来获取
以下代码是一个任务从注册到运行完成获得结果的示例:
1 | |
任务是无状态的,任务所操作的对象都可以看作不可变对象(Immutable Objects),或者任务调用可以看作一个无副作用的(Side-effect Free)表达式,任务的输出(返回值)仅与输入(实参)有关。
任务的设计使得 Ray 具备以下能力:
- 细粒度负载均衡:利用任务级粒度的负载感知调度来进行细粒度的负载均衡
- 输入数据本地化:每个任务可以在存有它所需要的数据的节点上调度
- 较低的恢复开销:无需记录检查点或恢复到中间状态
行动器是有状态的,每个行动器都有一些可供远程调用的函数,类似于任务中的远程函数,不同的是,使用 f.remote 顺序地提交若干个远程函数后,这些函数是并行执行的,但在同一个 actor 下使用actor.method.remote 顺序地提交若干个远程方法后,这些方法将串行地执行。但不同 actor 之间的调用是可以并行的。可以用一个图来描述任务和行动器的区别和联系:

行动器的编程范式如下:
- 注册行动器:在需要注册为行动器的类上加上@ray.remote装饰器
- 实例化行动器:相比于普通Python类的实例化,需要在类名后加上.remote
- 提交方法调用:调用行动器的方法时,同样需要带上.remote()而不是直接调用
- 非阻塞提交:无论方法的运行需要多少时间,在提交任务后都会立即返回一个ObjectRef对象(同一行动器实例下,方法会按照提交顺序串行地运行)
