VLLM custom allreduce 实现
vllm custom allreduce 实现
动机
用过 vllm 执行大模型的读者应该很清楚, vllm 使用张量并行(tensor parallel)的方式执行多卡推理。在 Self-Attention 和 MLP 层会将张量分布到各个 GPU worker 上计算,因此各个 GPU 上计算的只是一部分矩阵乘的数据,故完成计算后所有的 GPU worker 需要将结果“汇总”起来,即执行 allreduce,才能获得所有的结果,进而开始后续的操作(比如 dropout 或者 layernorm)。
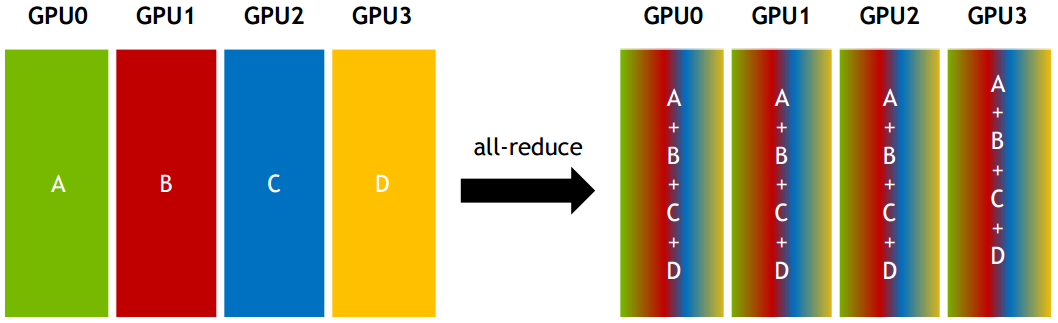
也就是说,执行一次有 N 层 LLM 的推理,多个 GPU worker 间就需要执行至少 次 allreduce。考虑到 N 通常为 32-128 之间,且执行 allreduce 会阻塞后续模型的推理进度,因此 allreduce 性能会直接影响 vllm 多卡推理的效率。
而在 decoding 阶段,对于一个 sequence 来说,vllm 的一次推理只会推出一个 token,因此 decoding 阶段的 allreduce 的通信的数据量非常小。我们以 llama2-70b 模型在推理 batch size 为 32 时的场景为例,其decoding 阶段需要的 allreduce 通信数据量仅为 KB。可见即使在 70B 大模型上运行较大的 batch size 所带来的通信量也是非常少的。
在没有 vllm custom allreduce 时,我们会直接使用 nvidia GPU 的 NCCL 通信库来完成 allreduce。但是,对于上述小 size 的 allreduce 场景,NCCL 存在以下问题:
- 多 stage,不是延迟最优的。NCCL 实现的带宽最优的树或环状 allreduce(具体实现可以参考 Ring Allreduce,它们分别具有 O(logn) 和 O(n) 个阶段传输过程(n 为 GPU 数)。考虑到现代 nvidia GPU 间的巨大带宽(A100 的有效双向带宽有 480 GB/s !), NCCL 实现的 allreduce 显然更适合大数据传输的场景,对于小 size 场景,我们更希望其延迟中的启动传输(或同步)时间更少,而不必担心数据真正的传输时间太长。
- 不利于内核融合。NCCL 对于 vllm 开发人员来说是黑盒,很难被进一步融合优化。而如果 vllm 使用自己的内核,那么就能更轻松地做算子融合操作
- CUDA graph 不友好。NCCL 的 cuda graph 需要插入同步主机的节点,这会阻塞 GPU,导致 GPU 流出现间隙:

机制
缓冲区注册
CUDA IPC (Interprocess Communication) 支持每个 GPU 节点拥有一个指向其他 GPU 节点内存的指针。显然,我们可以使用这些指针来完成 allreduce 操作。具体步骤是,首先在初始化的过程中就先将每个节点的一个 buffer 暴露给其他节点,组成一个 IPC handle,然后在做 allreduce 时,节点只需要从其他所有节点的 buffer 中读取数据即可。
one-shot allreduce
allreduce 有非常多算法。在小 size 场景下,为尽可能减少 GPU 同步和收发时间,我们当然希望直接了当一些:直接让所有节点的数据同时广播给其他节点。这就是 one-shot allreduce
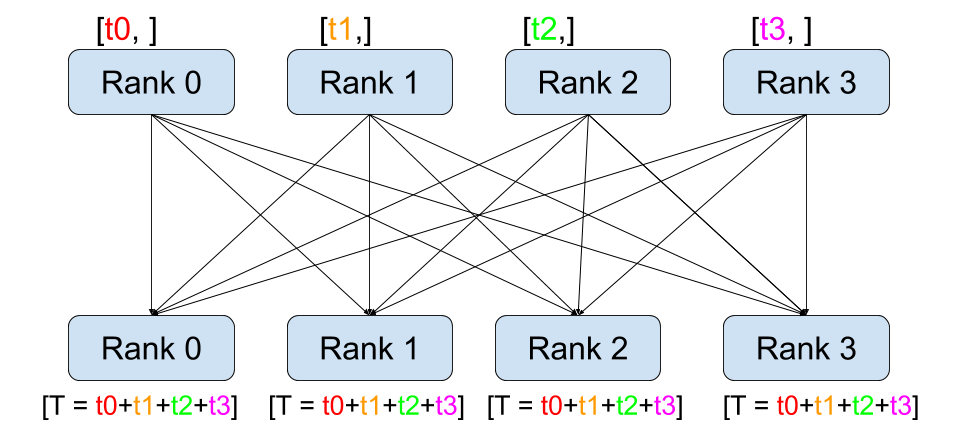
one-shot allreduce 的性能关键设计一个自定义对齐数据类型,方便让每个节点能都快速地读取 allreduce 数据。最好是 128 bits 对齐,因为每个 CUDA 线程一次会读取 16 字节,好让编译器生成 LD.128 和 ST.128 指令。
two-hop allreduce
在稍微大一些的 size 或节点稍多的场景下,直接让所有节点广播就不太合适了。two-shot allreduce 先执行 reduce scatter,让每个节点从所有节点那读取对应的 1/N 的数据,然后加起来。然后,在做一个 allgather,将所有节点的数据发送给其他节点。

代码解读
本博文涉及的 vllm 代码为 0.6.3,请注意时效性。
python 开始
Linear 层到 allreduce
首先,让我们回到最初的地方,当多卡 TP 执行推理时,计算 MLP down_proj 等会涉及到了我们目前研究的 custom allreduce:
