深入探索 DeepSpeed(三)
DeepSpeed 高性能算子实现
上篇博客的最后,我发现 DeepSpeed inference v1 版本的算子代码似乎有精度问题。笔者在 A100 上用 DeepSpeed 推理模型,当打开 replace_with_kernel_inject 后,模型使用上面介绍的算子做推理后,其回答会变成一些乱码,或者是胡言乱语。本人怀疑是 v1 高性能算子代码实现有精度问题,进而导致模型回答混乱。
因此,这里不再介绍 DeepSpeed inference v1 版本的算子代码,我们来看看 inference V2 代码。
注:本篇博文的源码分析基于 DeepSpeed-0.14.2。
也许是因为 DeepSpeed inference v1 的实现不是很理想,微软很快又把 DeepSpeed inference v2 端了上来,这篇博客我们重点来关注一下 DeepSpeed inference v2 的内部实现,包括它的引擎,以及它博客中介绍的最大特点——动态分割融合(Dynamic SplitFuse)到底是如何实现的。
DeepSpeed inference v2 示例
老规矩,开始之前,我们总要拿一个例子来跑一跑:
首先,按照 DeepSpeed 和 DeepSpeed-mii 的要求,需要安装:
1 | |
然后,如果我们只是想临时跑一下模型看看它的输出,就可以:
1 | |
然后就可以直接运行该程序:
1 | |
如果要比较久地部署到服务器上,并方便客户端经常访问调用,那么代码会稍微复杂一点:
1 | |
当我们把程序跑起来后,自然要想,它究竟是如何跑起来的。
DeepSpeed-mii
动态分割融合
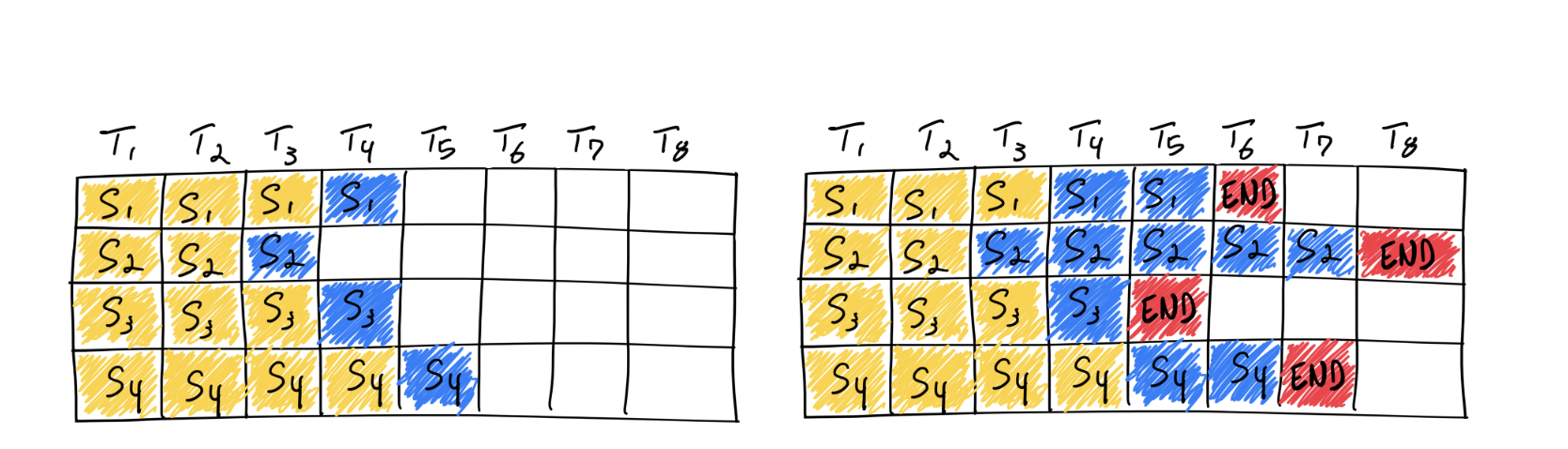
为了充分释放 GPU 的性能,大模型会将若干个用户输入语句(prompt)合并,一起做批处理。然而,用户输入的 prompt 到大模型内的请求语句必然是长短不一的,此时常规做法是,模型通过填充(padding)的手段将请求中的输入 token 张量填充为相同的形状,再做进一步处理。但这样做还是浪费了不少 GPU 的性能,于是就有了连续批处理技术(Continuous batching)——将每个用户输入语句尽可能地“拼接”起来,补齐空白。
