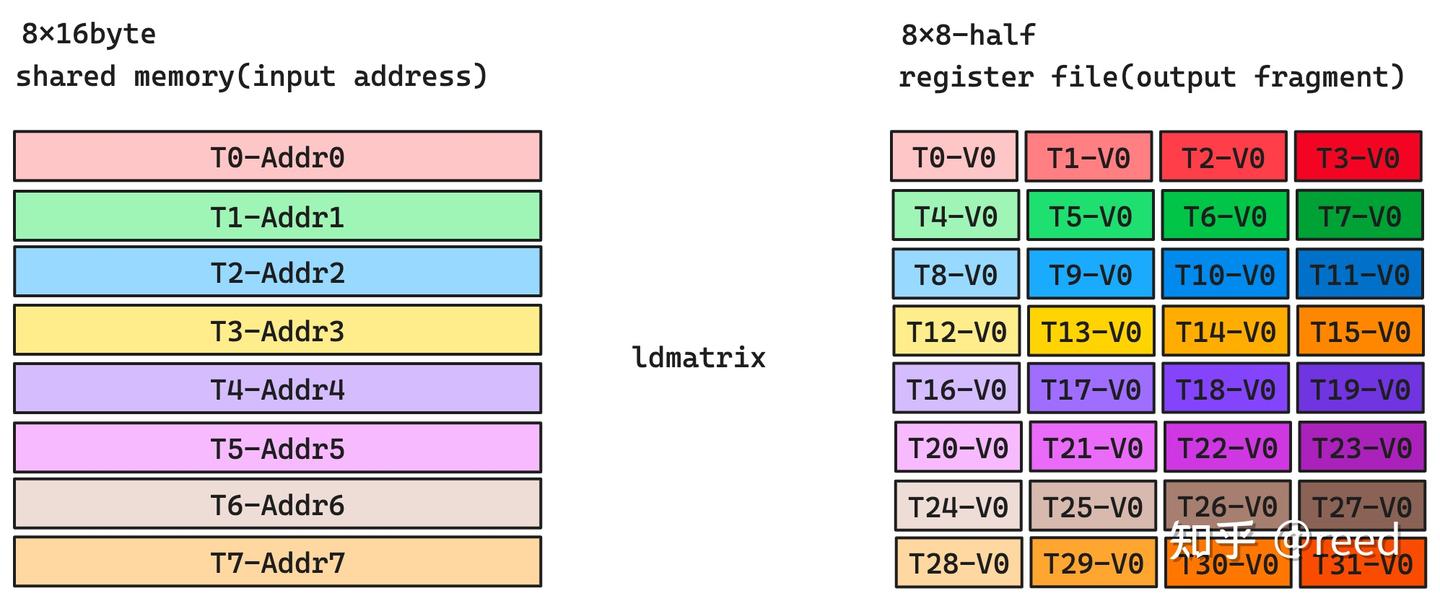
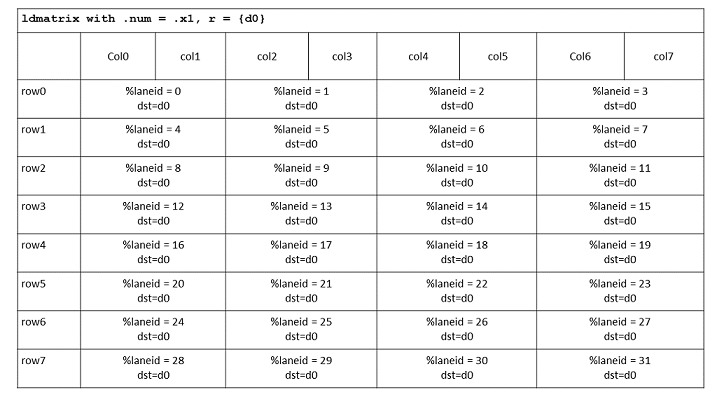
constint lane_id = threadIdx.x % 32; // First, we get the current thread id in the warp uint32_t r[4]; // Allocate 4 registers for each thread uint32_t load_smem_ptr = __cvta_generic_to_shared( // convert generic address(pointer) &src_matrix[lane_id % 16][(lane_id / 16) * 8] // to share space offset, often used ); // in PTX which requires shared space offset rather than pointer LDMATRIX_M8N8_X4(r[0], r[1], r[2], r[3], load_smem_ptr);
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c; mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c; mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k4.row.col.f32.tf32.tf32.f32 d, a, b, c; mma.sync.aligned.m16n8k8.row.col.f32.atype.btype.f32 d, a, b, c; mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32 d, a, b, c; mma.sync.aligned.shape.row.col.dtype.f8type.f8type.ctype d, a, b, c; mma.sync.aligned.m16n8k32.row.col.kind.dtype.f8f6f4type.f8f6f4type.ctype d, a, b, c;
首先假设,我们已经从 global memory 中加载了矩阵 A 和 B,并放在了 shared memory 中。于是我们就只剩下将他们从 shared memory 中加载到寄存器中,再进行矩阵乘法了!