1 | |
该函数的实现在 vllm/distributed 内
1 | |
最终,经过几次辗转调用后,python 代码最终接入到 CustomAllreduce 类的地方就是:
1 | |
allreduce 使用前提
现在,我们再来仔细看 CustomAllreduce:
1 | |
可以确定, Custom Allreduce 特性仅支持在 2,4,6,8 卡上推理时才能打开,并且最大支持的 allreduce size 为 8 MB。这里的 allreduce size 指的是 MLP 在各个 GPU 上计算出来的张量大小。
1 | |
若我们打开 custom allreduce 特性,custom_all_reduce 会先执行 should_custom_ar ,之后的逻辑可以分为三条
- 一条是
self._IS_CAPTURING为 True,使用all_reduce_reg,在 CUDA graph capture 该 stream 流调用 - 一条是
self._IS_CAPTURING为 False,使用all_reduce_unreg,在不是 CUDA graph 或者 CUDA graph 未 capture stream 流调用 - 最后是 warm up 时的计算,可以忽略
先来看 should_custom_ar 来确定 allreduce 的使用前提:
- 一条是
self._IS_CAPTURING为 False,使用all_reduce_unreg - 最后是 warm up 时的计算,可以忽略。
这两个函数 all_reduce 函数我们先按下不表,我们先来看 should_custom_ar 来确定 allreduce 的使用前提:
1 | |
不难发现,should_custom_ar 在如下条件会返回 False,allreduce 传输的 tensor 大小不是 16 对齐的,或者不是弱连续(连续或有前置偏移的连续),或者运行环境中有四张以上的非 NVLink 的 GPU 卡。
总结一下,Custom allreduce 特性在如下条件全部满足方可使用:
- 用户没有手动 disable,即未传入
disable_custom_all_reduce=True - 机器上有 2,4,6,8 GPU 卡,且当有四张及以上的卡时,他们必须使用 NVLink 连接
- allreduce 的张量大小不超过 8 MB,必须 16 Byte 对齐,必须满足连续条件
Python 到 C++
之前我们提到,vllm kernel 内的通信数据,是通过每个节点上的 CUDA IPC buffer 来交流实现的。本着怀疑主义的精神,我们来深入追踪一下,当前节点下的 CUDA 进程如何获得其他节点的 IPC buffer 的指针的。
其关键就藏匿于下面的代码中。
1 | |
逐一地解释一下这些变量,因为它会在下面的篇幅中反复出现,准确地理解它对我们读懂 vllm custom allreduce 实现至关重要。
metaPython 类 owned 的 buffers,可以理解为整个 Python 类的所有字节,包括两部分,用于 GPU 间数据通信的 256 字节和用于暂存 allreduce 数据的 bufferbuffer用于在该节点上的 CUDA IPC 的暂存数据的 bufferrank_data用于接受来自其他节点 CUDA IPC 数据的 bufferrank当前节点号world_size目前机器下的 GPU 总数
C++ CustomAllreduce
后续的指令做了非常重要的几件事,我们一个一个来看:
通过 CPU 广播所有节点的 IPC handles
1 | |
_get_ipc_meta 通过在 CPU 上调用 torch.distributed.broadcast_object_list 的广播手段,使得
handles获得了所有其他节点的 ipc handler 指针offsets获得了ipc buffer 下接受来自其他节点数据的目标位置偏移量
1 | |
一开始我很是不能理解为什么 data[1] 和 data[3] 分别对应 ipc handle 和 offset ,后来我参考了 torch/csrc
/StorageSharing.cpp 的源码才明白这其中的安排🤭。因为其中的 tuple 1 就是 cudaIpcMemHandle_t handle,3 就是真正 storage 的偏移量的字节数。
创建与初始化 C++ CustomAllreduce
ops.init_custom_ar 创建并初始化了 C++ CustomAllreduce。