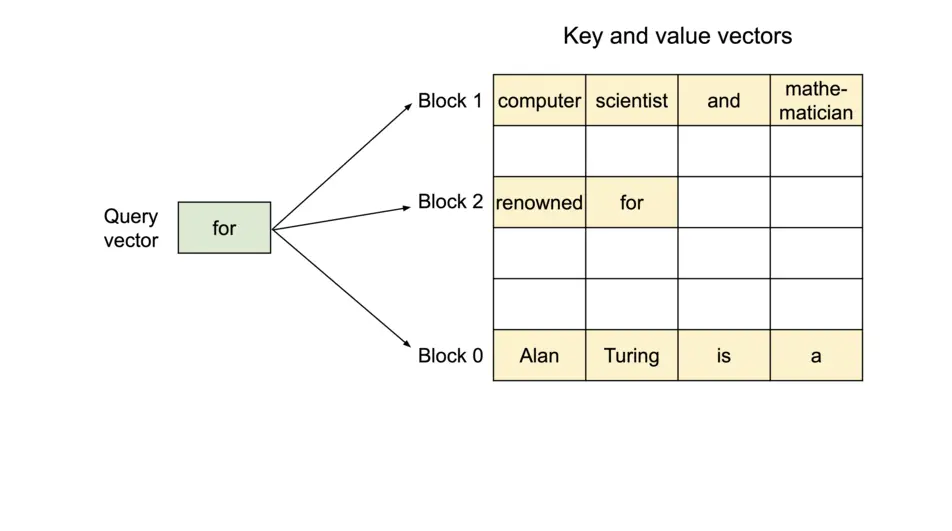
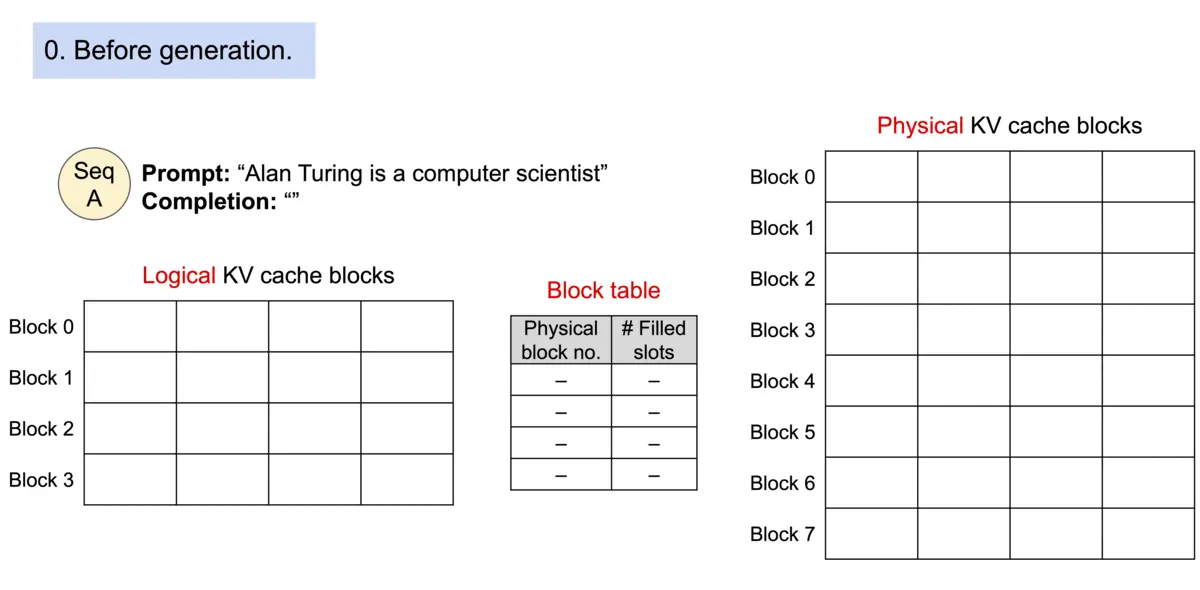
另一个大模型推理的性能瓶颈是,KV cache 占用空间过大。为此,vllm 提出了 KV cache 分块技术,借鉴操作系统中分页(paging)的概念,将本应该连续存放的 KV cache 做分块处理。具体操作是,vllm 将 KV cache 分成若干分固定长度的块,并通过映射表建立了逻辑 KV 块和物理 KV 块间的关联。处理时,逻辑块连续,但其映射到物理内存上的物理 KV 块可以分开存放,这样既可以减少内存碎片,也可以增加 KV block 共享的可能。
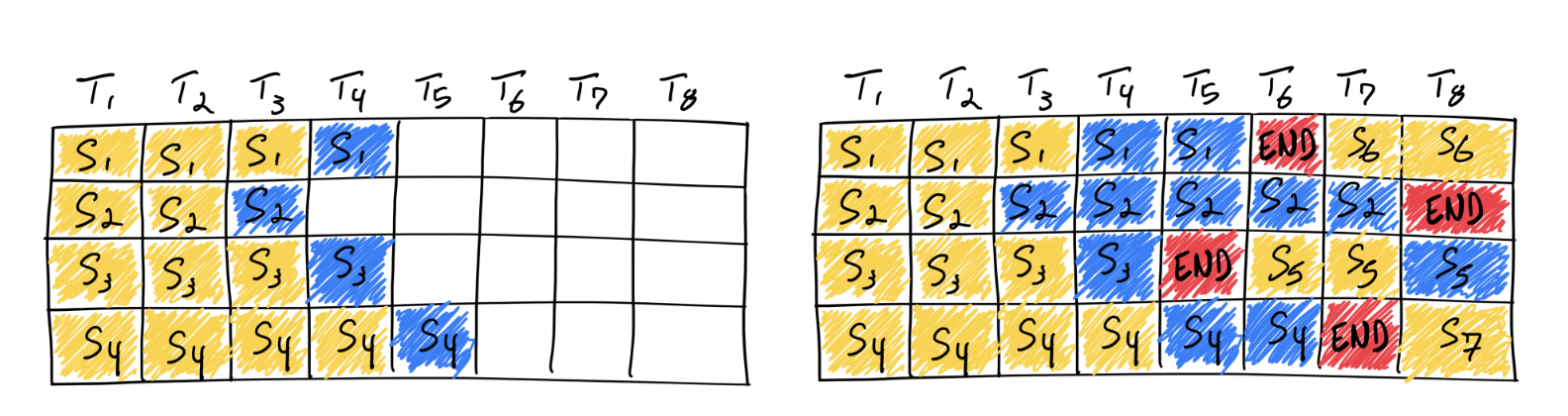
而 DeepSpeed 工程师进一步发现,prompt 阶段往往因处理的 token 过多而出现计算瓶颈,generation 阶段往往因处理的 token 过少(仅有 1)而陷入内存瓶颈。因此,它将上述两者技术结合,提出了动态分割融合(dynamic splitfuse)的优化技术。这是一种用于 prompt 阶段和 generation 阶段的 token 组合策略。具体操作是,通过从 prompt 阶段中取出部分 token 与 generation 阶段的 token 计算结合,使得模型可以保持一致的前向推理大小(forward size)。如此保持一定量的前推大小,可以使得 GPU 的计算性能和访存带宽都得到较好的发挥👇。
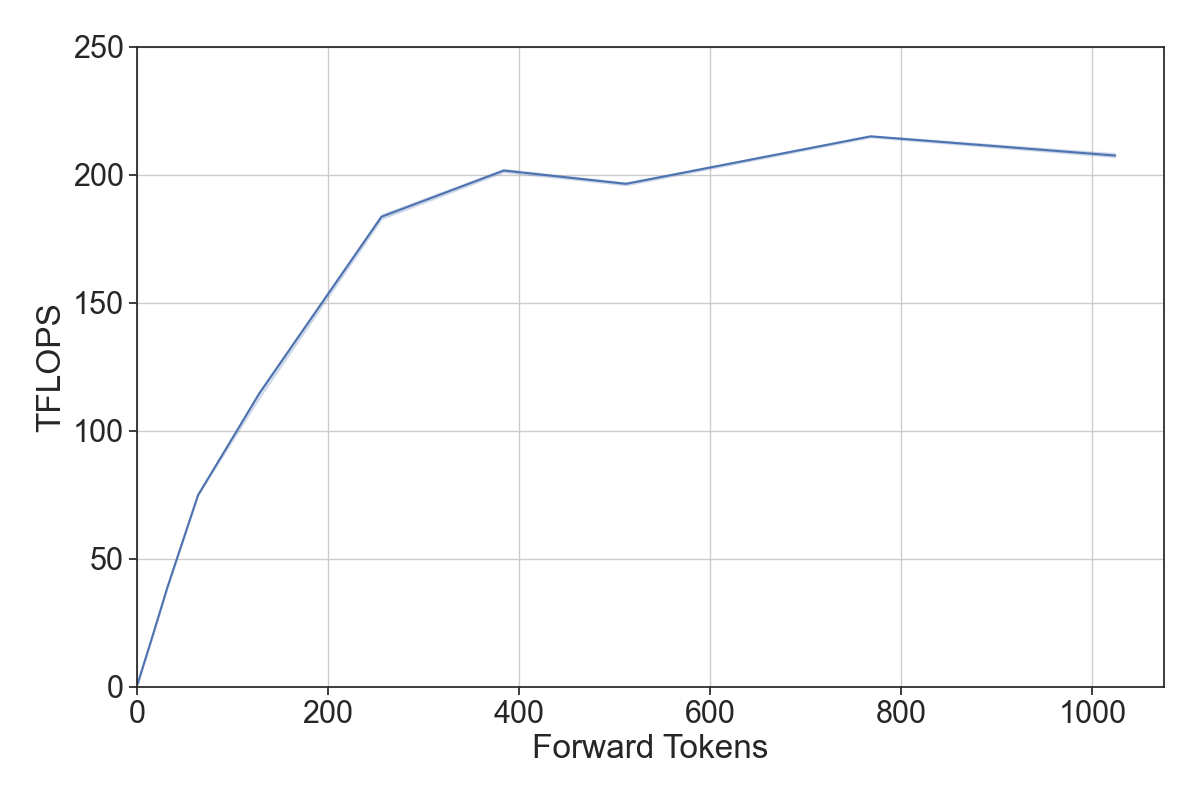
为此,动态分割融合需要:
- 将长 prompt 分解成一些小 token 块,并在多个 forward(迭代)中进行调度,只有在最后一次 forward 完成后才能执行生成。
- 将一些短 prompt 组合起来,以精确地填满目标 token 块。当然,有时一些短的 prompt 也可能被分解,以确保每个小块的长度需求被精确满足,保证前向大小(forward sizes)对齐。
从实验中看,动态分割融合技术提升了以下性能指标:
- 更低的延迟: 由于长 prompt 不再需要极长的前向传递来处理,模型将提供更低的客户端延迟,因为该技术能充分发挥 GPU 性能,让它在同一时间内执行更多的前向传递。
