ncompute 学习与使用
ncompute 使用示例
准备工作
- 机器设备:NVIDIA GeForce RTX 4060 laptop
- CUDA 环境:12.4
- docker 环境:nvcr.io/nvidia/pytorch:24.05-py3
我简单地写了一个 elementwise 的 kernel 函数,并使用 ncu 对其做性能分析
1 | |
用如下命令编译并执行:
1 | |
就可以获得 ncompute 的相关性能数据输出。这篇文章中,我们从这些性能数据出发,尝试寻找一个适配于当前环境的最佳性能实践。
性能数据一览
elementwise_add_f32_kernel
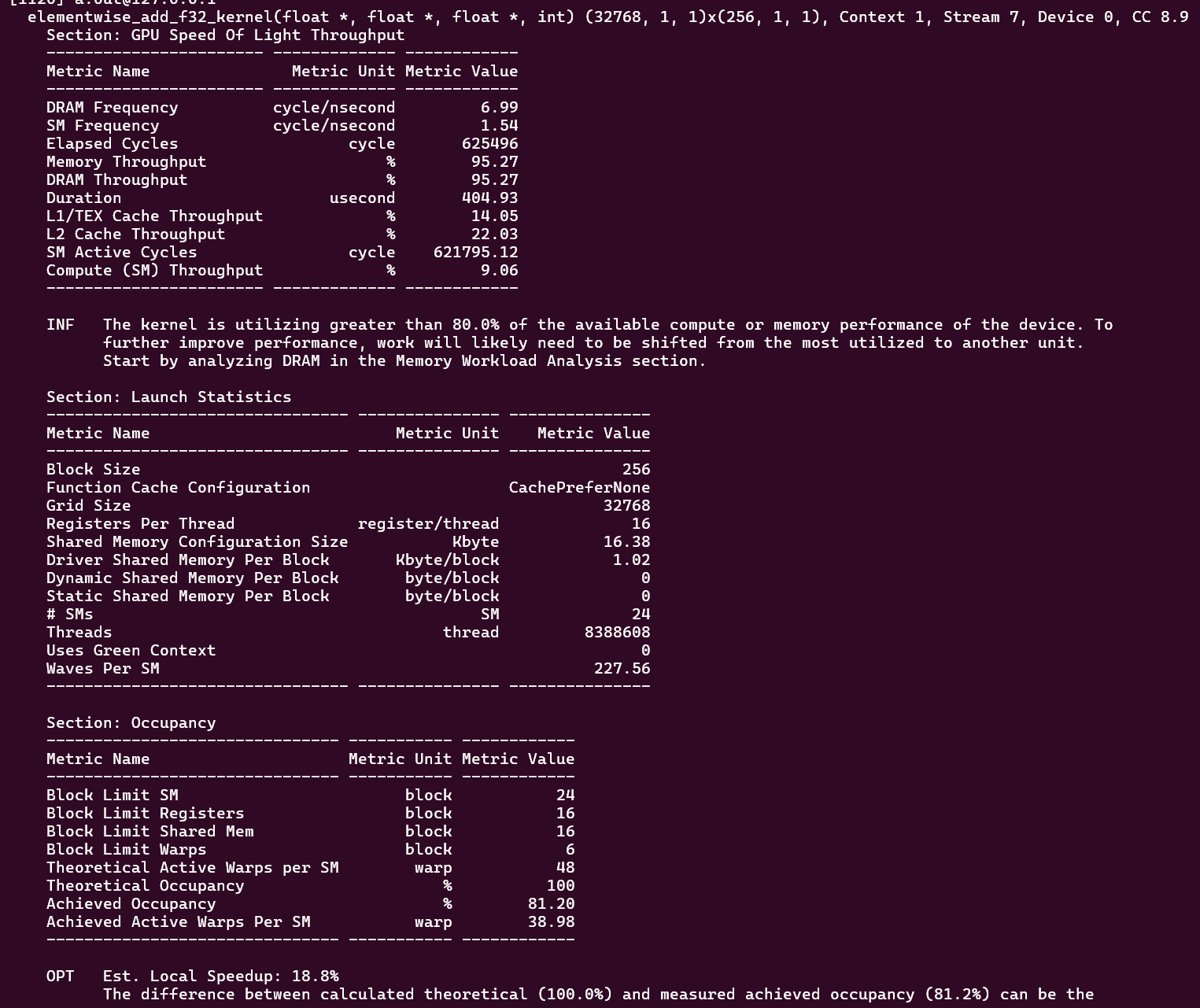
我们从上往下看,注意到在 Section: GPU Speed Of Light Throughput 中:
- 表示内存数据传输吞吐量的 Memory Throughput 高达 95.27%
- 而计算的吞吐量(Compute (SM) Throughput)仅有 9.06%。
注意,这可不是说明内存数据传输的利用率高,计算的利用率低。恰恰相反,这是说明该 kernel 函数的性能瓶颈在内存数据搬运上。因此我们后续要针对该 kernel 作性能优化,必须先从优化数据 load 开始。
再来看下一节表格的数据 Section: Launch Statistics。这个表格主要介绍了 kernel 启动时的统计数据。我们重点看下面的数据:
- Waves Per SM: 227.56
- SMs: 24
- Block Size: 256
- Grid Size: 32768
- Threads: 8388608
- Registers Per Thread: 16
- Shared Memory: 16.38 KB
- Warps = 32 个 threads
这些数字与我们调用的线程数量和设备中的 SM 数息息相关。首先,在软件层面,我们使用 cuda 调用 (32768, 256)=8388608 个线程来执行 elementwise_add_f32_kernel 函数。
而 device 中其实仅有 24 个 SMs,无法同时启动这么多线程来执行 kernel 函数。于是,device 必须多次循环使用这 24 个 SMs,来完成多线程的“并行”计算,一次循环在 CUDA 中被称之为 wave,waves per SM 记录了为了完成这个 kernel 函数,每个 SM 平均执行了多少个 waves。