ops.init_custom_ar 通过 pytorch 的 TORCH_LIBRARY_EXPAND C++ 扩展(这是用于自定义算子的一个宏)来调用 backend 的 C++ 代码,也就是对应到了下面的 C++ 函数:
1 | |
上面的实现意思很简单,把之前从 CPU 广播拿到的 handles 放入到 CustomAllreduce 类内管理。
随后就是初始化 CustomAllreduce。该类内部的数组 sg_ 最多有 8 个 vllm::Signal 指针,他们分别指向所有 GPU 节点上 CustomAllreduce 的 meta 内存(通过 CUDA IPC handles 和自己内部指针)。
而为了保证收发不会互相影响或产生死锁,vllm::Signal 将收发数组分开了:
1 | |
1 | |
函数 open_ipc_handle 的实现可以参考 CUDA IPC API的使用说明。最后,返回的 char* handle 再加上之前获得的偏移量,就可以直接指向真正存放 storage 数据的内存位置了。
1 | |
注册 IPC buffer
register_buffer 函数完成了 CUDA IPC buffer 的注册。
下面的 C++ 代码会被执行。注意到在程序的最后是 buffer 完成注册最关键的一步:程序会将 handles + offset 全部都 copy 到 d_rank_data_base_ 指向的内存,结合 CustomAllreduce 的初始化过程,可以知道这就是将指向用于 allreduce 数据交换的内存的指针移动到了 rank_data 内。
程序最后的 buffers_ 则记录了一张表格,存放着本节点 buffer 与 rank_data 的对应关系。这一步完成之后,本节点的 GPU 就可以通过 buffer 的指针,获知其他 GPU 的对应 buffer 的 IPC 交换地址,那这样也就完成了 register。
1 | |
all_reduce_reg 与 all_reduce_unreg
明白了 CustomAllreduce 中的注册意义后,再来看之前提到的两个 all_reduce_(un)reg 函数就能更好地理解。
all_reduce_reg在使用前就已经默认输入的inp已经完成注册;all_reduce_unreg则需要先将inp的数据拷贝到完成注册的self.buffer,再做 allreduce。
所以,all_reduce_unreg 函数会多一次 cudaMemcpy,幸好这个数据拷贝损失的性能代价不大。它会在 CUDA graph context 外时被调用。
1 | |
1 | |
简单起见,我们重点来看 all_reduce_unreg 这一个的实现,它将输入的 inp 数据拷贝给 self.buffer 后,就会调用 _all_reduce 函数来完成 allreduce。
allreduce 实现
_all_reduce 函数只是一个启动器,它会依照输入输出的数据类型启动 CustomAllreduce::allreduce 函数。接下来我们重点研究一下 allreduce 函数:
先来看其中的第一部分,该部分与之前的注册 IPC buffer 内容紧密相关。回顾前文,CustomAllreduce::buffers_ 内存放着本节点 buffer 与 rank_data 的对应关系,于是获得的 ptrs 就是指向了 8 个 rank_data 内存的指针数组。当然,还有一种情况是不在当前上下文,那么需要从 d_rank_data_base_ 取出对应 rank_data 的指针数组。
1 | |
取出对应了其他节点 handle 指针后,下一步就是开始 Allreduce 操作了。下面的代码会分情况调用 cross_device_reduce_1stage 或者 cross_device_reduce_2stage。从代码看,对于小节点数小 size 的情况,会使用一阶段 allreduce cross_device_reduce_1stage,反之选择二阶段 cross_device_reduce_2stage。
CUDA kernel 函数的 blocks 和 threads 是作者试验出来的,他在 A100,A10,A30 和 T4 上尝试了多次,最终选择 36 个 blocks 以获得最好的性能。
1 | |
cross_device_reduce 实现