- 按需阻塞获取结果:在需要方法运行的返回值时,可以通过ray.get来获取
以下代码是一个行动器从注册到运行完成获得结果的示例,且展示了行动器方法的串行性质:
1 | |
行动器使得 Ray 具备更高效的细粒度更新能力。因为它是一种高内聚的设计,状态与可能改变状态的操作被设计在一个类中,使得这些操作不依赖于外界的状态,从而在更新状态时省去了许多序列化和反序列化的开销。
举例说,在使用行动器来实现参数服务器时,参数是有状态的,在 PyTorch 中,分布式训练的每个训练进程都维护了一份参数信息,并且都各自计算出一个梯度,进程之间需要交换梯度信息以计算出总梯度和更新后的参数,这就意味着梯度需要被序列化和反序列化以便在进程间传递。而使用行动器时,整个系统中只维护一份参数信息,并且对于同一份参数的更新操作都是串行的。另外,提交参数更新的请求是非阻塞的,因此在提交完后还可以并行地去做其他 CPU 密集型的任务,这也是 Ray 框架异构性的体现。
Ray 计算模型
Ray 采用动态任务图计算模型,在这一模型中,当输入数据就绪时,系统将自动触发相应的远程函数和行动器方法的执行。本节将介绍计算图是如何在用户程序中构建的。
首先,不考虑行动器,计算图的节点可以分为两类:数据对象和远程函数调用(任务)。同样地,边也可以分为两类:数据边和控制边。
数据边用来记录数据和任务之间的依赖关系,如果数据对象 D 是任务 T 的输出,那么就增加一条从 T 指向 D 的边;反之如果是输入,则增加 D 指向 T 的边。
