VLLM Paged Attention 实现
Paged Attention 简介
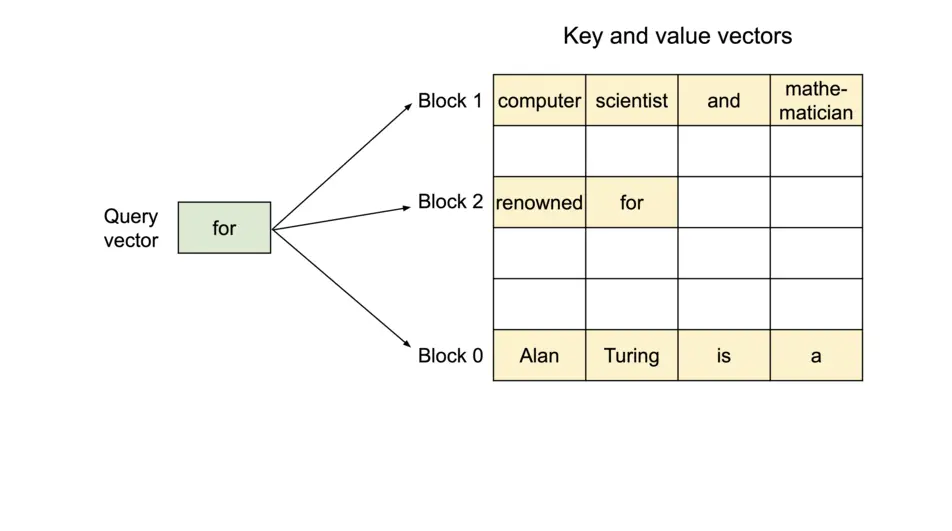
Paged Attention 是 vllm 在 decode 阶段用来解决 KV cache 利用率不高的加速技术。它仿照了操作系统中经典的分页技术(paging)。Paged Attention 通过切分一个 sequence 序列中的 KV cache 为多个 KV blocks 的方法,允许在非连续的内存空间存储连续的 key 和 value。每一个 KV block 会存储一定数量 tokens 的 K,V 向量,这样就将原本 KV cache 切分成一块块 KV blocks,如下图所示:
为了获得更快的性能,VLLM 针对 attention kernel 有专门的内存布局和访问设计,尤其是线程从全局内存中读取数据到共享内存的环节。
今天,我们来一起看一下 VLLM 对于 Paged Attention 的具体实现细节,本文参考 vLLM Paged Attention。本文涉及到的 VLLM 代码版本为 0.5.3。
输入
先来看一下 paged_attention_kernel 的总入口:我们先要理解一下函数的输入输出情况
paged_attention_kernel 的声明
1 | |
可见,该 kernel 函数需要读入许多参数,用于当前线程执行。其中最重要的三个参数是输入指针 q、k_cache 和 v_cache,它们指向全局内存中需要读取和处理的 query、key 和 value 数据,输出指针 out 指向全局内存,结果会存放在该处。这四个指针实际上是多维数组的引用,但每个线程只访问分配给它的数据部分。
在函数声明中,还有一系列的模板参数值得我们注意,这些参数是在编译时确定的。scalar_t 表示 query、key 和 value 数据元素的数据类型,例如 FP16。HEAD_SIZE 表示每个头部中元素的数量。BLOCK_SIZE 指的是每个块中 token 的数量。NUM_THREADS 表示每个线程块中线程的数量。PARTITION_SIZE 代表张量并行GPU的数量(为简单起见,后文都假设此值为0,即禁用了张量并行)。
从注释中,我们获得了几个有用信息:
| 张量名字 | 维度 | 描述 |
|---|---|---|
| out | (num_seqs, num_heads, head_size) | 注意力计算结果 |
| q | (num_seqs, num_heads, head_size) | query 张量 |
| k_cache | (num_blocks, num_kv_heads, head_size/x, block_size, x) | key cache 张量 |
| v_cache | (num_blocks, num_kv_heads, head_size, block_size) | value cache 张量 |
了解完函数的输入后,我想先解释一些后续部分需要用到的概念。对基本概念的完全理解可以帮助我们更好地理解代码实现
概念
如果你遇到任何困惑的术语,你可以跳过这一节并稍后返回。
-
Sequence:Sequence 可以理解为客户端的一个请求,包括了与大模型对话的语句。例如,由
q指向的数据具有形状[num_seqs, num_heads, head_size]。这表示总共有num_seqs个查询 sequence 数据被q指向。由于 paged attention kernel 只是一个在 decode 阶段才会被使用的注意力函数,因此计算时每个 sequence 只会有一个 query token。因此,num_seqs等于 batch 中处理的所有 token 总数。 -
Context:context 包括从 sequence 已经生成的 tokens。例如,
["What", "is", "your"]是已经产生的 context token,输入 query token 为"name"。那么下一步,模型可能会生成 token"?"。 -
Vec:vec 是被一个线程一起的 load 到内存并执行计算的元素数组。对于 query 和 key 张量,vec 大小(
VEC_SIZE)是通过计算一个 thread group 一次 load 和计算 16 字节单位的数据多少来确定的。对于 value 张量,则根据一个 thread 一次 load 和计算 16 字节数据量来确定V_VEC_SIZE大小。例如,如果scalar_t为 FP16(2字节)且THREAD_GROUP_SIZE为 2,则VEC_SIZE将为 16/2/2=4,而V_VEC_SIZE将为 16/2=8。
1 | |
-
Thread group:Thread group 就是一小组(
