if self._config.enable_cuda_graph andnot self.local_cuda_graph: # 如果可以的话 使用 cuda graph 推理 if self.cuda_graph_created: outputs = self._graph_replay(*inputs, **kwargs) else: self._create_cuda_graph(*inputs, **kwargs) outputs = self._graph_replay(*inputs, **kwargs) # 不行就直接推 else: outputs = self.module(*inputs, **kwargs)
if self.model_profile_enabled and self._config.enable_cuda_graph: # 结束计时 get_accelerator().synchronize() duration = (time.time() - start) * 1e3# convert seconds to ms self._model_times.append(duration)
return outputs
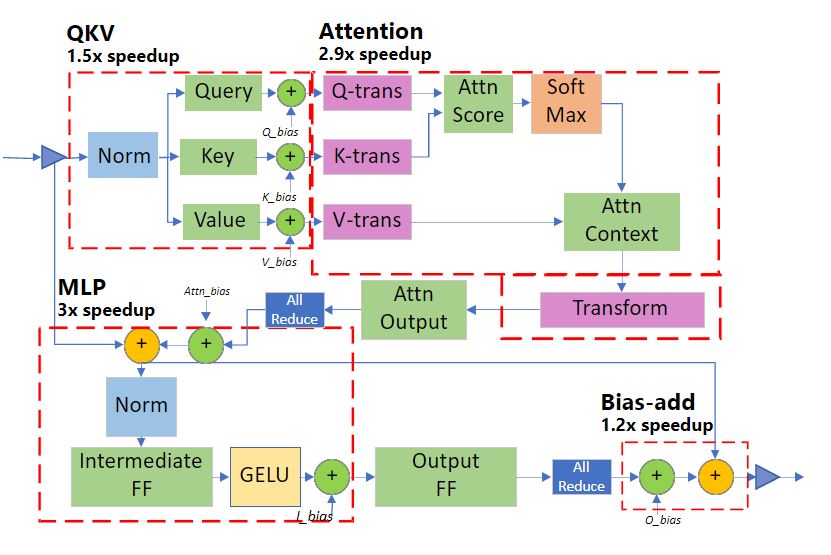
代码中提到的 cuda graph 是 cuda10 中为了加速模型计算流程而提出的优化特性,简单地说,CUDA Graphs 将整个计算流程定义为一个图,通过提供一种由单个 CPU 操作来启动图上的多个 GPU kernel 的方式减少 kernel 的启动开销。
自动化张量并行 automatic tensor parallelism if tp_size > 1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 1. User specified Tensor Parallelism for client_module, injection_policy in self.injection_dict.items(): # 1.1 construct the tuple and pass that instead of a string or dict. config.injection_policy_tuple = injection_policy self._apply_injection_policy(config, client_module) # 2. DeepSpeed Kernel Injection if config.replace_with_kernel_inject: self._apply_injection_policy(config) # 3. Automatic Tensor Parallelism elif config.tensor_parallel.tp_size > 1: # tp_parser model parser_dict = AutoTP.tp_parser(model) for client_module, injection_policy in parser_dict: config.injection_policy_tuple = injection_policy self._apply_injection_policy(config, client_module)
def_apply_injection_policy(self, config, client_module=None): # client_module is only passed when using the injection_dict method. checkpoint_dir = config.checkpoint checkpoint = SDLoaderFactory.get_sd_loader_json(checkpoint_dir, self.checkpoint_engine) if checkpoint_dir isnotNoneelseNone generic_injection(self.module, dtype=config.dtype, enable_cuda_graph=config.enable_cuda_graph)
ifisinstance(self.module, torch.nn.Module): # config is our DeepSpeedInferenceConfig and self.config is the HF model config replace_transformer_layer(client_module, self.module, checkpoint, config, self.config)
defreplace_module(model, orig_class, replace_fn, _replace_policy, checkpoint=None): """ Scan the model for instances of ``orig_clas:`` to replace using ``replace_fn``. Arguments: model (torch.nn.Module): the model to augment orig_class (torch.nn.Module): the module to search for replace_fn (method): a method to convert instances of ``orig_class`` to the desired type and return a new instance. Returns: A modified ``model``. """ # ... # policy = {} if orig_class isnotNone: policy.update({orig_class: (replace_fn, _replace_policy)}) else: for plcy in replace_policies: # instantiate a throw-away policy in order to populate the _orig_layer_class _ = plcy(None) ifisinstance(plcy._orig_layer_class, list): for orig_layer_class in plcy._orig_layer_class: policy.update({orig_layer_class: (replace_fn, plcy)}) elif plcy._orig_layer_class isnotNone: policy.update({plcy._orig_layer_class: (replace_fn, plcy)}) replaced_module, _ = _replace_module(model, policy, state_dict=sd) return replaced_module
defreplace_fn(child, _policy, layer_id=0, prefix="", state_dict=None): training = False# todo: refactor this part to go in the config if training: # copy relevant state from child -> new module new_module = replace_with_policy(child, _policy, config.triangular_masking) else: # copy relevant state from child -> new module if config.replace_with_kernel_inject: new_module = replace_with_policy(child, _policy, config.triangular_masking, inference=True, layer_id=layer_id) else: new_module = replace_wo_policy(child, _policy, prefix=prefix, state_dict=state_dict) return new_module
# 4. deal with data types -- needs refactor to use dtype instead of fp16 if config.dtype in [torch.float16, torch.bfloat16, torch.int8]: _container.convert_to_required_dtype()
# 5. Set the quantization config quantizer = GroupQuantizer(q_int8=quantize) _container.set_quantization_config(quantizer)
# 6. create a DS Inference config object _container.create_ds_model_config()
# 7. use the config and create the module _container.create_module()
# 8. transpose the weights and bias if needed _container.transpose()
# 9. deal with tensor parallelism. _container.apply_tensor_parallelism(mp_replace)
# 10. copy the tensors from the model-specific container to the new module _container.copy_data_to_new_module()
# 11. set global for generic checkpoint loading global container_g if container_g isNone: container_g = _container return _container.module