GraphRAG 框架
引言
对于大模型的应用而言,也许最大的挑战就是让它回答一些在预训练和后训练时从未知晓的领域的问题(比如你昨天的日记、商业公司内部的机密文档等私有数据)。目前,业界解决该问题的方案之一就是使用检索增强生成(RAG),RAG 是一种利用大模型(LLMs)对私有数据文献的检索、理解和生成的 AI 回答技术。虽然传统的 RAG 技术可以很好地帮助大模型回答基于私人数据的问题,但它无法进一步地理解私有数据中各个有效信息的关系,从而构成自己的知识网络,因此难以提供综合性的见解,也无法全面理解多个私有文献甚至单个文档的全部内容,因此往往无法回答抽象或总结性问题。
几个月前,微软开源了一个新的基于知识图谱构建的 RAG 系统——GraphRAG。graphrag 框架旨在利用大型语言模型从非结构化文本中提取结构化数据,进而构建具有标签的知识图谱,以支持数据集问题生成、摘要问答等多种应用场景。 GraphRAG 的一大特色是利用图机器学习算法针对数据集进行语义聚合和层次化分析。但与其他知识图谱不同的是, GraphRag 不单单关注于提取结构化数据和对其的结构化检索,还优先关注于这两方面:模块化(inherent modularity) 和社区检测算法。GraphRag 使用社区检测算法将整个知识图谱划分模块化的社区(包含相关性较高的节点), 然后大模型自下而上对社区进行摘要, 最终再采取 map-reduce 方式实现基于 query 的总结回答(Query-Focus Summarization),即每个社区先并行执行 query, 然后汇总成全局性的完整答案,因此 GraphRag 可以回答一些相对高层级的抽象或总结性问题。
框架概述
工作流程
让我们先总览地看一下 graphrag 的具体流程。下图是 graphrag 论文中给出了工作过程的总体情况。与其他 RAG 系统类似,GraphRAG 整个 Pipeline 也可划分为索引(Indexing 左半部分)与查询(Query 右半部分)两个阶段。索引过程利用 LLM 提取出节点(如实体)、边(如关系)和协变量(如 claim),然后利用社区检测技术对整个知识图谱进行划分,再利用 LLM 进一步总结。最终针对特定的查询,可以汇总所有与之相关的社区摘要生成一个全局性的答案。
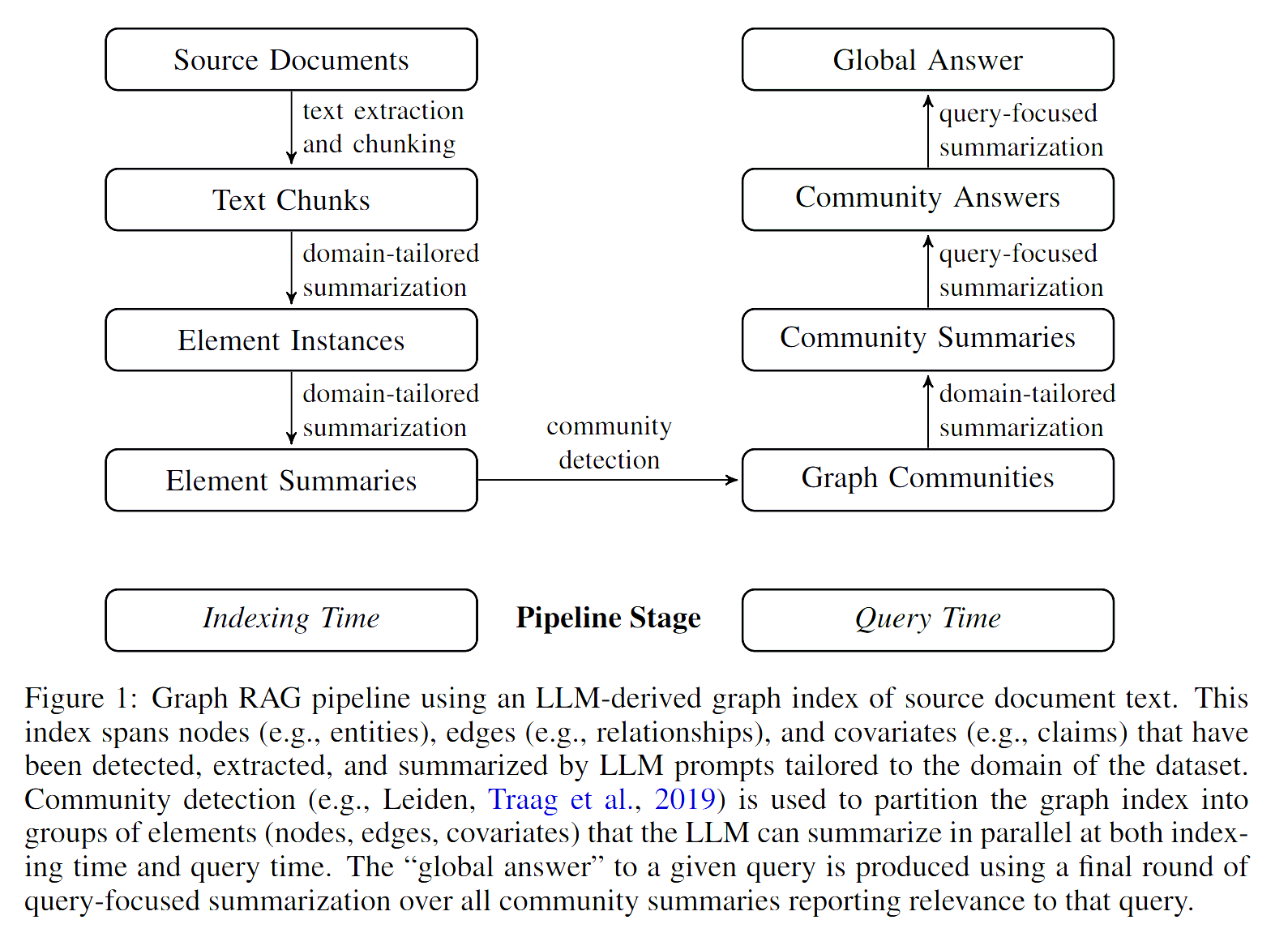
接下来我们一步步地具体解释其流程。
文件切割为文件块