THREAD_GROUP_SIZE个)线程,它们一次 load 并计算一个 query 和 key token 的 QK。注意:Thread group 中的一个线程只处理一部分 token 数据!下面的图示中我们会看到这样的例子。而又因为一个 token 向量维度往往较大,会在 cacheline 上跨越多个 bank,所以线程读取数据时更偏向于条状方式(tiled)读取。我们将一个 thread group 处理的元素总数记为x。例如,如果线程组包含 2 个线程,并且 head size 为 8,那么 thread 0 处理会index 为 0、2、4、6 的 query 和 key token,而 thread 1 处理 index 为 1、3、5、7 的 token。 -
Block:vLLM paged attention 最关键的实现就是分块存储 key value。每个 block 存储了固定数量(
BLOCK_SIZE个 head token) 的 tokens。注意,一个 Block 里的 token 是不完整的,是只包括了一个注意力头的 token 数据!每个 block 可能只包含 context 中部分的 tokens。例如,如果 block 大小是 16,head size 是 128,那么对于一个注意力头,一个 block 包含了 16*128=2048 个元素。相比之下,大模型一层 transformer 可能有 32 个注意力头,hidden size 为 4096(即 token 向量维度)。 -
Warp:CUDA中,一个 warp 包含了 32 个线程(
WARP_SIZE),它们在流多处理器(SM)上同时执行。在这个 kernel 中,每个 warp 一次处理一个 query token 和整块的 key tokens 之间的计算(可能会在多次迭代中处理多个块)。例如,如果有 4 个 warps 和 6 个 blocks 用于一个 context,则分配如下:warp 0 处理第 0、4 号块,warp 1 处理第 1、5 号块,warp 2处理第2号块,而warp 3 则处理第 3 号块。 -
Thread block:线程块是一组可以访问相同共享内存的线程(
NUM_THREADS)。每个线程块包含多个 warps(NUM_WARPS),在本 kernel 函数中,一个线程块处理一个 query token 和整个 context 的 key tokens 的计算。 -
Grid: grid 由线程块组成,在本 kernel 函数中,grid 的维度为
(num_heads, num_seqs, max_num_partitions)。因此,每个线程块只负责处理一个头部、一个 sequence 的一个分部。当然,我们这里先假设 partitions 为 1,不分部。
线程与数据的布局层次
| 线程层次 | 数据层次 | 备注 |
|---|---|---|
| Grid | batch 内所有 sequence | 一次计算 num_seqs 个 sequence |
| Thread Block | sequence | 一次计算 一个 query 和整个context 的 key tokens |
| Warp | KV block token | 一次计算一个 query 与整块 key token |
| Thread group | token | 一次计算一个 query 与一个 key token |
| Thread | part of token | 一次计算部分 query 与 部分 key token |
Query
这一节来介绍一下 query 张量的内存布局以及如何被线程 load 并计算的过程。上文提到过,每个 thread group 会 load 一个完整的 query token 张量,因此分摊到每个线程只会 load 部分 token 张量。而在一个 warp 中,所有的 thread group 都会 load 相同的 query token 张量,同时也会 load 多个同一 KV block 内的不同的 key token 张量。
1 | |

上图所示的是一个注意力头中,一个 query token 的数据,当 VEC_SIZE 是 4,HEAD_SIZE 是 128, 那么就包含了一共 128 / 4 = 32 vecs。在每个线程内,定义了一个线程私有的 q_ptr,指向它需要 load 的 query token 数据,见下图,每一行都是一个线程 load 的 token 数据。

1 | |