控制边用来记录任务之间嵌套调用的依赖关系。如果任务 T1 调用了任务 T2,则增加一条 T1 指向 T2 的边。
然后我们再考虑行动器,其方法的调用也表示为节点,它们与远程函数基本相同,只是为了记录同一行动器上的后续方法调用之间的状态依赖关系,需要增加第三种类型的边:状态边。
如果方法 Mj 紧接着 Mi 之后调用,且这两个方法属于同一个行动器,那么就增加一条 Mi 指向 Mj 的边。如此,状态边将同一行动器下的方法调用组织成链式结构,这一链式结构记录了方法的调用顺序。
下面的 Python 代码搭建了一个基本的 RL 训练框架
1 | |
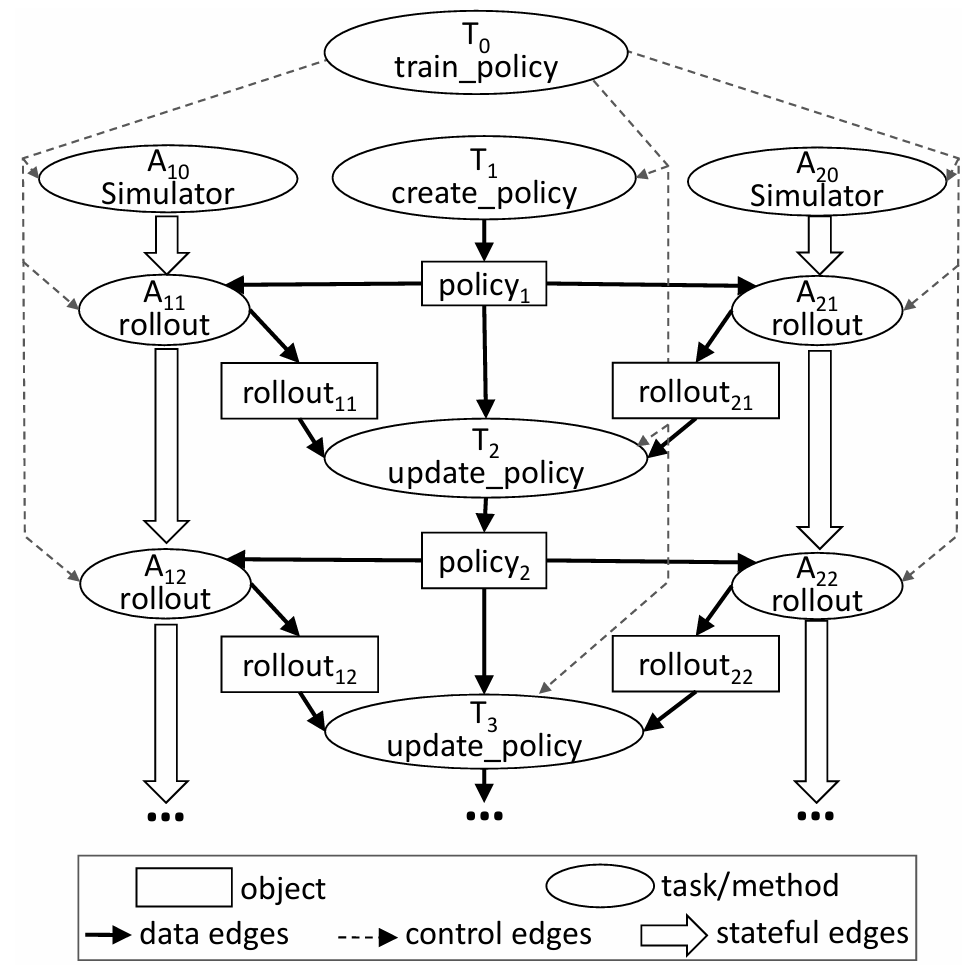
图中的主任务是 T0,T0 中创建了策略(任务),并实例化了若干个模拟器(行动器)A10,A20 (图中为了简便且不失一般性只画了两个),这些过程都是并行的。
然后进入策略评估和策略改进的循环中。策略评估需要策略作为输入,并输出 rollout 的结果,而策略改进需要策略和众多 rollout 结果作为输入。我们把 A1k,Ank 称为第 k 批 rollout,从而可以知道,每一批 rollout 都是基于同一个策略进行的,而必须等前一批 rollout 被用于更新策略后,下一批 rollout 才能基于新的策略开始。
相比完全串行的策略学习方法,这种并行化的设计主要是将 rollout 批量化并行,从而增加单位时间内采样的数量,从而加速策略改进的过程。
Ray 架构