首先是将输入的原文档变成一个结构化的知识图谱,但显然,用户输入的大量文件太多太长无法直接处理。因此需要将输入的文档分割为若干个大小相同的文件块(text chunk)。这些文件块后续会被喂给 LLM 来提取其中的信息。
因此,文件块的大小设计很有讲究。更大的文件块会更少地调用 LLM,加快索引过程,但也更容易因过长的文件块而产生信息召回率下降。
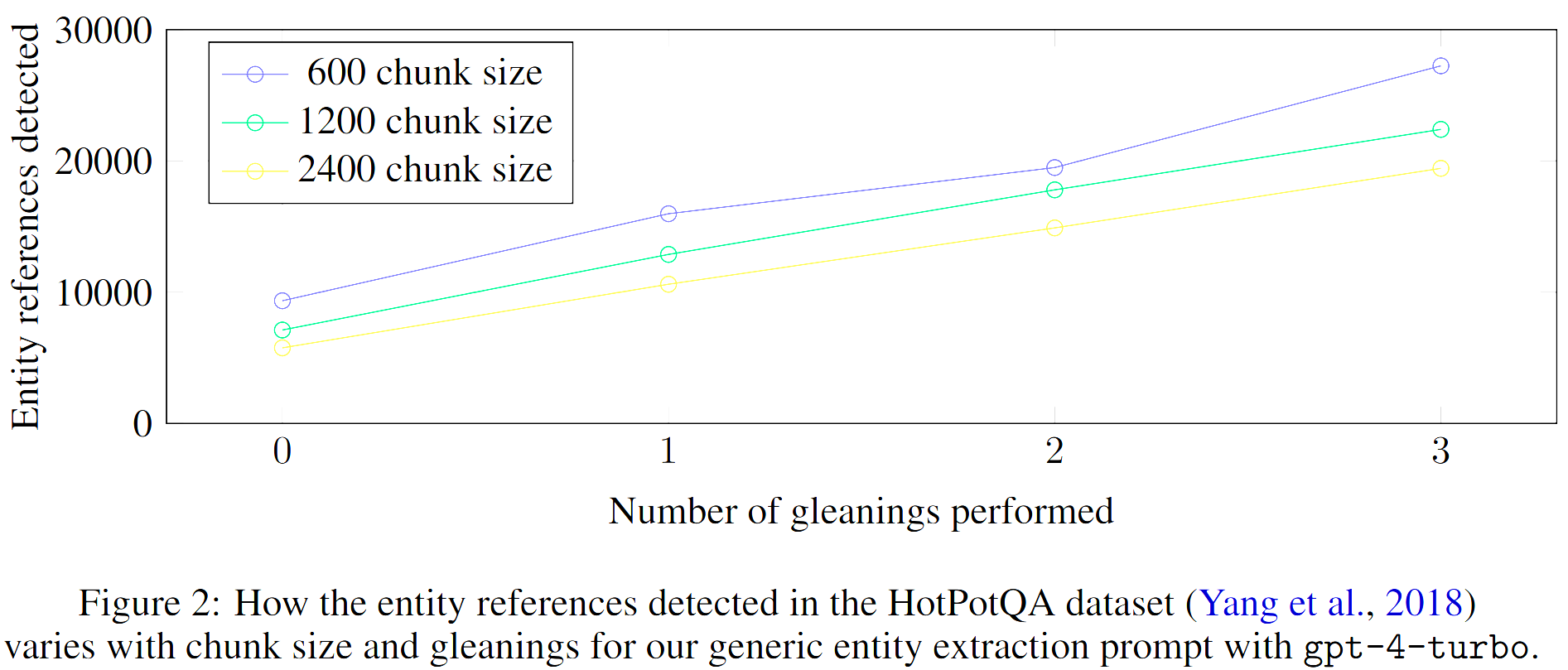
论文指出,在样本数据集 (HotPotQA, Yang et al., 2018) 上,使用 600 个 token 的块大小提取的实体连接引用几乎是使用 2400 个 token 的块大小的两倍。虽然引用越多越好,但任何提取过程都需要平衡目标召回率和准确率。
图中的 gleanings 指 graphrag 对文本的多轮信息采集,这是为了让 LLM 尽可能不遗漏任何实体(entities)。graphrag 会首先要求 LLM 自查是否提取了所有实体,如果 LLM 回应说遗漏了,那么 graphrag 会继续鼓励 LLM 收集这些缺失的实体。这种方法允许我们使用更大的块大小,而不会降低质量(图 2)或强制引入噪音。(ps:好狠的 PUA)
文件块到图元素
然后,graphrag 需要从文件块中识别和提取 graph node 和 edge。它会首先识别文本块中的所有实体,包括其名称、类型和描述,这些实体会被当作 graph node。然后明确相关的实体之间的所有关系,包括源实体和目标实体以及它们的关系描述,用来表示 graph edge。两种元素实例都输出在一个分隔元组列表中。
看到这你可能会怀疑,LLM 是否真的具备实体辨识能力(Named Entity Recognition)。事实上,LLM 一直具备此能力,这个 youtube 上的视频可以帮助你打消这个顾虑。
然而,对于一些专业知识领域(例如科学、医学、法律专用词),LLM 就需要一些 few-shot 例子才能更好地完成这个任务,此外 graphrag 还支持针对 graph node 关联的其他协变量的二次提取 prompt。默认的协变量 prompt 旨在提取与实体相关的信息,包括主题、对象、类型、描述、源文本跨度以及开始和结束日期等。
图的构建与元素总结
从文本块中提取到 entities,以及他们的属性、相互关系后,就可以建立出 graph 了。可以将这些 entities 作为图的 node,相互关系是图的 edge。整张图就是同构无向权重图,
当然 graphrag 不会主动将这些图展示给用户看,用户若用兴趣,需要去指定的目录下读取对应的文件后,使用neo4j 图数据库来看。这些内容我们可以下次细聊。