这些线程组织起来,我们就需要一个 q_vecs 来管理它们。注意,q_ptr 指向的是全局内存 query,cuda 程序会将它们 load 到共享内存,组成 q_vecs 数组。每个线程负责处理 q_vecs 中一行的数据。上图中,如果 THREAD_GROUP_SIZE 是 2, thread 0 则会处理第 0 行的 vecs,而 thread 1 处理第 1 行 vecs。这样读取 query 数据的好处是,相邻的线程能读取到相邻的内存数据,利用了内存合并(memory coalescing)获得性能上的提升。
这部分内容理解起来不算困难,但请大家记住这一个例子:
VEC_SIZE是 4HEAD_SIZE是 128V_VEC_SIZE将为 8- thread 0 load 了 vec0 vec2 vec4 等偶数项
Key
与上节相似,这一节我们介绍一下 key 张量的内存排布以及 load 过程。上文提到,每个 thread group 只会处理一个 query token,但要多个 key tokens 参与计算。而每个 warp 会多次循环,以处理每个 KV block 的 key token,从而确保所有 context tokens 被一个 thread group 计算到(即将 query 与所有相关 key 做点乘)。
1 | |
与 q_ptr 不同,在每次循环中,每个线程的 k_ptr 指向的是不同 key token 张量。就如上面的代码所述,physical_block_offset 就是 block 内的偏移量,k_ptr 的值取决于 KV cache 的 block 块,kv head 和现在读到的 kv token 偏移。

上面这张图解释了 key 张量的内存布局。我们假设 BLOCK_SIZE 为 16,HEAD_SIZE 是 128,x(即一个 thread group 处理的元素个数)是 8,THREAD_GROUP_SIZE 是 2,这里一共有 4 个 warps。可以看出,左半部图中 block0 有 16 个 token 编号 0-15,每个 token 内有 32 个 vec。右半边图展示了 4 个 warps 分别处理不同的 block,四个一循环后 warp0 的下一个外循环会处理 block4。每个大矩形代表一个注意力头计算时需要的 key token 数据,它们由一个 thread group 完成计算。
还记得之前请大家记住的例子么,这里的数据沿用了之前的例子,所以 thread 0 仍然 load query token 的 vec0 vec2 vec4 等偶数项,相对应地,thread 0 还 load 了 key token 的偶数项。load 完成后,可以直接计算它们的 QK 值了。

1 | |
下面,我们来看一下从 k_ptr 全局内存读入 key token,存储到 k_vecs 的寄存器内存。k_vecs 之所以使用寄存器内存是因为它一次只会被一个线程访问,而上文介绍的 q_vecs 会被多个线程多次访问。每个 k_vecs 会包含多个 vec 用于后续计算。每个 vec 在内循环中使用。同一 warp 内的相邻线程可以一起将相邻的 vecs 的读取进来,这里又利用了内存的 CUDA 内存合并以提升性能。举例说明,thread 0 读取 vec0,thread 1 读取 vec1,在下一个内循环中,thread 0 读取 vec2,thread 1 读取 vec3。
也许你会对上面的过程感到困惑,不必担心,接下去的 QK 节会更详细、清晰地解释 query 和 key 如何完成计算过程。
QK
在 query 部分,我们用代码展示了,在程序准备计算之前,会用一个 for 循环 load 一个 query token,并存放在 q_vecs 内。然后,这里有三层循环来描述 QK 的计算过程。在最外面的循环控制着 KV block 的变更,对应了 key 章节图中的右半部分。在第二层循环中,k_vecs 会被循环地指向不同的 tokens,而在最内循环中 k_vecs 会去一个个地 load 对应的 key vec。最后在第二层循环中计算 q_vecs 和 每个 k_vecs 的点乘运算。
1 | |
之前提到,对于每个 thread,它一次只会读入部分 query 和 key token 张量。然而,在计算 Qk_dot<>::dot 内部,thread group 内所有线程都已经执行了 reduction。 所以 qk 返回的结果不是部分 query 和 key,而是整个 query 和 key token 的点乘相加的结果。
例如,如果 HEAD_SIZE 是 128,THREAD_GROUP_SIZE 是 2,每个线程的 k_vecs 就会包含总共 64 个元素。然而,计算返回值 qk 实际上是 128 个 query 元素和 128 个 key 元素的点乘值。
接下来,我们来仔细看看 Qk_dot<>::dot 的实现,看它是否如上面文字描述的那样完成了这些计算和归一。因为 Qk_dot<>::dot 最终调用了函数 qk_dot_,我们直接来看它的实现。