- 更高的吞吐量: 对短 prompt 的融合能使模型持续运行在高吞吐状态,其实逻辑和第一点一致。
- 更低的波动和更好的一致性: 由于前向传递的大小一致,且前向传递大小是性能的主要决定因素,每个前向传递的延迟比其他系统更加一致。生成频率也是如此,因为DeepSpeed-FastGen不需要像其他先前的系统那样抢占或长时间处理 prompt ,因此延迟会更低。
因此,与现有最先进的大模型推理系统相比,DeepSpeed-FastGen 既可以迅速、持续地处理 prompt 的 token,还能同时完成 token 的 generation。该技术不仅提高了系统利用率,也获得了更低的延迟和更高的吞吐量。
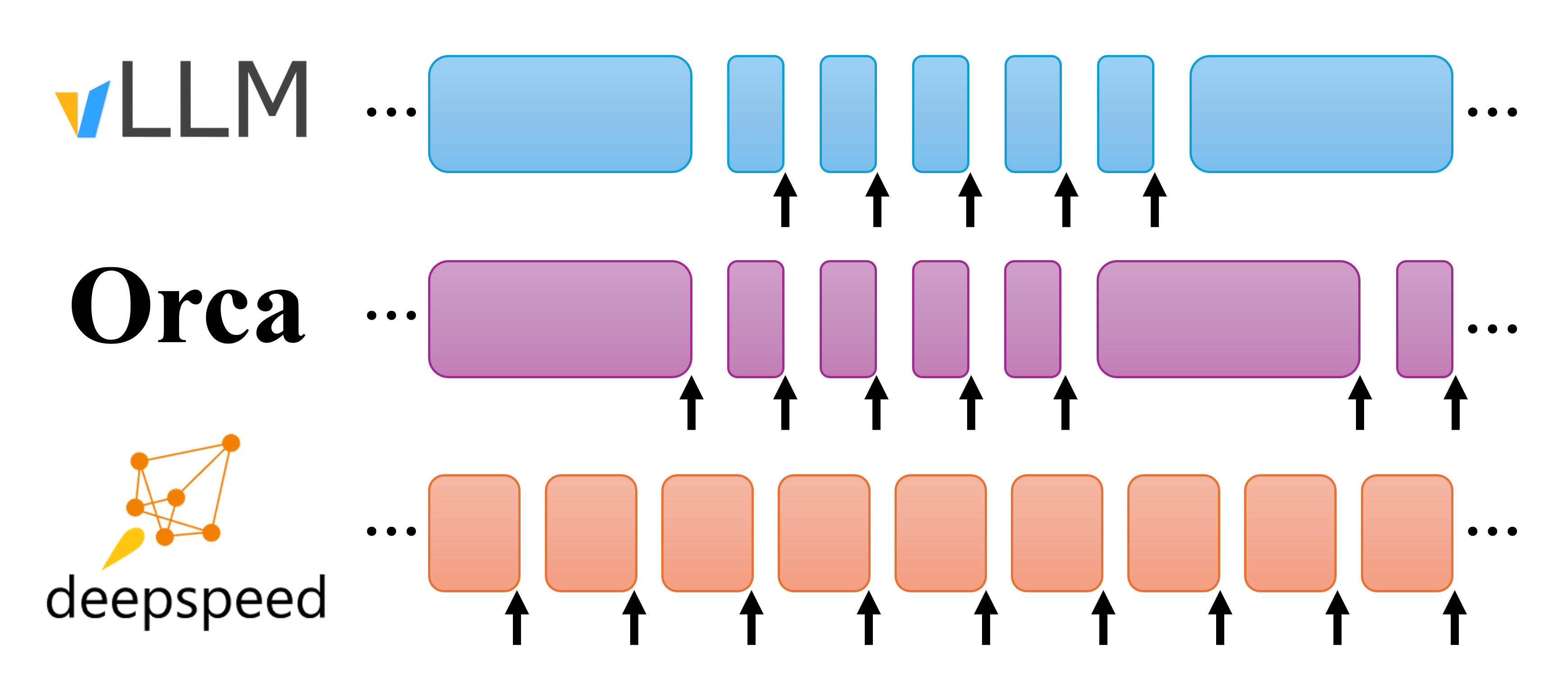
图: 连续批处理策略的示意图。每个块显示一个前向推理的执行。箭头表示前向推理有一个或多个生成的 token 序列。vLLM 在一个前向推理中要么是 token generation 阶段,只产生一个 token,要么处理 prompt 阶段,处理一堆 token;这里 token 的生成抢占了 prompt 的处理。Orca 则以完整长度处理 prompt。DeepSpeed-FastGen 的动态分割融合则执行固定大小 token 块,对它们做前向推理。
代码实现
我们从上面例子中的 mii.pipeline 出发:下面的介绍包括了 mii.pipeline 和基类 RaggedBatchBase 在拿到 batch 个 request 后的工作流程。
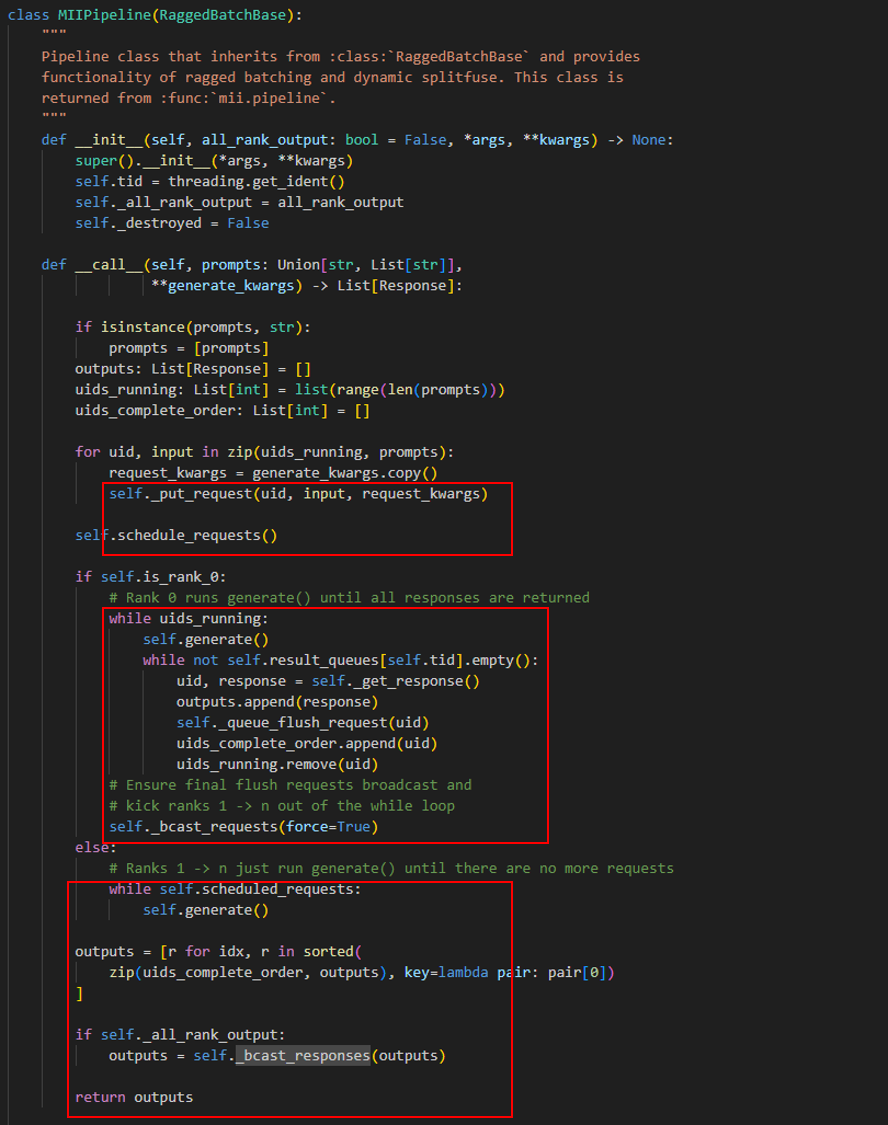
我们将 pipeline 的调用代码分成三部分(红框标明),接下来分成三部分对代码做说明。
第一部分
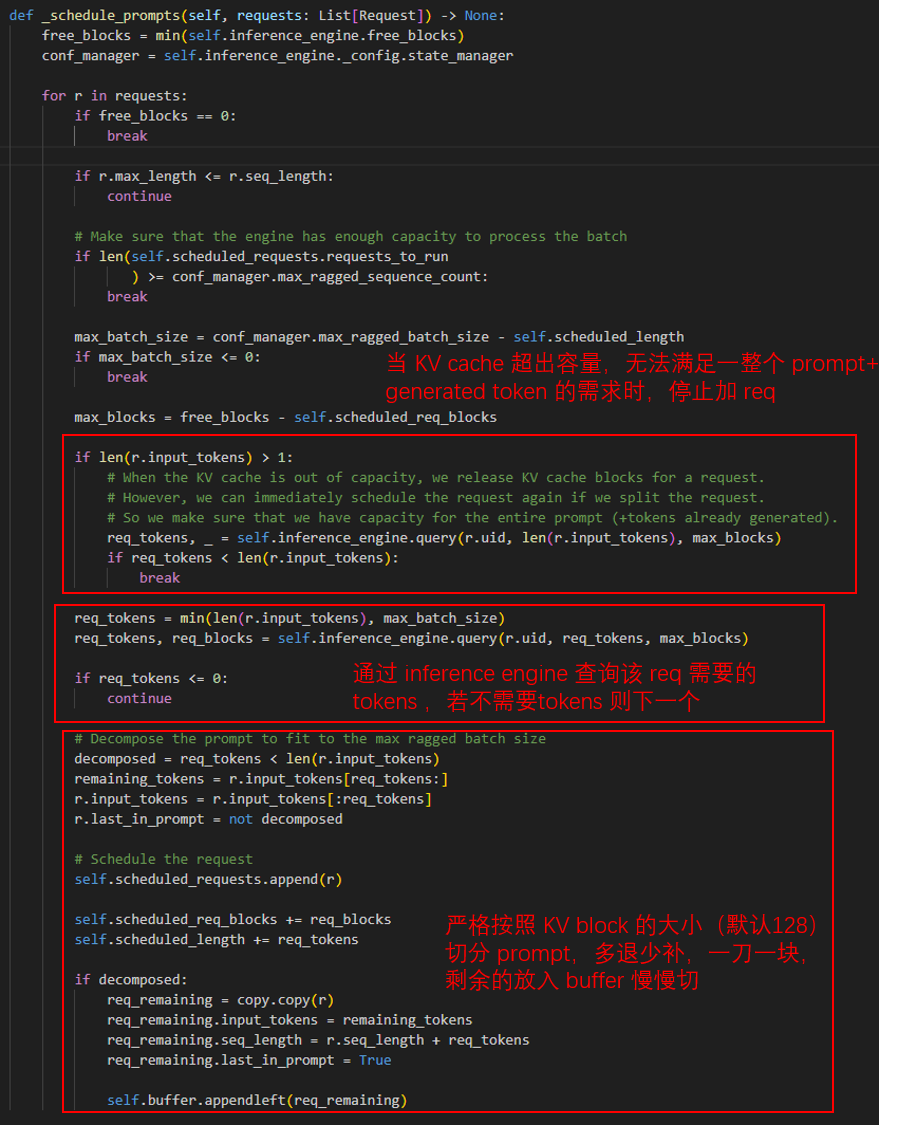
首先看第一个红框,这部分主要完成对用户输入 prompt 的切分、调度。它将输入的 prompts 全都导入到分词器 tokenizer 中,经过 _put_request 的编码后,包装产生 request。这个 request 包含了一切大模型推理需要的用户输入 tokens 和生成参数(generation config),然后这些 requet 就会被放入队列中等待调度。
1 | |
那么这些 request 是如何被调度的?