那么一个 SM 可以执行多少个线程呢?这个取决于每个线程消耗了多少资源。因为一个 SM 中的资源都是固定的,这都是在芯片出厂后就确定下来的,无法随意改变。因此,每个线程消耗的资源多,那么一个 SM 可以同时执行的线程数量就少,反之则 SM 可以同时执行更多的线程。
一个 SM 可以执行多少个线程需要从下面的 Section: Occupancy 得出:
- Block Limit SM:24 blocks
- Block Limit Registers:16 blocks
- Block Limit Shared Mem:16 blocks
- Block Limit Warps:6 blocks
- Theoretical Active Warps per SM:48 warps
从上面的数据可以得到:若从 SM 角度看,由于设备限制,每个 SM 最多可激活 24 个 blocks,所以此处 Block Limit SM 是 24;若从 Registers 角度看,由于设备限制,每个 SM 最多可激活 16 个 blocks,所以此处 Block Limit Registers 是 16;若从 Shared Mem 角度看,由于设备限制,每个 SM 最多可激活 16 个 blocks,所以此处 Block Limit Shared Mem 是 16;若从 Warps 角度看,由于设备限制,每个 SM 最多可激活 6 个 blocks,所以此处 Block Limit Warps 是 6。
为了满足所有资源的可用,我们必须取上面几个 limit 里的最小值,我们可以得到一个 SM 最多只能启动 6 个 blocks,而先前我们规定一个 block 有 256 个线程,即 8 个 warps,所以说,一个 SM 最多可以启动 6 * 8 = 48 个 warps,正好对应了 Theoretical Active Warps per SM。
更进一步,我们可以发现,因为一个 SM 最多可以启动 48 个 warps,即 48 * 32 = 1536 个线程,那么 24 个 SMs 可以启动 1536 * 24 = 36864 个线程,而我们总共需要启动 8388608 个线程,所以一共需要 8388608 / 36864 = 227.56 个 waves 来完成,也能正好对应 Waves Per SM。