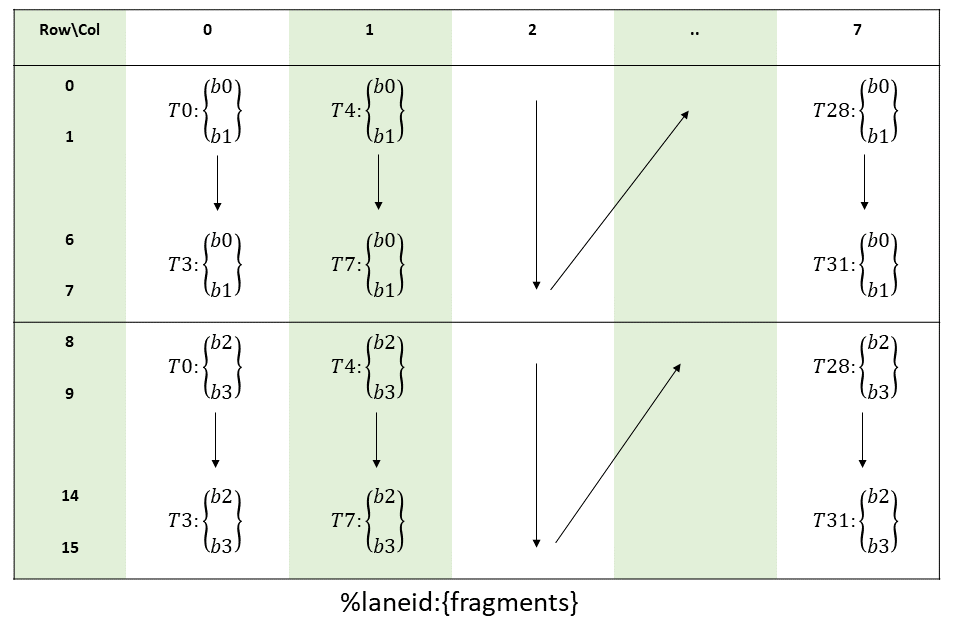
考虑到矩阵 A 的大小是 16x16 的 bf16 矩阵,于是和之前的 ldmatrix 例子一样,我们使用 ldmatrix.sync.aligned.m8n8.x4.shared.b16 将矩阵 A load 到寄存器中:
1 2 3 4
constint lane_id = threadIdx.x % 32; // First, we get the current thread id in the warp uint32_t ra[4]; // Allocate 4 registers for each thread uint32_t load_a_smem_ptr = __cvta_generic_to_shared( &asrc_matrix[lane_id % 16][(lane_id / 16) * 8] ); LDMATRIX_M8N8_X4(ra[0], ra[1], ra[2], ra[3], load_smem_ptr);
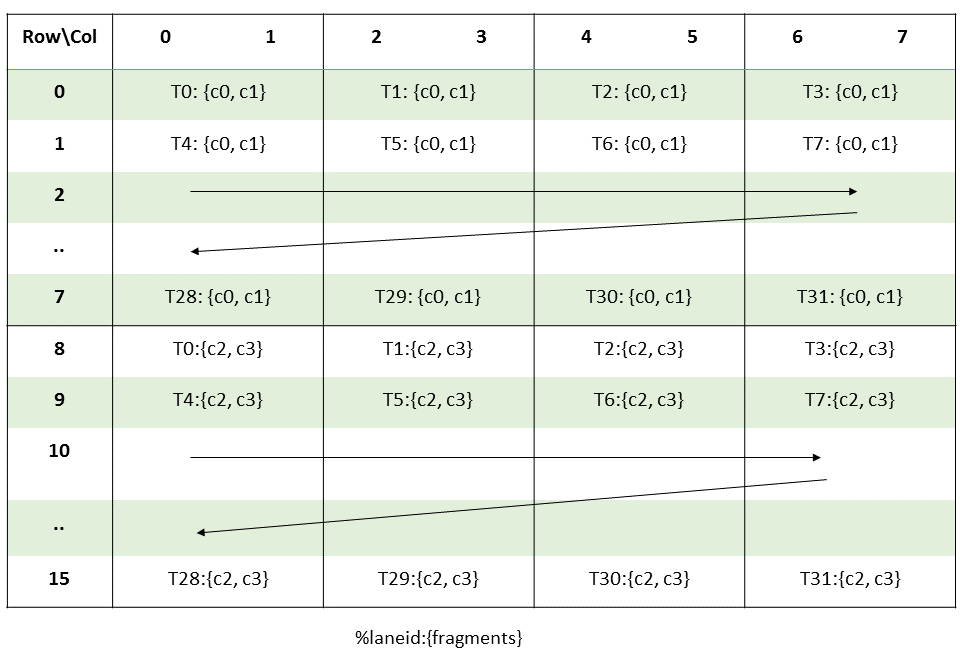
那么对于矩阵 B 来说,情况也是类似的,但需要额外注意的是,矩阵 B 是 Trans 的,有 16 行 8 列,所以要用 ldmatrix.sync.aligned.x2.trans.m8n8.shared.b16,而为了配合 MMA 的 B layout,也需要让线程 0-15 读取 shared memory。
constint tid = threadIdx.y * blockDim.x + threadIdx.x; // within block constint lane_id = tid % WARP_SIZE; // 0~31
// s_a[16][16], 每行16,每线程load 8,需要2线程,共16行,需2x16=32线程 constint load_smem_a_m = tid / 2; // row 0~15 constint load_smem_a_k = (tid % 2) * 8; // col 0,8 // s_b[16][8], 每行8,每线程load 8,需要1线程,共16行,需16线程,只需一半线程加载 constint load_smem_b_k = tid; // row 0~31, but only use 0~15 constint