1 | |
前半部分就是在计算 q 和 k 张量的内积。
最后的部分归一值得一看,它使用了我之前文章里介绍的使用蝶式算法并行求和的方法。每个线程同其相邻的线程完成数字交换,并相加,一层层地迭代计算后,最终所有线程都计算得到了总和值。
__shfl_xor_sync(uint32_t(-1), var, lane_mask) 是 CUDA 线程束内的 shuffle 指令,它通过对线程调用者的 ID 进行按位异或来计算目标线程的 ID,并获得目标线程的变量值。
Softmax
计算完 qk 值后,我们需要计算这些值的 softmax,下面的公式展示了 softmax 计算的具体过程,其中 x 表示 qk 返回的值。为了计算 m(x),我们必须获得 qk 张量的 reduced 值 qk_max ,以及 exp_sum值 。当然,这些 reduced 值必须横跨整个 thread block 来获得,因为前文我们说过,只有整个 thread block 才有 query token 和整个 context 的 key token。
这与理论计算中的 softmax 公式有略微的区别,主要是因为防止 exp 计算出来的值过大导致溢出,因此在计算前需要用一个最大值减去。
qk_max and logits
得到了 qk 值的计算结果后,我们可以将临时地用 logits 数组存放 qk 的结果。当然,最后 logits 变量应当是归一化后的值。随后,我们在 thread group 中先计算出 qk_max 的值:
1 | |
注意,logits 变量位于共享内存上,所以每个 thread group 会在同一 logits 数组的不同 token 位置完成赋值。最终,logits 数组的长度应当就是 context token 的长度。
1 | |
紧接着,VLLM 仍使用之前的蝶式求和法,将每个 warp 中的最大 qk_max 值找到。即让每个相邻的线程进行通信,比较出最大的 qk_max 值,最终获胜的一定是最大值。
1 | |
同样的方法,我们在 thread block 中比较每个 warp 的 qk_max 值,这样我们就能获得整个 thread block 的 qk_max,然后,我们需要将它广播给所有线程。
exp_sum
与 qk_max 的计算方法类似,我们也需要获得整个 thread block 的 reduced 求和值。
1 | |
首先,我们在一个 thread group 内求和得到所有 exp 值的总和。但首先,需要将 logits 数组内的 qk 值(上一步我们存放的)转变为 exp(qk-qk_max)值。请注意,上一步的 qk_max 已经被广播给了所有 thread,因此这一步是可以完成的。
然后,我们可以对 exp_sum 做归一求和,使用之前一样的蝶式求和法。两个线程做通信,求得各自的 exp_sum 和即可。
1 | |
最后,当我们求得了 exp_sum 后,就可以计算出最终的归一 softmax 值,并存放到 results。该变量会在后续的步骤中被用于与 value 张量做点乘运算。
Value
在执行完前文描述的步骤后,现在它们已经获得了 logits 数组了,又因为 QK 的计算会被 reduce 到 warp 上所有的线程,以及 4 个 warp 对所有 context 的 block 的遍历,所以每个线程现在都有 HEAD_SIZE * BLOCK_SIZE 个 logits 值。
搞明白了这个前提后,再来看看 value 张量的内存布局和 load 情况吧。



先来看第一张图,虽然 value 部分不涉及到 thread group 的东西,但为了理解方便图中仍然画出了两个 thread,这是之前计算 QK 时留下的一组 thread group。
我们需要检索 value 张量,然后计算与 logits 的点乘了。不像 query 和 key,value 处理数据是跨 token 的,它会同时计算不同 token 的数据,且没有涉及到 thread group。第一张图中展示了 value 的内存排布,同一列的元素对应着同一个 value token,不同列就是不同的 token 了。
对于一个 block 的 value 数据,它有 HEAD_SIZE 行和 BLOCK_SIZE 列,每个部分都被分成 v_vecs。其中 thread 0 则 load 了 32 的倍数的 v_vec,thread 1 则 load 了 32 的倍数余 1 的 v_vec。在之前举出的例子中,v_vec 的大小为 8,因此图二画了 8 个 vec,每个 vec 分别对应了不同的 token。