很简单,对于那些已经将输入 token 解析完成的,处于生成阶段(generation 阶段)的 request,放入 _schedule_token_gen 中处理,对于还在解析输入(prompt阶段),放到 _schedule_prompts 中处理。prompt 的模型总入口是 self.scheduled_requests,要暂未被调度到的 request 会被放到 self.buffer 中缓存。
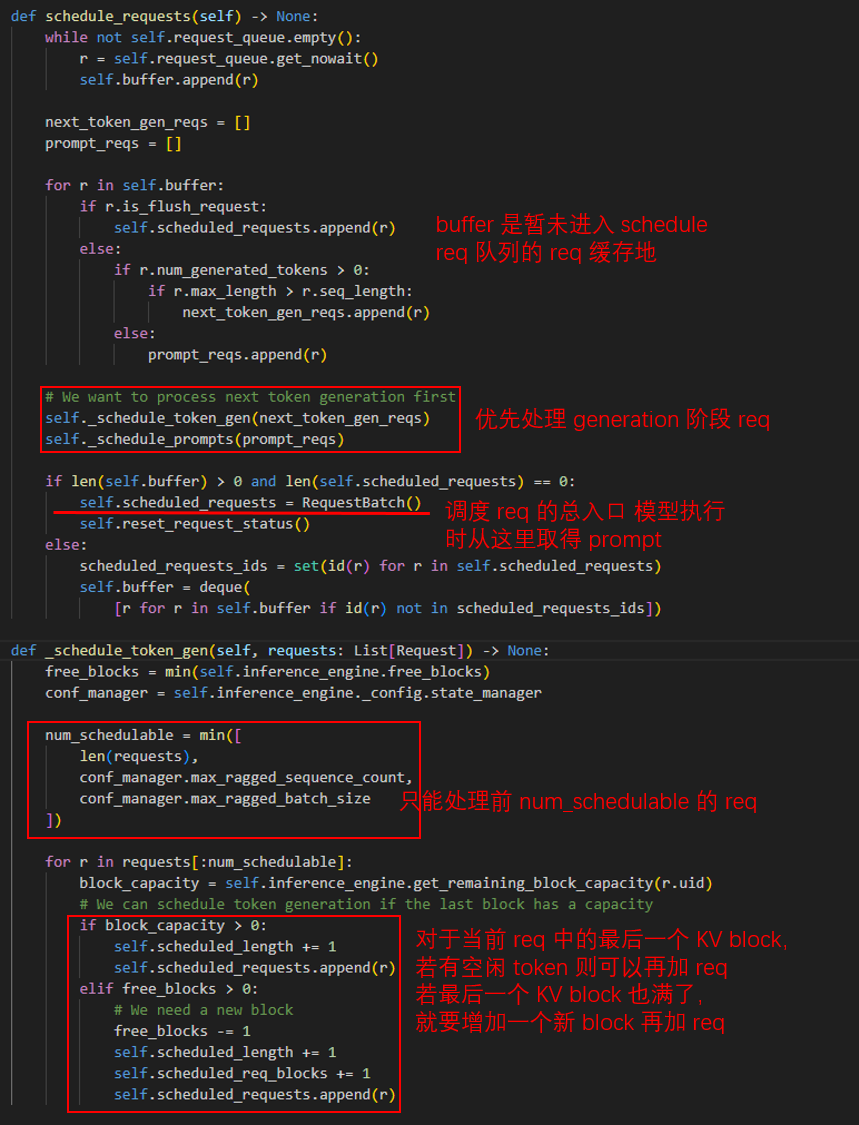
系统会优先处理生成阶段的 request,当出现 kv block 空缺位后,就会加入新的 request。而若 GPU 还有闲余空间(语句(sequence)空间)处理 prompt,那么会继续处理 prompt 阶段的 request。它会依照下面的函数严格限制每个 request 的长度:
1 | |
第二部分
第二个红框是模型的执行部分,Rank 1-n 的节点仅负责 generate,而 Rank 0 要考虑的就多了:他不仅需要运行 generate,还需要在最后管理释放 requset,输出 response,在最后让 Rank 1-n 节点退出释放。
先来看一下 generate() 函数,它负责 token 的生成,因此其中的实现对于我们了解 deepspeed inference 如何运作相当重要。
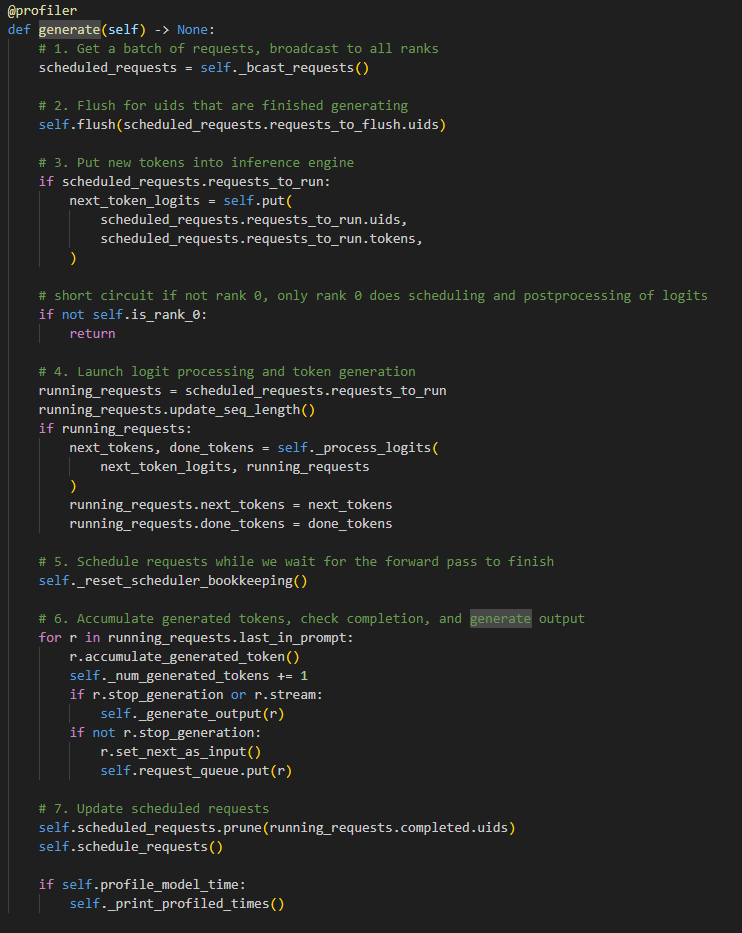
_bcast_requests将 req 广播。
a.RaggedBatchBase内部将多个 GPU 节点用 ZeroMQ 的高性能异步消息库连接起来。
b. 在_bcast_requests函数中,Rank 0 节点负责将所有的self.scheduled_requests中的 req 转成 json 数据格式,再发给其他 GPU 节点。其他节点则负责接收这些 req。
c. 此外,_bcast_requests(Force=True)函数在所有 req 处理完毕后会再次被 Rank 0 节点调用,此时发送的 req 其实是空的。但这操作并非多余,这是通知其他 Rank 节点要及时退出释放资源。
1 | |
flush函数将self.scheduled_requests中要重刷的(已经完成生成的)语句资源都释放掉,包括他的 KV Block Cache 等。这方面的代码涉及到 DeepSpeed 内。
1 | |
put函数将未处理完的 token 加入到推理引擎中,然后执行 forward 前推动作。具体的运作步骤参考下文的推理引擎内容。- 启动 logits 处理。
a. 到第三步,其余 Rank 的工作就已经完成了,但对于 Rank 0,还需要做剩下的 4 5 6 7 步
b. Rank 0 在这里会调用 logit_processor 和 sampler 来选择具体的 token 值。相关代码在 deepspeed.mii.batching.postprocess 中可以找到 reset_scheduler_bookkeeping对self.scheduled_requests清空!大家可能会奇怪,之前我们几乎所有的操作都是为了或者说基于这个scheduled_requests而去做的,现在说清空就清空是不是有点前功尽弃的感觉了。emm 确实,但所谓不破不立吧,有时也许做好的办法就是打破重来。- Rank 0 需要检查是否完成生成。对于已经完成了的 req,就会从运行的
scheduled_requests.requests_to_run列表中删去 - 调用
schedule_request()(参考第一部分),以目前正在运行的scheduled_requests.requests_to_run为基础,建立一个新的调度 req 列。
第三部分