load_smem_b_n = 0; // col 0 constint load_gmem_a_m = by * BM + load_smem_a_m; // global m constint load_gmem_b_n = bx * BN + load_smem_b_n; // global n if (load_gmem_a_m >= M && load_gmem_b_n >= N) return;
uint32_t RC[2] = {0, 0};
#pragma unroll for (int k = 0; k < NUM_K_TILES; ++k) { // gmem_a -> smem_a int load_gmem_a_k = k * BK + load_smem_a_k; // global col of a int load_gmem_a_addr = load_gmem_a_m * K + load_gmem_a_k; LDST128BITS(s_a[load_smem_a_m][load_smem_a_k]) = ( LDST128BITS(A[load_gmem_a_addr]));
// gmem_b -> smem_b if (lane_id < MMA_K) { int load_gmem_b_k = k * MMA_K + load_smem_b_k; // global row of b int load_gmem_b_addr = load_gmem_b_k * N + load_gmem_b_n; LDST128BITS(s_b[load_smem_b_k][load_smem_b_n]) = ( LDST128BITS(B[load_gmem_b_addr])); } __syncthreads();
// store s_c[16][8] if (lane_id < MMA_M) { // store 128 bits per memory issue. int store_gmem_c_m = by * BM + lane_id; int store_gmem_c_n = bx * BN; int store_gmem_c_addr = store_gmem_c_m * N + store_gmem_c_n; LDST128BITS(C[store_gmem_c_addr]) = (LDST128BITS(s_c[lane_id][0])); } }