当然,前面的分析都只是理论计算,ncompute 中还定义了占用率这个概念:
占用率(Occupancy) = 每个 SM 中激活的 Warp / 每个 SM 可以激活的 Warp 的最大值。
在本例中,理论上每个 SM 可以启动 48 个 Warps,但实际激活的 warps 数只有 38.98,于是占用率为 81.20%。
elementwise_add_f32x4_kernel
从上面的数据中可以看出,
- kernel 函数的性能瓶颈在内存数据搬运上。因此需要充分利用内存带宽。
- 线程块分配得过大,线程数量过多,进而导致 wave 数量过多。
优化的点在于 CUDA 的访存行为上。在 CUDA 内部,一个访问内存事务(transaction)会消耗 128 bit 的内存带宽,而 elementwise_add_f32_kernel 函数中一次仅 load 一个 32 bit 的 float。
我们可以写一个让线程一次性 load 4 个元素的程序,增加内存访问事务的利用率。
1 | |
这个函数中,宏定义 FLOAT4 可以将四个 float 一起打包成 float4 数据类型,这样线程在 load 时就可以一次性读取四个 float 数据。
再次用同样的方法编译和执行,得到 ncompute 输出的数据:
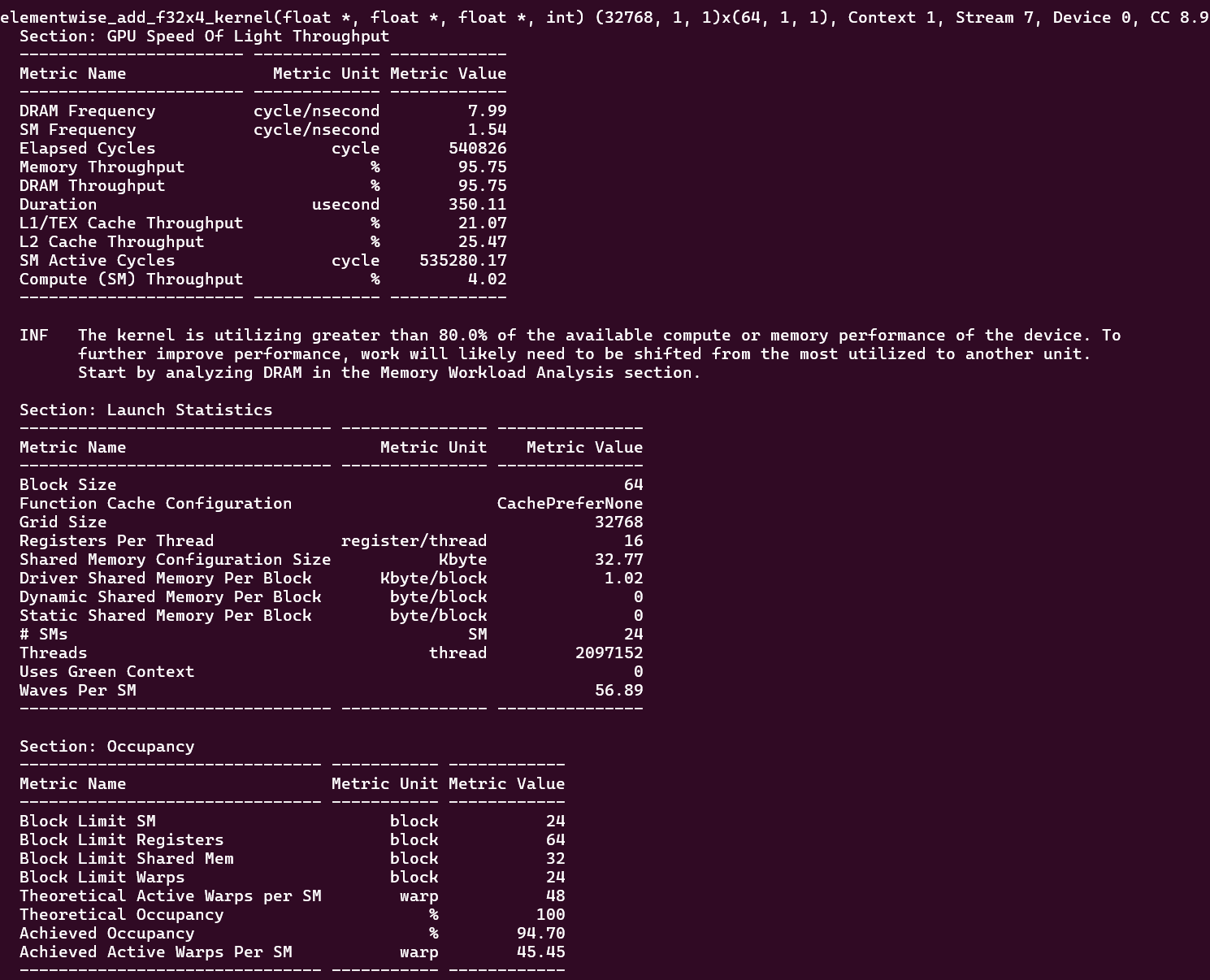
我们发现,因为线程一次性 load 4 个 float,总共 128 bits,能完全利用 CUDA 中一次 memory transaction 的带宽。读入数据都为有效数据,也因此,L1/L2 cache 的命中率更高。最后, elementwise_add_f32_kernel 总共需要 625496 个 cycles,而优化 elementwise_add_f32x4_kernel 总共仅需 540826 个 cycles。
再看 Occupancy 表格,我们发现,因为线程块大小为 64,即 2 个 warps,所以 Block Limit Warp 改为了 24,但一个 SM 理论上可以激活的 warps 无法改变,最多为 48 个。因为线程数量减少了 4 倍,所以 waves Per SM = 227.56 / 4 = 56.89 ,Occupancy 提高到了 94.70 %。