当程序执行完所有的 batch 的生成词后,需要将最终的结果返回,如果需要的话,还要将 output 广播到所有的 Rank 节点上。
这其中,get_response 函数负责调用 tokenizer 解码,生成字符串。
1 | |
bcast_responses 则负责将回答广播到所有节点上。
1 | |
推理引擎v2
与第一版推理引擎相比,第二版推理引擎的代码要简单易懂的多(这就是代码重构带来的后发优势)。InferenceEngineV2 有三个成员:推理config、模型本身和推理状态管理器,可谓简单清楚直观。
1 | |
而且,InferenceEngineV2 支持类似 vllm 中的动态批处理功能(dynamic batching)(有时也称为 continuous batching)。为了方便介绍下文的嵌入操作,这里先提一下模型是如何将长短不一的各个输入query统一处理的,并实现 continuous batching 的
1 | |
首先,在构建时,它使用了 RaggedBatchWrapper 包装了必要的数据结构,包括 input ids,tokens 和 seqs 的相关信息。然后,put() 将输入的批处理 sequence 逐个插入到 _batch 内:
1 | |
在设计使用 insert_sequence 函数时,DeepSpeed 的工程师发现,将句子逐个插入到列表中会导致内存访问因碎片过多而过慢,因此他们的做法是先插入所有的句子到一个临时列表中,然后再使用 finalize() 函数将全体数据更新到 RaggedBatchWrapper 内的最终目前数据结构中。然后,prepare_batch 准备所有的用于前推数据结构,并做摊还分析。
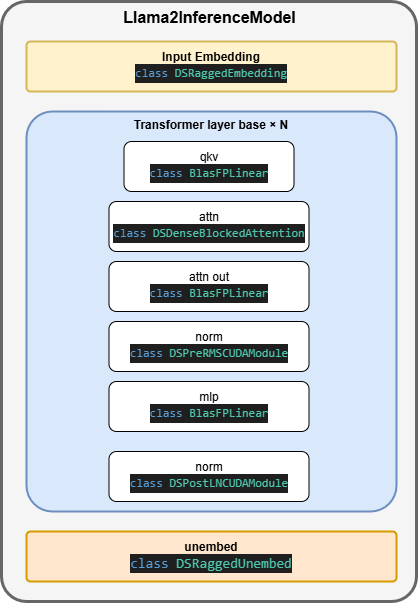
现在,我们来看看 DeepSpeed 推理 v2 版本有哪些新花样。还是从 llama2 模型出发,先看看整个模型架构中,高性能 kernel 的使用情况:
参差不齐的嵌入操作
为了充分释放 GPU 的性能,模型会将若干个用户输入的请求做批处理。然而,用户输入到大模型内的请求语句必然是长短不一的,此时常规做法是,模型通过填充(padding)的手段将请求中的输入张量填充为相同的形状,再做进一步处理。但这样做还是浪费了不少 GPU 的性能,为此,DeepSpeed 提供了类似 vllm 中的动态批处理功能(dynamic batching)。它将同一模型执行的多个请求组合在一起,并且不需要填充短请求,就可直接进行批处理,从而获得更大的吞吐量。
因为缺少了填充对齐,因此取名“参差不齐的嵌入操作”,英文名 RaggedEmbedding,这恰好对应了类名 DSRaggedEmbedding。而要想充分理解 DSRaggedEmbedding 的实现,我们必须从与它密切相关的类 RaggedBatchWrapper 和 RaggedEmbeddingKernel 开始聊起。
RaggedBatchWrapper
虽然这类只是一个 wrapper,仅封装了相关的值而已。但我觉得这内部的值可以很好地帮助我们理解动态批处理的实现细节。因此在这里展开讲讲。
为了让更清楚明白,举一个简单的例子:假设现在模型正在处理 8 个 token,这 8 个 token 分别位于 3 个 sequence 中:
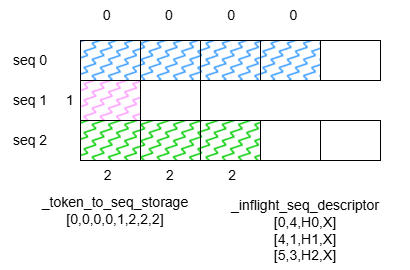
其中,sequence 指的是每个请求读入的句子,seq_lens 表示一个 batch 中所有的句子。RaggedBatchWrapper 的成员还有:
input_ids用户输入的句子,被切分、数字化后,成为一列整数列_batch_metadata_storage存放正在处理的句子数量和 tokens 数量,在本例中其值为(sum(seq_lens), len(seq_lens))_token_to_seq_storage存放了 token_id 映射到 seq_id 的表,通过它每个 token 可以找到自己的 seq。_inflight_seq_descriptor存放了每个正在处理的句子的详细信息,包括开始 token 位置,总token 数,目前看见的 token 等。_kv_ptrs指向 GPU 缓存中的 KV-blocks 指针列表。
RaggedEmbeddingKernel
下面就是 DSRaggedEmbedding 的前推函数:可见它直接调用了 RaggedEmbeddingKernel
1 | |
而 RaggedEmbeddingKernel 是对 CUDA 实现的算子的一个 python 包装,封装了 ragged_embed C++ 函数的实现:
1 | |
在开始看 C++ 实现之前,我想带大家先回顾一下 embedding 的计算方式,避免被代码绕晕。
NLP 中的 Embedding 原理就是将文本编码为紧凑的高维向量。而为了将原先文本中 token 的 one-hot 编码转换成更紧凑稠密的高维向量,往往需要做一次矩阵乘法:如下图所示例子,利用稠密的浮点向量来表示每个 token,再利用向量间的余弦值来表示词义关系。
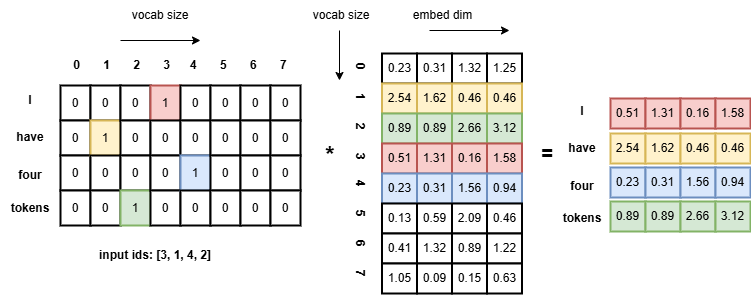
因为注意力机制无法发现词序关系,LLM 中还更多地加入了位置编码,比如 transformer 论文中经典的 sin-cos 位置函数表示词序位置,他们计算后会直接加到 embedding 向量中。
C++ 实现
前面提到,对于 DSRaggedEmbedding 中维护的 embedding 相关的张量,他们在主机上也相应地维护了一个 shadow 张量。这些 shadow 张量是在构造 ragged embedding 时直接填充的。在条件允许的前提下,应分配 shadow 张量,以方便张量快速复制到 GPU 上。因此,我们需要尽可能地降低主机到 GPU 的数据传输延迟,来看看 DeepSpeed 是如何实现的:
快速分配主机内存
1 | |
其中:
cudaHostAllocPortable该 flag 要求返回的主机内存将被所有CUDA context视为 pinned memory,而不仅仅执行了分配内存的那个 context。这里与cudaMallocHost()有点区别,参看 NVIDIA 社区解答cudaHostAllocMapped该 flag 要求分配的空间必须映射到 CUDA 地址空间中,并且设备内存指针可以被cudaHostGetDevicePointer()来调用得到。cudaHostAllocWriteCombined该 flag 要求分配的内存必须执行组合写(Write-Combined)策略。在某些系统配置上,WC 内存可以通过 PCI Express 总线更快地传输,但大多数 CPU 无法有效地读取。对于那些 CPU 写入,设备通过 pinned memory 或主机->设备传输读出的操作来说,WC 内存是一个很好的选择。
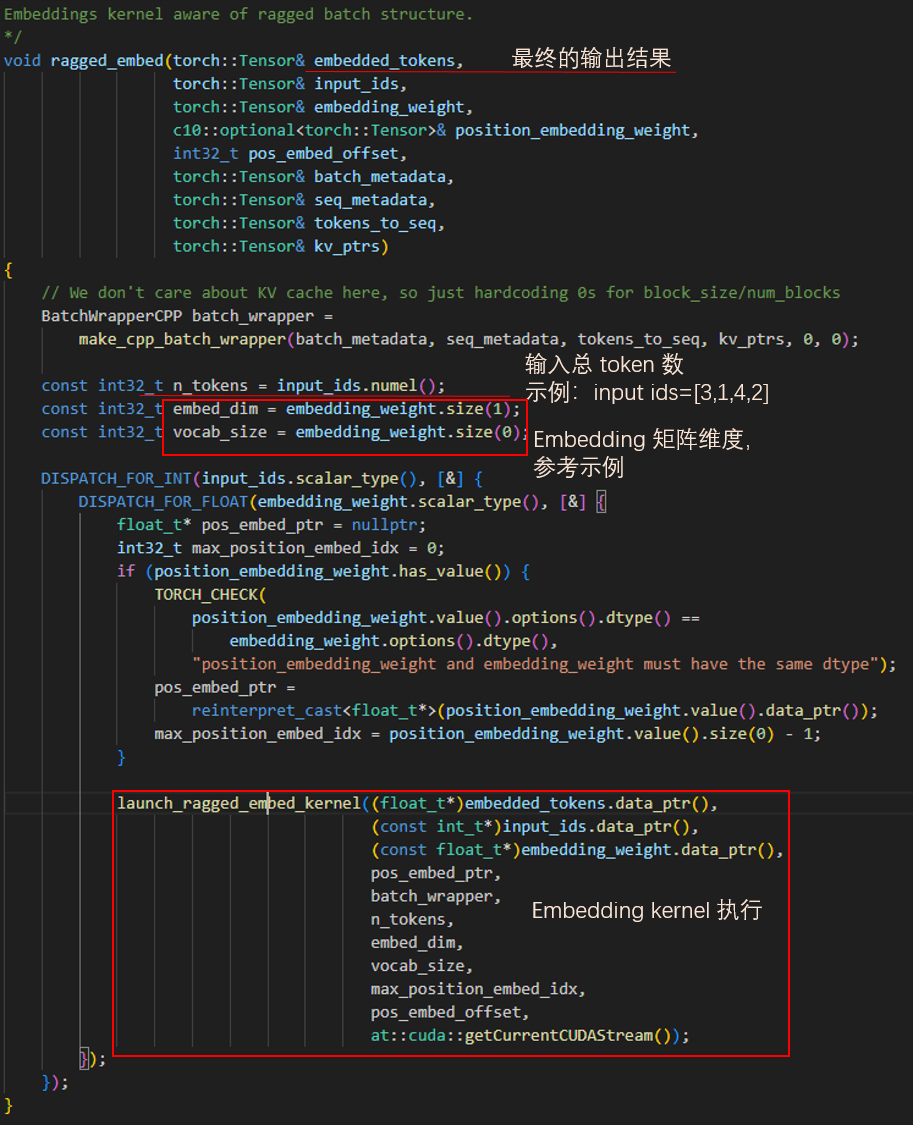
ragged_embed
接下来我们来看被封装的 ragged_embed C++ 代码。参考上文给出的 Embedding 原理示例,可以很清楚地明白各个变量的含义。在使用了 DISPATCH_FOR_FLOAT 和 DISPATCH_FOR_INT 这两个宏做变量类型的定义后,CUDA 代码被正式启动了。
ragged embed CUDA kernel