再来重点关注最后一张图,每个线程一次从 V_VEC_SIZE 个 token 中 load V_VEC_SIZE 个元素。以 thread 0 为例,在内循环中,它会检索多个不同行但同一列的 v_vecs 。对于每个 v_vec,他需要与相应的 logits_vec 做点乘,这里 logits_vec 变量就是上节计算得到的 V_VEC_SIZE 个 logits 的数组元素。总的来看,多个内循环中,每个 warp 会处理一个 block 的 value tokens,经过多个外循环后,整个 context value token 都会被计算到。
1 | |
从上面的代码可以看到,在外层循环,与 k_ptr 有些类似,logits_vec 会先读取不同 blocks 的 logits 数据,读取 V_VEC_SIZE 个元素用于内循环的计算。在内循环中,每个 thread 读取了 V_VEC_SIZE 个 token 的元素,存放在 v_vec 中,最后计算点乘。重要的是,每个内循环中,thread 会 load 相同 8 个 token 下的不同的注意力头元素。点乘计算出来的值会被累加到 accs 中。因此 accs 变量会被映射到对应 thread 的注意力头处。
还是上面的例子, BLOCK_SIZE 是 16,V_VEC_SIZE 是 8,每个 thread 会一次 load 8 个 value 数据给 8 个 tokens。这些数据是来自不同 token 。若 HEAD_SIZE 是 128,WARP_SIZE 是 32,那么对于每个内循环,一个 warp 会需要 load WARP_SIZE * V_VEC_SIZE = 256 个元素。这意味着这个 warp 总共需要 128 * 16 / 256 = 8 个内循环来计算整个 block 的 value 值。每个 thread 中的 accs 则会包含 8 个元素的相加,这 8 个元素是来自 8 个不同的注意力头位置,比如上面的图中, thread 0 的 accs 变量包含了 8 个元素,它们分别来自 0th, 32th … 224th 元素的注意力头,它们都会被累加起来并赋值给 8 个 tokens。
LV
现在,我们已经将每个 warp 这些点乘值累加起来,存放到 accs 中。下面我们要进一步累加这些 accs 值,并在一个 block 中累加给所有注意力头的位置。
1 | |
然后,我们需要计算所有 warps 的 acc 的归一求和值,然后让每个 thread 都有注意力头位置处的 accs 的所有 context token 的最终求和值。注意,每个 thread 的 accs 变量仅保存了整个注意力头中部分元素的累加值。不过,经过上面的计算后,所有输出结果都会被计算出来,存放再不同线程的寄存器内存中。
1 | |
Output
现在我们可以将计算得到的结果从寄存器内存中写到全局内存中。
1 | |
首先,我们需要定义 out_ptr 变量,它的地址取决于相关 sequence 和注意力头的起始地址。
1 | |
最后,我们需要循环多次,将不同的注意力头位置都写到相对应的累加结果上,并返回 output_ptr。
VLLM 代码实现
以 llama3-8b 为例,
参数与数据结构
参数解释与 llama3-8b 的相关数据情况:
| 参数 | llama3-8b 中的值 | 描述 |
|---|---|---|
| num_seq | 4(batch_size) | 该推理中 sequence 个数 |
| num_head | 32 | Query 的 head 个数 |
| num_kv_heads | 8 | Key、Value 的 head 个数 |
| hidden_size | 4096 | 输入的嵌入张量维度 |
| head_size | 128 | 每个注意力头的维度大小 |
| x | 2(FP16) | 数据类型的字节数 |
| scaling | 128^-0.5 | 注意力公式中的scale值 |
Paged Attention 算法相关的辅助数据结构:
block_size KVCache page 的最高维,KVCache 是若干个 page 的集合,每个 page 存(block_size, num_head,head_size)个 K、V 的元素。
context_lens [num_seqs] 用于变长
max_num_blocks_per_seq
q_stride
kv_block_stride
kv_head_stride
q_vecs
head_mapping [num_heads] 用于 MQA, GQA,确定用的 KV_head
block_tables [num_seqs, max_num_blocks_per_seq] block_tables 映射表,表示每个 sequence 映射到哪几个 block 上