更新于:2024-07-15T23:36:44+08:00
DeepSpeed 高性能算子实现
上篇博客 我罗列了 deepspeed 针对推理的优化方法,并详细分析了 deepspeed 推理引擎中对网络层的替换,张量并行等实现。那么 deepspeed 自己内部实现的高性能网络层究竟有何蹊跷,能比一般的网络层更快?让我们从源码开始看起。
注:本篇博文的源码分析基于 deepspeed-0.14.2。
接上篇博客
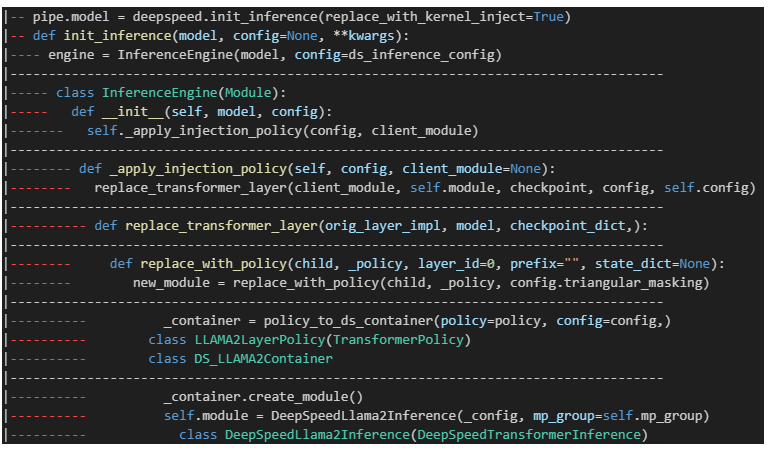
上篇博客我们提到对于一些常见的主流大模型,deepspeed 其内部自己实现了一套高性能的代码。只要 deepspeed 检测到用户使用了这些模型,那么就会启动模型网络结构的替换功能,用高效的实现替代部分或全部网络结构。以 llama2 模型为例,DeepSpeedLlama2Inference 就是 deepspeed 内针对 llama2 开发的高性能推理模型。本篇博客我们来细致地研究一下 deepspeed 如何针对性地构建一个高效的大模型架构,从而提升模型的推理性能。
从初始化说起
上一篇博客中其实已经谈及了很多关于 deepspeed 推理引擎的实现,因此这里我们简单地过一下:
当我们写出如下代码,并运行后:
1 2 3 4 5 6 7 8 9 10 11 12 import deepspeedfrom transformers import AutoTokenizer, AutoModelForCausalLM"tp_size" : 8 },None if args.pre_load_checkpoint else args.checkpoint_json,True )
deepspeed 的 init_inference 会帮助我们记录模型推理 config,并启动推理引擎 InferenceEngine。若 replace_with_kernel_inject=True,那么推理引擎在构建时会扫描整个模型,将其中的某些层替换为 deepspeed 内部实现的高性能网络层,从而实现加速模型推理的效果。
而对于 llama2 模型,deepspeed 甚至内部实现了整个模型,因此可以直接替换为 deepspeed 内部的 DeepSpeedLlama2Inference 类。具体过程见下图:
我们把实际运行过程中的替换模块部分的 log 信息打印出来:可以发现,每一个 LlamaDecoderlayer 都被替换了(博主这边是 llama-1,因此替换成了 DeepSpeedGPTInference 😢)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 'deepspeed.module inject.containers.llama.LLAMALayerPolicy' >
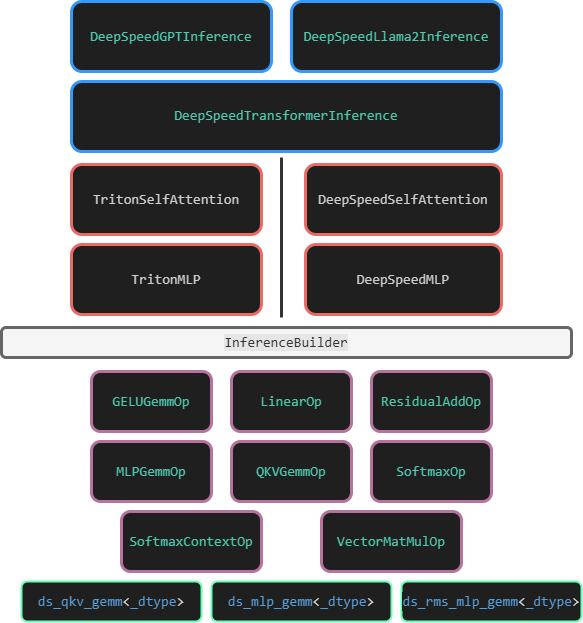
明显可以观察到两点:1)deepspeed 使用 DeepSpeedSelfAttention 和 DeepSpeedMLP 替换并融合了 llama 的 Attention 和 MLP,以及 layernorm。2)deepspeed 在底层使用了自己的高性能算子,例如:QKVGemmOp 和 MLPGemmOp 等。 接下来,我们先探究 DeepSpeedSelfAttention 和 DeepSpeedMLP 的实现,再来看看这些 Op 是如何实现的。
高性能网络层的实现
为避免被绕晕,先将一张大致描述 deepspeed 推理代码框架图呈上:
DeepSpeed-Inference
从上图中可以看到,DeepSpeed Inference 实现的大模型推理类,都是 DeepSpeedTransformerInference 的派生类。目前为止,一共有如下几种类:
DeepSpeedBloomInference
DeepSpeedBERTInference
DeepSpeedLlama2Inference
DeepSpeedGPTInference
DeepSpeedMegatronGPTInference
DeepSpeedOPTInference
但大多数的推理类继承后的实现非常平凡,因此我们直接来看 DeepSpeedTransformerInference 实现。
首先要明确的是,DeepSpeedTransformerInference 对应于一个大模型的一层 transformer 层,而非整个大模型。该类支持使用 triton 作后端优化推理。该类有两个关键的成员,DeepSpeedMLP 和 DeepSpeedSelfAttention。
allocate workspace