使用 CUDA 加速程序计算,首先要明确如何安排我们手中的大量线程。从之前的 Embedding 示例中,敏感的读者已经注意到,只需要按照 input_ids 内值读取 embedding_weight 的那一行就行了,不需要真的去计算矩阵乘。因此事实上 CUDA 程序需要注意的根本不是计算,而是读取和写入。
DeepSpeed 是这样安排他们的线程的。首先,让每个线程负责 load embedding_weight 矩阵中一行的一小块颗粒(红圈部分),这一颗粒大小被定义为 embed::granularity = 16 个字节。而一个线程块内有 512 个线程,因此一个线程块可以 load 一共 512 * 16 个字节的数据。对应的,一个 token 的向量维度有 embed_dim,所以需要 parallel_blocks 个线程块 load。这组成了线程块排布的 x 方向,一行 x 方向的线程块完成一个 token 的向量读取,而 y 方向的线程块数量对应着 token 的总数。
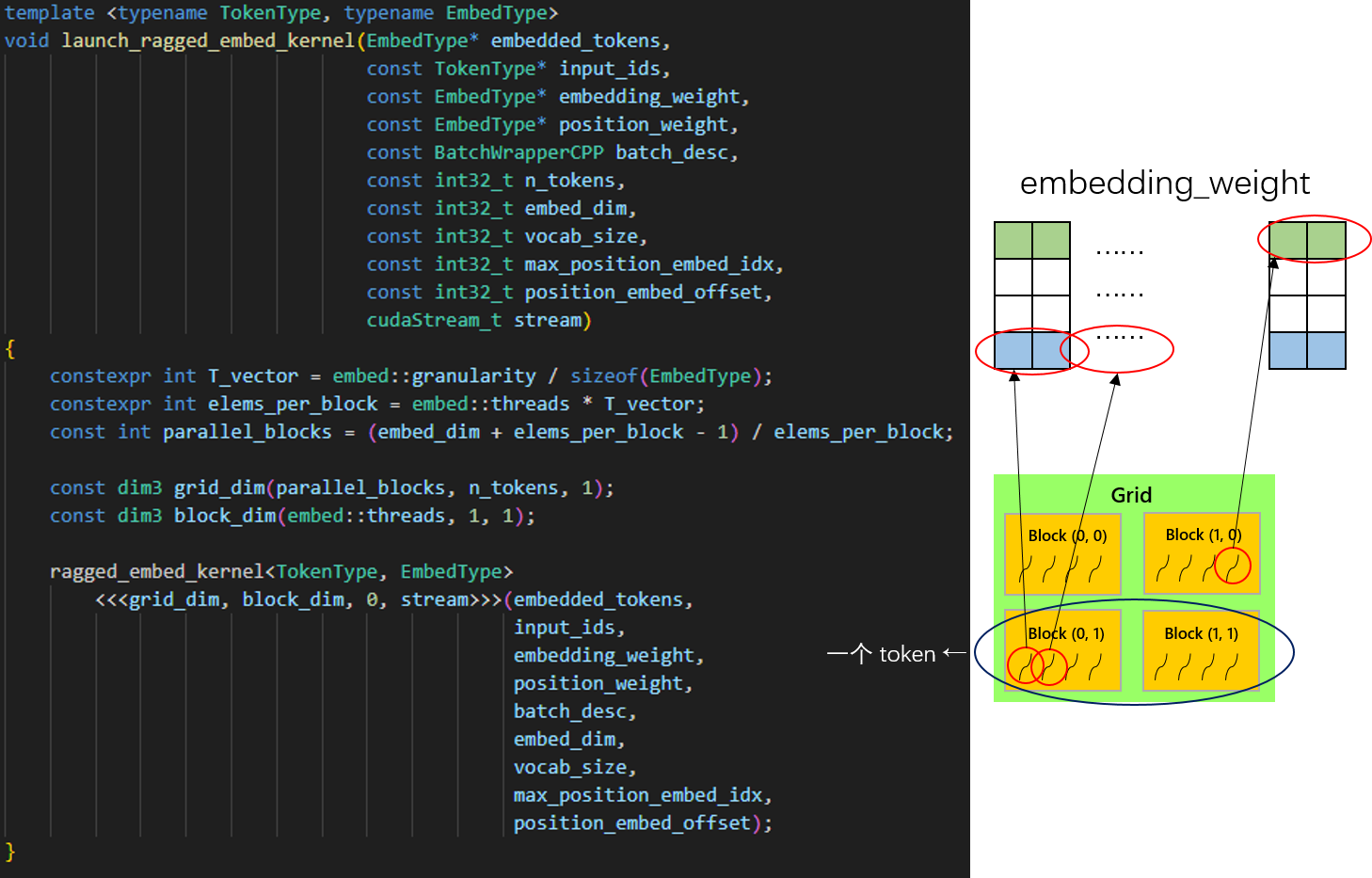
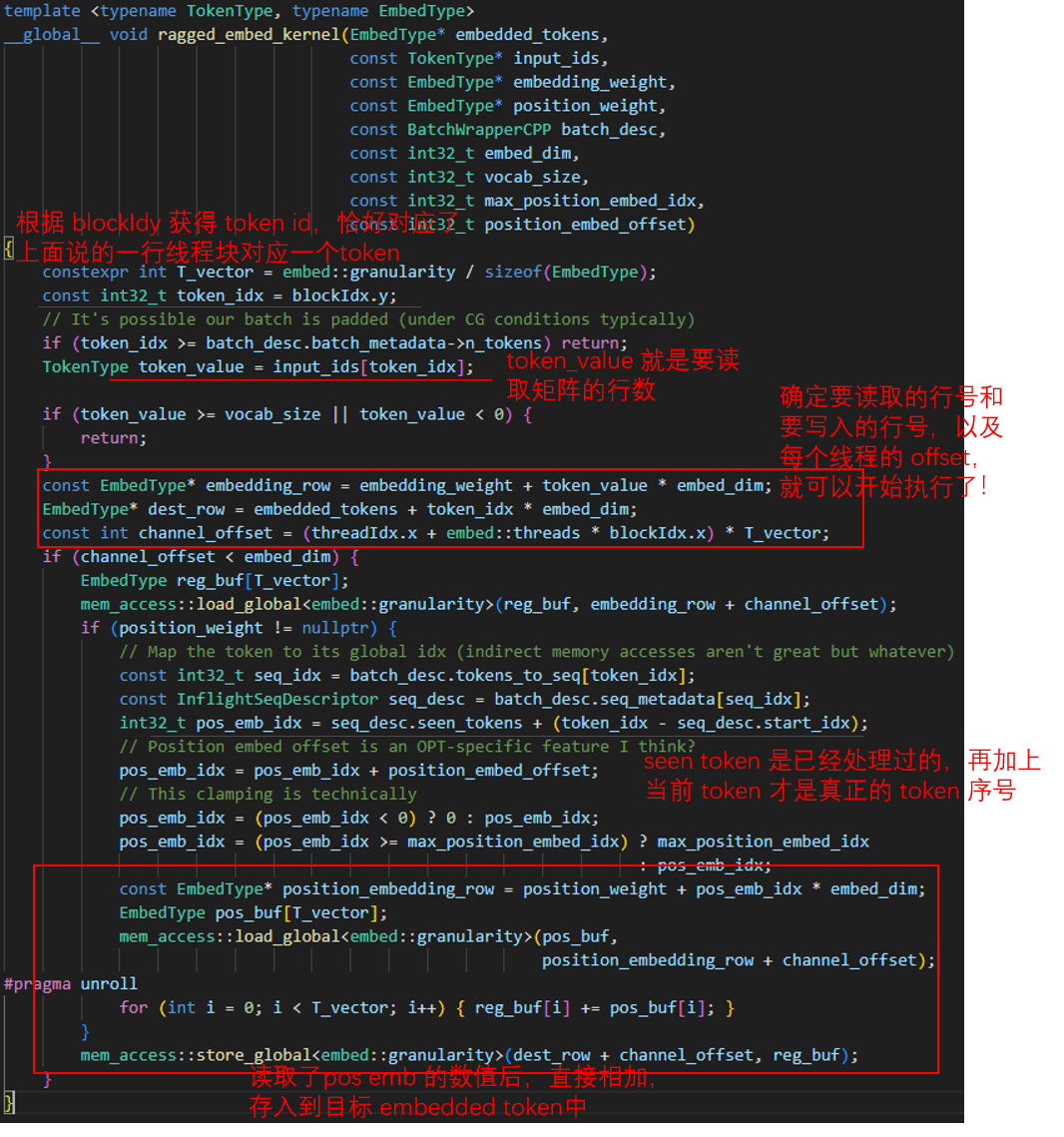
用之前的 Embedding 举例,要处理 “I have four tokens” 这句话,首先找到了这句话对应 token 的行号,填入 input_ids 为 [3, 1, 4, 2]。CUDA 程序执行时,会产生四行 x 方向的线程块,其中第一行的所有线程块负责从 embedding_weight 中装载第 3 行(对应 token_value)的所有数据,读入到输出的 embedded_tokens 矩阵中的第 1 行(对应 token_idx)。
数据读取与写入
现在我们来看一下该 kernel 的性能情况。由于整个 kernel 几乎没有运算,因此主要的瓶颈必然发生在读写数据上,为了尽可能快地将数据读入和写出,DeepSpeed 安排 warp 内的线程读取了连续的 32 * 16 = 512 个字节的数据。整数倍的内存读取容易实现 cacheline 的对齐。
而对于下面这个 API 则大有学问。
1 | |
uint4 表示 4 个 unsigned int 变量按照 16 个字节对齐的方式排布在内存中,总共有 16 个字节大小,正好对应了之前 embed 移动的颗粒度,因此 load_global 在实现时直接使用了 uint4 进行数据搬运。而对应到 PTX 汇编代码,有若干不同的模板实例化来实现:
- ld.global.ca.v4.u32 Cache at all levels 所有缓存上都过一遍
- ld.global.cg.v4.u32 CacheGlobal Cache at L2 only 仅在 L2 缓存上存放
- ld.global.cs.v4.u32 CacheStreaming Cache with evict first policy 使用优先驱逐的方式缓存。即先后读入的数据入流水一般从缓存走过,但片叶不沾身,尽量不影响 cache 其他的数据
线性层计算
看完 embedding 层的计算后,我们顺着数据流动的方向,来看一下 QKV 需要经过的线性层计算。说到底,线性层计算其实就是简单的矩阵相乘,那么在 CUDA 平台上,调用 cublas 接口完成矩阵乘无疑是最方便也是最高效的选择了 😃。
BlasFPLinear
DeepSpeed 中选择使用 BlasFPLinear 类完成 cublas 接口的调用和封装。该类涉及到其他的三个类:CUDAGatedActivation CUDABiasActivation 和 BlasLibLinear。
1 | |
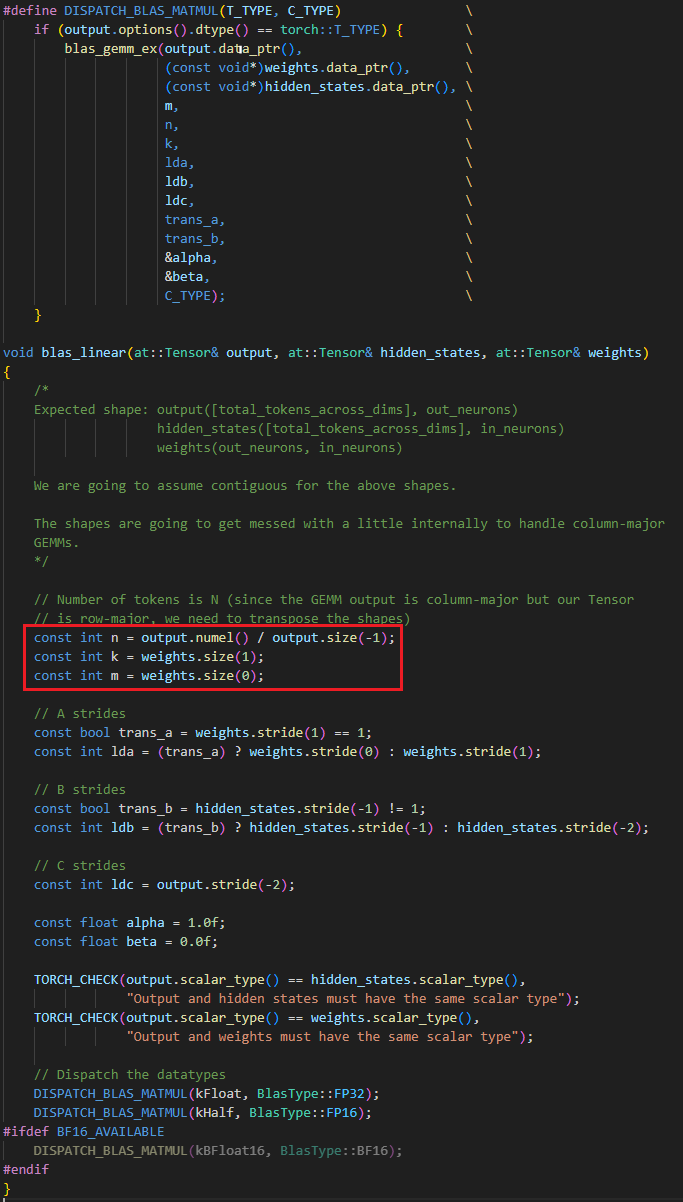