Ray的架构由应用层和系统层组成,其中应用层实现了Ray的API,作为前端供用户使用,而系统层则作为后端来保障Ray的高可扩展性和容错性。整体的架构图如下图所示:
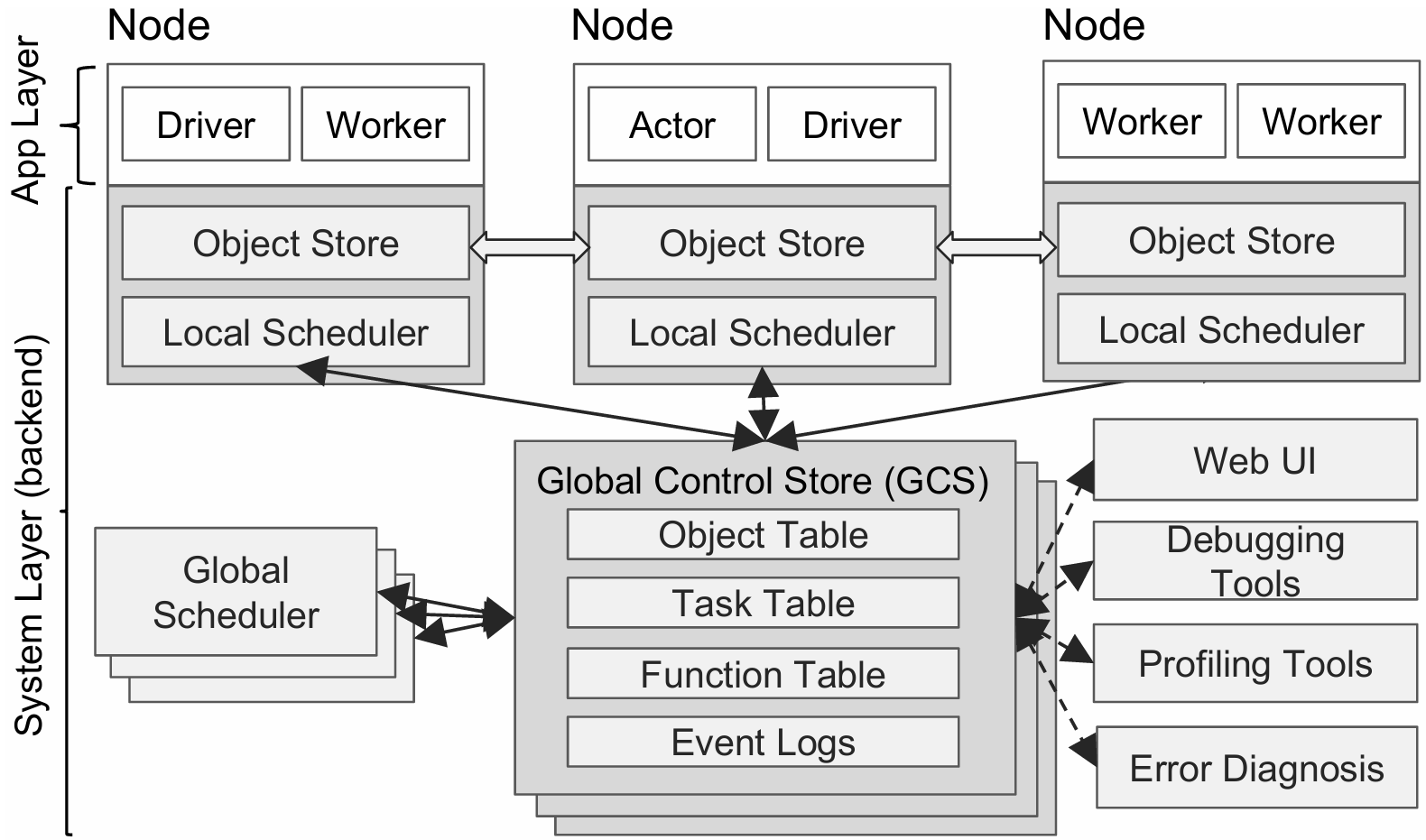
应用层
应用层中有三种类型的进程:
- 驱动器进程 (Driver): 执行用户程序的进程。所有操作都需要由主进程来驱动。
- 工作器进程 (Worker): 调用任务(远程函数)的无状态进程。Worker 由 Driver 或另一个 worker 分配任务并自动启动。当声明一个远程函数时,该函数将被自动发布到所有的 workers 中。在同一个 worker 中,任务是串行地执行的,worker 并不维护其任务与任务之间的局部状态,即在 worker 中,一个远程函数执行完后,其局部作用域的所有变量将不再能被其他任务所访问。
- 行动器进程 (Actor): actor 被调用时只执行其所暴露的方法。actor 由 worker 或 driver 显式地进行实例化。与 worker 相同的是,actor 也会串行地执行任务,不同的是 actor 上执行的每个方法都依赖于其前面所执行的方法所导致的状态。
三种进程体现到Python代码中如下:
1 | |
系统层
系统层由三个主要部件组成:全局控制存储器 (Global Control Store)、分布式调度器 (Distributed Scheduler)和分布式对象存储器 (Distributed Object Store)。这些部件在横向上是可扩展的,即可以增减这些部件的数量,同时还具有一定的容错性。