接下来我们一步步地看看它的 forward 实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def forward (self, input =None , input_mask=None , attention_mask=None , attn_mask=None , head_mask=None , layer_past=None , get_key_value=False , get_present=False , encoder_output=None , enc_dec_attn_mask=None , x=None , encoder_hidden_states=None , encoder_attention_mask=None , use_cache=False , alibi=None , output_attentions=False , layer_head_mask=None , past_key_value=None , **kwargs ):if attn_mask is None else attn_mask) if attention_mask is None else attention_maskif self.config.layer_id == 0 and self._alloc_workspace:input .size()[1 ],input .size()[0 ], DeepSpeedTransformerInference.layer_id, self.config.mp_size,if dist.is_initialized() else 0 , self.config.max_out_tokens,False
这里的 allocate_workspace 对应了初始化时传入的分配内存空间的函数,实际上调用的是 deepspeed 包装的 C++ CUDA 实现 :
1 2 3 4 5 6 7 8 9 def __init__ (self ):if config.dtype == torch.float32:elif config.dtype == torch.bfloat16:else :True
1 2 3 4 InferenceContext::Instance ().GenWorkSpace (num_layers, num_heads, batch_size,sizeof (T), rank,
这里提一句大模型推理所需内存的计算方法。即刨除大模型本身的参数占用内存,还需要多少内存来完成推理:
1 2 3 4 5 6 7 8 size_t activation_size = 10 * (num_heads * effective_head_size) * batch_size;size_t temp_size = batch_size * (num_heads / mp_size) * max_out_tokens;size_t cache_size =2 size_t workSpaceSize = ((external_cache ? (activation_size + temp_size)
具体的推导步骤可以参考大模型训练时占用内存 的知乎文章 。这里做简要注解:
transformer 模型的层数为 l l l
隐藏层维度为 h h h
注意力头数为 a a a
词表大小为 v v v
批次大小为 b b b
序列长度为 s s s
在多头注意力中,我们有 Q = X W Q Q=XW_Q Q = X W Q K = X W K K=XW_K K = X W K V = X W V V=XW_V V = X W V X X X Q Q Q K K K V V V 3 b s h 3bsh 3 b s h 5 b s h 5bsh 5 b s h activation_size 直接分配了 10 b s h 10bsh 10 b s h
代码中 temp_size 是用来存放注意力计算 Q K T QK^T Q K T b a s 2 bas^2 ba s 2
每个 batch 的每一层 transformer 都需要一个 KV cache, 因此总大小为 2 b s l h × 2bslh \times 2 b s l h × cache_size 的计算代码对应。
attention
接下来我们看看 attention 的计算过程。准备好函数的各项参数后,直接调用 DeepSpeedSelfAttention:forward 就可以算出注意力值了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 if input .shape[1 ] > 1 :None if layer_past is not None else self.layer_pastwith torch.no_grad():input ,