先从最简单的 BlasLibLinear 开始吧,它调用了 C++ 函数 void blas_linear(at::Tensor& output, at::Tensor& hidden_states, at::Tensor& weights)
1 | |
然后是CUDABiasActivation,它调用了 C++ 函数 bias_activation;CUDAGatedActivation 调用了 ds_gated_activation。
C++ 实现
因为 cublas 中做矩阵运算时,通常会采用列主序(column-major)的方式,而 python C++ 中我们已经习惯使用了行主序的方式排布矩阵,因此在运算前需要对矩阵做一定的转换,因此矩阵的维度在这里会有点混乱,让我们好好捋一捋。
首先输入的 hidden_states 的矩阵 H 维度是 (num_tokens, hidden_size),那么 weights 矩阵的维度就应该是 (head_dims * head_size, hidden_size), 就是结果。但由于 cublas 采用了列主序,因此我们传入的矩阵给 cublas 使用时,实际上输入的都是这个矩阵的转置!当然,得到的结果也是这个矩阵的转置。
以下是推导过程,设 是 cublas 看到的矩阵H, 是 cublas 看到的矩阵weights,那么有
但因为得到的结果也是要转置的。于是
于是,输入到 cublas 计算 gemm 的公式应当变成 。这就解释了下图中的红框部分计算 m n 和 k 的代码。又因为实际 cublas 是要计算 ,因此 trans_a 为 TRUE,而 trans_b 为 FALSE。随后针对 cublas API 调用就比较平凡了,不说了。
再来看看激活函数的实现。BlasActivation 支持 GELU、RELU、SILU 和 identity 类型的激活函数。同样地,使用 CUDA 编程首要解决的就是如何安排 CUDA 线程组。这里,DeepSpeed 工程师为了避免一个线程做的活太少,让每个线程 unroll 4 次,一次 load 16 个字节,而一个线程块 512 个线程,因此一共可计算 512 * 4 * 16 / sizeof(T) 个元素。顺带我不得不吐槽一下 DeepSpeed 的代码,这么写应该是怕自己和别人读懂吧。
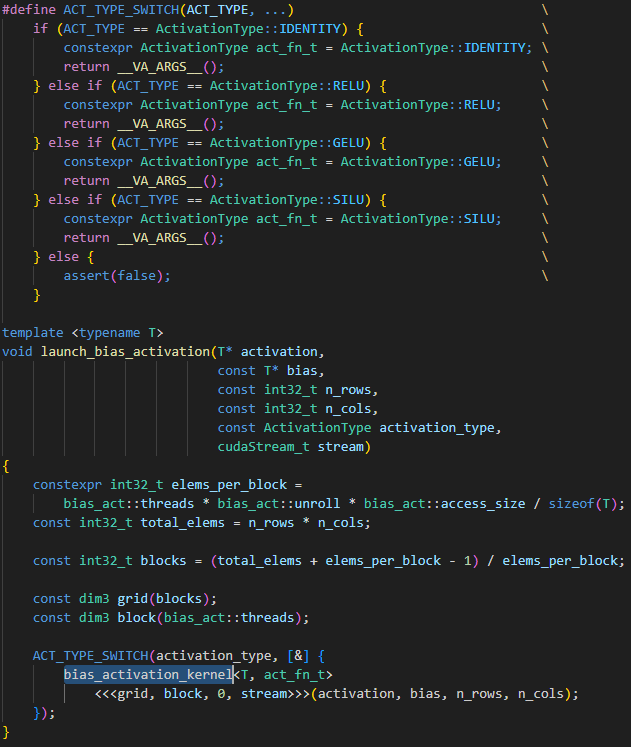
然后我们来看看 CUDA 核函数本身的实现。代码读到这里,其实已经有一点规律可循了。
当核函数内部的计算较少甚至没有计算时,通常瓶颈都会在访存这。此时最好将内部的元素做条纹打包,让每个线程一次循环处理一个条纹的数据,而在循环内,需要将数据缓存在寄存器中,减少访存次数;
在对待线程相关的偏移量需要特别小心,多声明几个变量理清思路才是关键,将偏移量的颗粒度从大到小地考量会比较容易。
比如需要先考虑到一个线程块会计算多少元素,再考虑一次 unroll 循环有多少元素,再考虑 512 个线程中,每个线程占了多少元素,三者相加就是真正的偏移量。
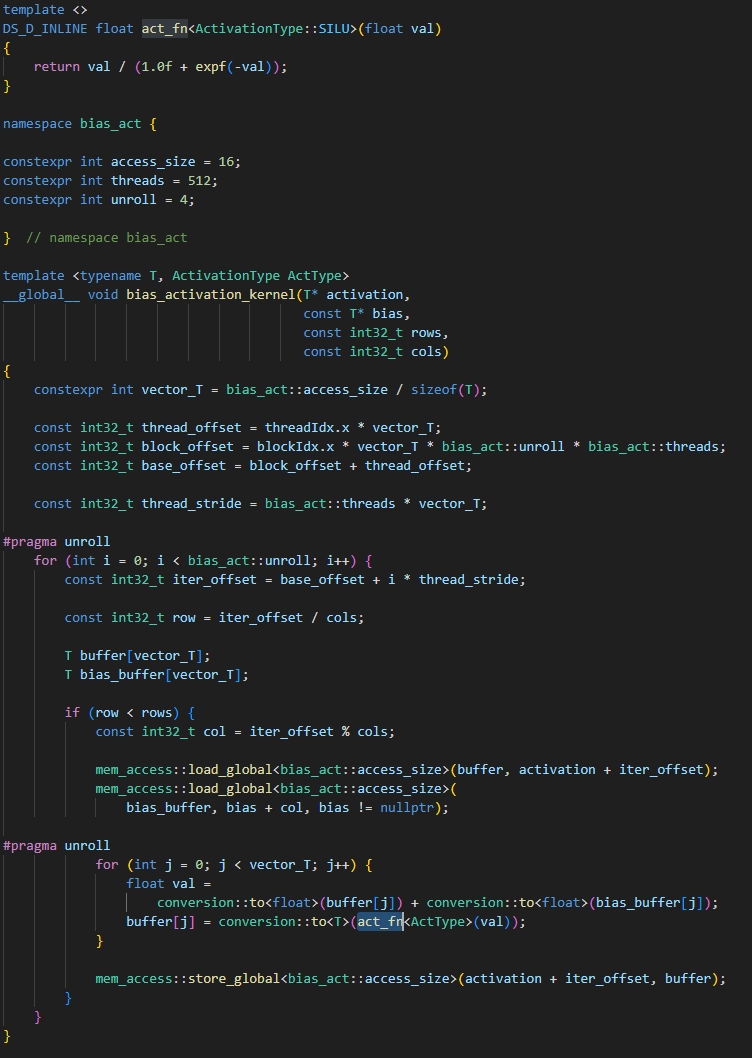
至于 GatedActivation 的实现,其实与 BlasActivation 差别不大,唯一的区别在于,他会算出一个 2 倍大的 output_feature,以便存放 gate 值和 activation 值,然后在 CUDA 核函数中,再使用 gate 函数计算,并写回最终结果即可。
注意力计算
关于 DeepSpeed Inference V2 注意力计算的部分,微软将其实现另开了一个库:https://github.com/microsoft/DeepSpeed-Kernels/,并在我们编译 DeepSpeed-MII 时将 .a 文件静态链接进来,考虑到本篇博客篇幅已经很长,因此我选择下篇再来讲讲 DeepSpeed-MII 的注意力机制实现!