GCS
GCS 设计的初衷是让系统中的各个组件都变得尽可能地无状态,因此 GCS 维护了一些全局状态:
- 对象表 (Object Table):记录每个对象存在于哪些节点
- 任务表 (Task Table):记录每个任务运行于哪个节点
- 函数表 (Function Table):记录用户进程中定义的远程函数
- 事件日志 (Event Logs):记录任务运行日志
分布式调度器
Ray 中的任务调度器被分为两层,由一个全局调度器和每个节点各自的局部调度器组成。为了避免全局调度器负载过重,在节点创建的任务首先被提交到局部调度器,如果该节点没有过载且节点资源能够满足任务的需求(如 GPU 的需求),则任务将在本地被调度,否则任务才会被传递到全局调度器,考虑将任务调度到远端。由于 Ray 首先考虑在本地调度,本地不满足要求才考虑在远端调用,因此这样的调度方式也被称为自底向上的调度。
下图展示了 Ray 的调度过程,箭头的粗细表示过程发生频率的高低。用户进程和工作器向本地调度器提交任务,大多数情况下,任务将在本地被调度。少数情况下,局部调度器会向全局调度器提交任务,并向 GCS 传递任务的相关信息,将任务涉及的对象和函数存入全局的对象表和函数表中,然后全局调度器会从 GCS 中读取到信息,并选择在其他合适的节点上调度这一任务。更具体地来说,全局调度器会根据任务的请求选出具有足够资源的一系列节点,并在这些节点中选出等待时间最短的一个节点。
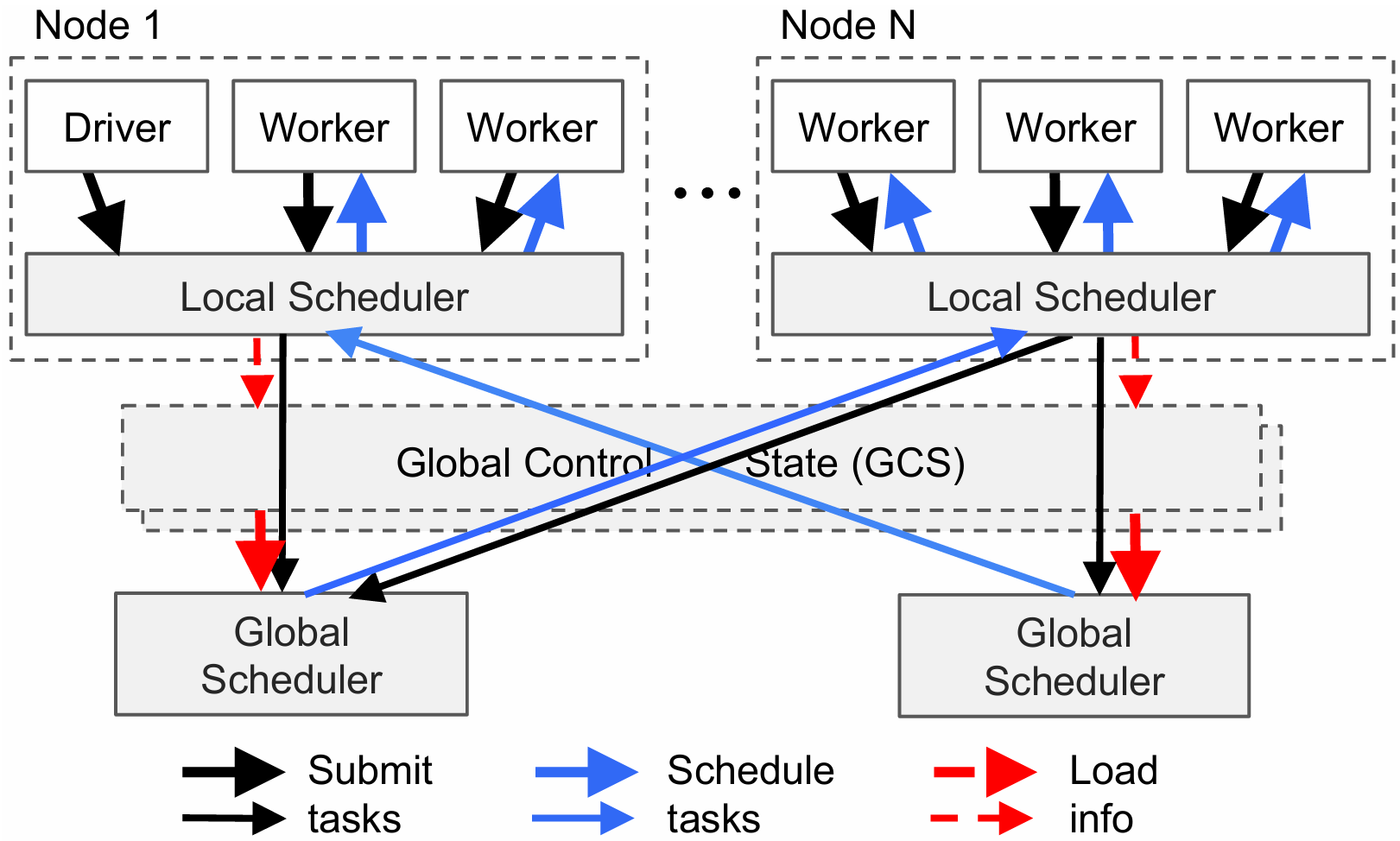