cross_device_reduce_1stage 代码实现如下:首先要保证所有的节点都在执行 allreduce 前同步,multi_gpu_barrier<ngpus, true>() 会首先将 vll::Signal 数组执行信号同步,随后同步 block 内线程。之所以用 vll::Signal 做信号同步,是因为代码中会出现两次 multi_gpu_barrier,为了防止节点间速度不一致导致的在不同 multi_gpu_barrier 函数上同步。比如若没有 vll::Signal,节点 1 在第二个 multi_gpu_barrier 同步,而节点 2 还未达到第一个 multi_gpu_barrier,然后他们同步后接着往下走,就会出现程序死锁或者 bug。
1 | |
对于 two-shot allreduce,执行步骤会稍显复杂。首先,程序将每个节点的数据分成了 ngpus 份,然后按照节点 rank 号分配好指针位置,再将数据通过 reduce 的方式求和存入到 tmp 数组中。经过第二个 multi_gpu_barrier 后,执行 allgather,第 i part 部分的数据会从第 i 个节点过来,所以 i 号节点需要遍历 ngpus 遍,将其他节点的数据都 gather 起来。
1 | |
倘若你理解了前文所说 one-shot allreduce 和 two-shot allreduce 的实现原理,那么上面部分的 CUDA 代码实现其实非常简单,但难在如何写出高性能的代码。本着学习的态度,我仔细研究并总结了以下优化细节:
-
packed_t中对齐 128 bits 的实现。有利于线程更快 load 数据1
2
3
4
5
6
7
8
9
10
11
12
13
14template <typename T, int sz>
struct __align__(alignof(T) * sz) array_t {
T data[sz];
using type = T;
static constexpr int size = sz;
};
template <typename T>
struct packed_t {
// the (P)acked type for load/store
using P = array_t<T, 16 / sizeof(T)>;
// the (A)ccumulator type for reduction
using A = array_t<float, 16 / sizeof(T)>;
}; -
嵌入 cuda ptx 代码,同样地,为了保证 128 bits 对齐,使用 u32 指令
1
2
3
4
5
6
7
8
9
10
11static DINLINE void st_flag_volatile(FlagType* flag_addr, FlagType flag) {
asm volatile("st.volatile.global.u32 [%1], %0;" ::"r"(flag), "l"(flag_addr));
}
static DINLINE FlagType ld_flag_volatile(FlagType* flag_addr) {
FlagType flag;
asm volatile("ld.volatile.global.u32 %0, [%1];"
: "=r"(flag)
: "l"(flag_addr));
return flag;
} -
使用低精度做计算,后转到高精度 float
1
2
3
4
5
6
7
8
9template <typename P, int ngpus, typename A>
DINLINE P packed_reduce(const P* ptrs[], int idx) {
A tmp = upcast(ptrs[0][idx]);
#pragma unroll
for (int i = 1; i < ngpus; i++) {
packed_assign_add(tmp, upcast(ptrs[i][idx]));
}
return downcast<P>(tmp);
} -
循环充分展开,比如
1
2
3
4
5
6
7
8
9#pragma unroll
for (int i = 0; i < ngpus; i++) {
int gather_from_rank = ((rank + i) % ngpus);
if (gather_from_rank == ngpus - 1 || idx < part) {
int dst_idx = gather_from_rank * part + idx;
((P*)result)[dst_idx] = tmps[i][idx];
}
}
}