self.attention 直接对应了 DeepSpeedSelfAttention 的实现,因此再把目光转向下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def forward (self, input , input_mask, head_mask=None , layer_past=None , get_present=False , encoder_hidden_states=None , encoder_attention_mask=None , output_attentions=False , norm_w=None , norm_b=None , alibi=None ):if not self.config.pre_layer_norm:input =input ,is not None ,False ,else :input =input ,input =context_layer, weight=self.attn_ow)1 ]if self.config.mlp_after_attn and self.mp_group is not None and dist.get_world_size(group=self.mp_group) > 1 :return (output, key_layer, value_layer, context_layer, inp_norm)
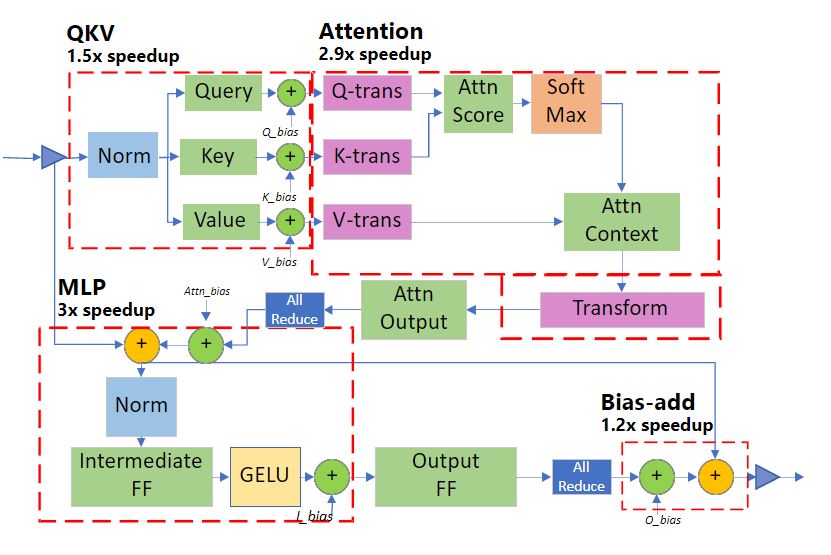
这里涉及到了四个 Op 算子,流程如下图。QKVGemmOp 计算了 pre layer norm 和 Q = X W Q Q=XW_Q Q = X W Q SoftmaxContextOp 计算了 s o f t m a x ( ( Q K T ) / n d i m ) V softmax((QK^T)/\sqrt{n_{dim}})V so f t ma x (( Q K T ) / n d im ) V VectorMatMulOp 计算了 A t t n W O {Attn}W_O A tt n W O
mlp
attention 计算过程结束后,紧接着就是 MLP 的计算过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 self.layer_past = presents if layer_past is None else None input , inp_norm, self.attention.attn_ob)if not self.config.pre_layer_norm:if get_present:if self.config.return_single_tuple:return (output, )elif self.config.return_tuple:return output if type (output) is tuple else (output, attn_mask)else :return output
当然,self.mlp 也对应着 DeepSpeedMLP 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def forward (self, input , residual, residual_norm, bias ):if self.attn_nw is None :input =residual_norm,else :input =input ,is not None ,input ,if bias is not None else self.output_b,if self.mp_group is not None and dist.get_world_size(group=self.mp_group) > 1 :return residual
这里涉及到了四个 Op 算子,流程如下图。MLPGemmOp 计算了 FFN,ResidualAddOp 计算了偏移加法。
高性能算子的实现
deepspeed inference v1 版本的算子代码很多。我这里只挑重点,一起来看一下 Attention 部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template <typename T>void launch_bias_add_transform_0213 (T* output, T* k_cache, T* v_cache,const T* vals, const T* bias, int batch_size, int seq_length, unsigned seq_offset, int all_tokens, int hidden_dim, int heads, int num_kv, int rotary_dim, bool rotate_half, bool rotate_every_two, cudaStream_t stream, int trans_count, int max_out_tokens, float rope_theta) 3 ;int head_ext = 1 ; dim3 block_dim (hidden_dim / heads, (heads / head_ext)) ;dim3 grid_dim (batch_size, seq_length, (trans_count * head_ext)) ;0 , stream>>>(output,0 ? (heads / num_kv) : 1 ,0 ? num_kv : heads,3 ,