分布式对象存储器
Ray 实现了一个内存式的分布式存储系统来存储每个任务的输入和输出。Ray 通过内存共享机制在每个节点上实现了一个对象存储器 (Object Store),从而使在同一个节点运行的任务之间不需要拷贝就可以共享数据。当一个任务的输入不在本地时,则会在执行之前将它的输入复制到本地的对象存储器中。同样地,任务总会将输出写入到本地的对象存储器中。这样的复制机制可以减少任务的执行时间,因为任务永远只会从本地对象存储器中读取数据(否则任务不会被调度),并且消除了热数据可能带来的潜在的瓶颈。
案例
最后,我们来看两个实际例子来结束这篇博客:
假设有一个求两数之和的任务需要交给Ray来执行,我们来具体分析一下这一任务在Ray的架构中是如何执行的。以下以全局调度为例,因为它更具有一般性。
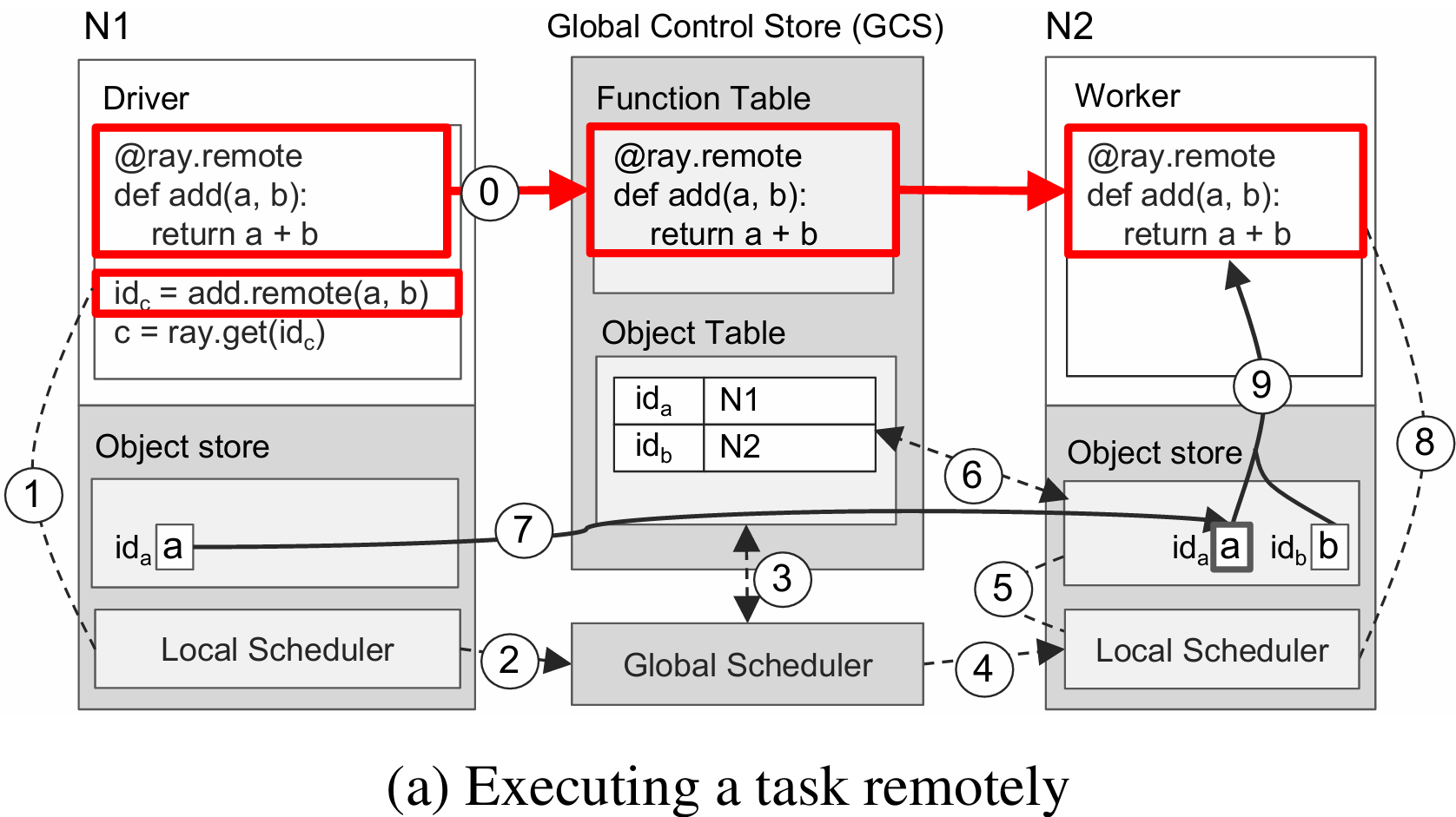
图(a)描述了任务的定义、提交和执行的过程
- 【定义远程函数】位于 N1 的用户程序中定义的远程函数add被装载到GCS的函数表中,位于 N2 的工作器从 GCS 中读取并装载远程函数add
- 【提交任务】位于 N1 的用户程序向本地调度器提交 add(a, b) 的任务
- 【提交任务到全局】本地调度器将任务提交至全局调度器
- 【检查对象表】全局调度器从GCS中找到add任务所需的实参a, b,发现 a 在 N1 上,b 在 N2 上(a, b 已在用户程序中事先定义)