从另一个角度理解,可以认为 graph 内的 node 和 edge 中的内容本身就是对文本的一次总结。然而,要生成所有这些元素的总结摘要,即每个图元素(实体节点、关系边和声明协变量)的描述性文本块,还需要对匹配的图例组做进一步的 LLM 总结。
图社区
到此为止,我们的图已经构建起来了,现在需要使用分层社区检测算法来识别图中的社区。
社区是指图中彼此紧密连接的但与其他节点连接稀疏的节点集合。
在 graphrag pipeline 中,使用的是 Leiden 算法,因为它能够有效地构建大规模图的分层社区结构。图中存在多个层次结构,每个层次都提供了一个级别的社区划分,且这些社区是互斥、完全地覆盖图的所有节点,从而为下一步实现社区总结提供支持。
更多关于社区算法的介绍,读者有兴趣可以看这篇博客。
社区总结
要对一个社区内部的信息做总结,首先要找出图的中心节点(即那些有很多边连接的对该社区十分重要的节点)。
然后,需要将这些中心节点的所有相关信息和关系都结合到一起,最后总结提取的信息,使用 LLM 生成社区总结。
具体来说,算法会自下而上地对社区做总结,首先是最低层级的 leaf-node 社区做总结,找到中心节点,搜集他们相关的信息,提取后使用 LLM 生成社区总结。对于高层级的社区,则递归地利用低层级社区生成的总结来做总结,一环套一环,最终产生整张图的总结内容。
检索与回答问题
到现在为止,graphrag 还在处理内部的图数据,还没有回答用户的 query 呢!所以之前的步骤其实可以离线完成的。但从这步开始,用户的 query 会被 graphrag 处理,这就必须在线完成了。graphrag 会用 LLM 来处理用户 query,并寻出与该 query 相关的关键 node 和 edge(LLM 真的好忙)。
随后,需要从相关的node和edge中提取信息,可以使用子图提取的方式:将 query 涉及到的 node 和 edge 的整个子图(社区)内容都提取出来;也可以做适度的上下文扩展,将内容做适度延伸;还可以按照相关度评分,从高到低地搜集信息作总结回答等。
这其中仍有不少细节问题值得探讨。虽然我们可以不断地使用社区总结来最终产生一个总结性的回答,但很多时候这并不是用户想要的。在用户查询全局回答时,我们可以从非常多的角度(社区层级)来寻找答案,并最终找到一个细节与范围的最好平衡点。
最后,对于一个给定的社区级别,任何用户查询的全局答案生成过程有如下几步:
- 准备社区总结。离线产生的社区总结会被随机打乱并分成若干文本块,以确保相关信息能均匀分布在块中,而不是集中(集中意味着可能丢失)在一个上下文窗口中。
- 映射社区答案。并行地给每个块生成中间答案,此外 LLM 还需要给生成的答案对回答是否有帮助进行打分,分数为 0 的答案将被过滤掉。
- 简化为全局答案。中间答案会按照 LLM 的打分做降序排列,并迭代添加到新的上下文窗口中,直到达到 token 数量限制。最终的上下文用于生成返回给用户的全局答案。
实例演示
说了这么多,可能会让各位读者觉得有些抽象,接下来我们用具体例子给大家做个说明,来自这篇博客的精彩示例:
- 知识图谱创建
假设我们要处理一大堆科学文献要处理,并从中挑选出感兴趣的词汇,比如说“蛋白质” 、“基因”、“疾病”,并且用“导致”,“与之影响”等关系相连。
那么,graphrag 需要首先将这堆科学文献做切分,分为一个个文本块,然后读入并构造知识图谱的节点,即代表某种蛋白质或者基因或者疾病的节点,然后再用边来表示他们的关系。
当然,这些图中的节点或边关系等是需要 LLM 反复从文本块中提取出来的,这也同样解释了为什么 graphrag 的离线操作会非常耗时耗算力。
- 社区总结生成
使用分层的社区检测算法来分析这张图,最后获得一个个层次分明,且能清晰指出与蛋白质、基因和病毒相关的社区群。
对于每个社区,它的中心节点(例如是某个关键蛋白质)可以被识别出来,并由 LLM 给出它的属性、效果、相互影响的社区总结。
- graphrag 检索
然后,就到了在线处理用户 query 的环节。假设我们要处理用户的 query 是关于一个特定蛋白质与某种疾病的关系的问题。
那么,我们可以提取出包含该特定蛋白,以及该疾病,和他们相关的实体的子图。
当然,该子图也包括了需要的上下文:比如某些与之紧密关联的实体和关系。
结合子图给的这些信息,我们可以让 LLM 产生一个综合性的答案,来解释该蛋白质和疾病的关系。
源码解析
官方文档写得已经很清楚了, 不过想要理解一些实现上的细节, 还得深入到源码当中. 接下来, 一块看下代码的具体实现. 项目源码结构树如下:(未完待续)
1 | |
总结
GraphRAG 使用 LLM 创建全面的知识图谱,重点使用了社区算法描述了文档内的实体及其关系。GraphRAG 能够利用知识图谱内的数据和图结构,对需要广泛理解整个文本的复杂查询做出准确的响应。在本篇博客文章中,我先介绍了 GraphRAG 的基本运行流程,然后介绍了 graphrag 框架的源码设计,希望能为大家深入理解 graphrag 有所帮助。