- 【执行全局调度】由上一步可知,任务的输入平均地分布在两个节点,因此全局调度器随机选择一个节点进行调度,此处选择了 N2
- 【检查任务输入】 N2 的局部调度器检查任务所需的对象是否都在 N2 的本地对象存储器中
- 【查询缺失输入】 N2 的局部调度器发现任务所需的a不在 N2 中,在 GCS 中查找后发现 a 在 N1 中
- 【对象复制】将 a 从 N1 复制到 N2
- 【执行局部调度】在 N2 的工作器上执行add(a, b)的任务
- 【访问对象存储器】add(a, b)访问局部对象存储器中相应的对象
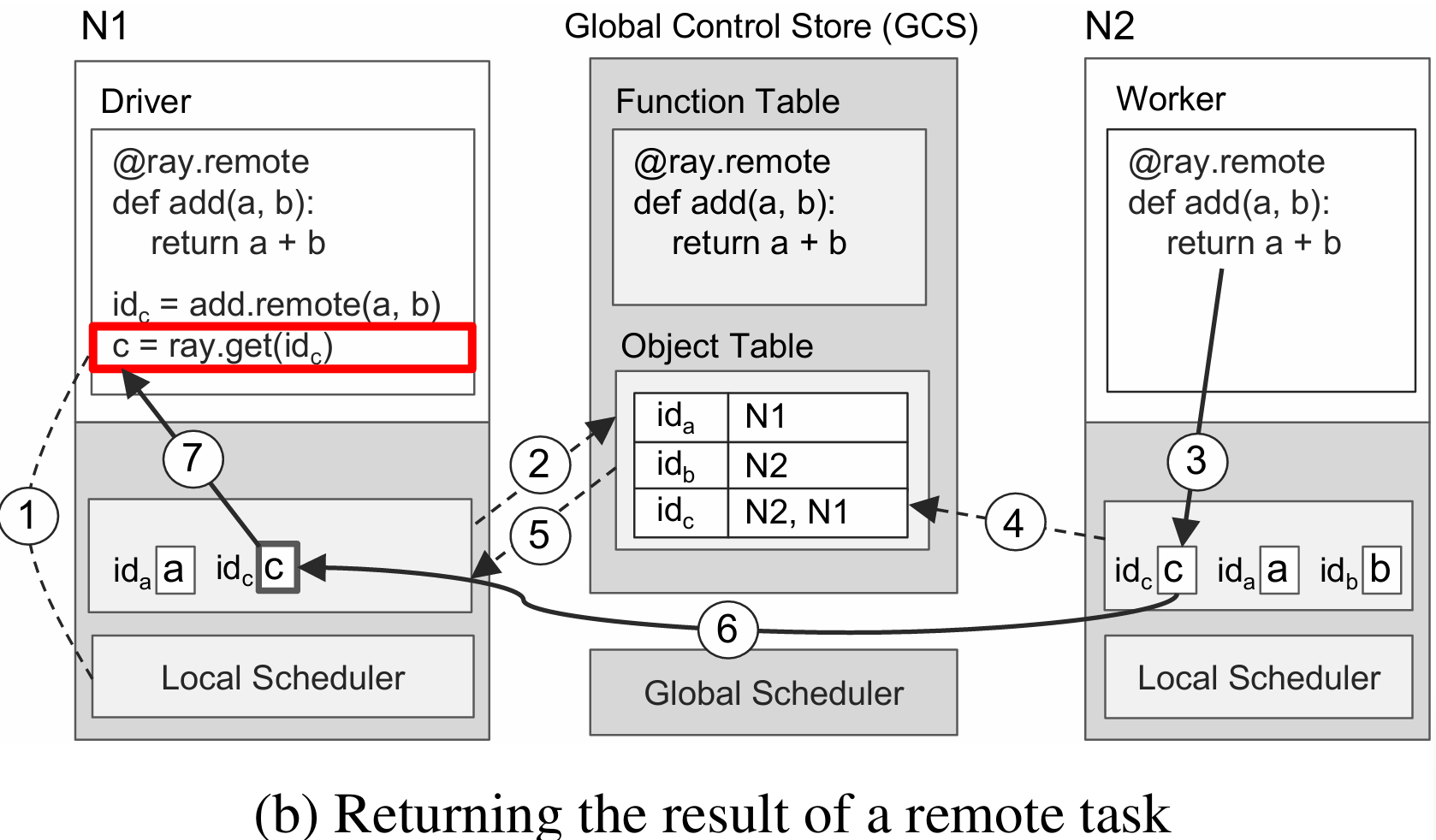
图(b)描述了获取任务执行结果的的过程
- 【提交get请求】向本地调度器提交 ray.get 的请求,期望获取 add 任务执行的返回值
- 【注册回调函数】 N1 本地没有存储返回值,所以根据返回值对象的引用 id_c 在 GCS 的对象表中查询该对象位于哪个节点,假设此时任务没有执行完成,那么对象表中找不到 id_c,因此 N1 的对象存储器会注册一个回调函数,当 GCS 对象表中出现 id_c 时触发该回调,将c从对应的节点复制到 N1 上
- 【任务执行完毕】 N2 上的 add 任务执行完成,返回值c被存储到 N2 的对象存储器中
- 【将对象同步到GCS】 N2 将 c 及其引用 id_c 存入 GCS 的对象表中
- 【触发回调函数】2中注册的回调函数被触发
- 【执行回调函数】将c从 N2 复制到 N1
- 【返回用户程序】将c返回给用户程序,任务结束