awk 从入门到入土
awk 从入门到入土
何为 awk ?
awk 是一种用于文本处理、数据提取分析和报告常用的 linux 工具(命令)。与 sed 和 grep 一样,在日常编程和使用 linux 操作系统中,它是提升效率的法宝。
awk 处理的数据可以来自标准输入(stdin)、文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk 内有完备的“语言”,可以写出数组、函数、分支等复杂结构,且语法与 C 语言的相通之处。相比 sed grep 命令,灵活性是 awk 最大的优势,但其包含了复杂语法、正则表达式、内置变量(函数)也让很多人望而生畏。
另外,该工具之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
awk 到底能做什么?
awk 功能强大,特点繁杂,若开篇介绍用法会让该博文显得杂乱无章,让人毫无阅读兴趣。我尝试抛开复杂的语法和命令格式,先利用几个例子让读者了解一下 awk 的工作方式和功能是怎样的。相信你一定会被 awk 强大的信息提取能力所折服。当你熟练掌握 awk 后,就再也不会烦恼于数据的格式化输出和信息提取了😄。
awk 对文件操作
-
逐行扫描文件。awk 的基本功能是搜索/匹配文件中包含特定模式的文本。当其中的内容匹配到了该模式时,awk 会在上执行指定的操作。awk 基本以行为处理单元,以这种方式一行一行地处理文本,直到遇到文件的末尾。
1
2
3
4
5例1:打印文件的每行的第一列(域)
> awk '{print $1}' filename
例2:打印文件的每一行
> awk '{print $0}' filenameprint 是 awk 中最常用的操作,可打印出后面的字符,若有多个变量,用’,'连接。虽然脚本中只写了对一行的操作,但由于 awk 会以逐行的方式遍历整个文本,因此最终该命令会打印出每一行的结果。
-
将每一行输入拆分为字段。awk 逐行扫描文件后,再对行中的列(域)做匹配。可以使用 $n 来表示第n列的字符,而 $0 表示整一行。内置变量 $NF 表示字段总数,因此 $NF 可表示倒数第一列。对列的分割默认是空格,但也可以通过改变内置变量 FS 来改变分割符号。
1
2
3例3:从 /etc/passwd 文件中,按照":"分割打印出第2列和倒数第一列、倒数第二列:
> awk -F":" '{print $2,$(NF),$(NF-1)}' /etc/passwd (或)
> awk 'BEGIN{FS=":"} {print $2,$(NF),$(NF-1)}' /etc/passwdBEGIN 块表示该脚本块需要在 awk 逐行遍历文件前就执行,且只执行一次,通常用于初始化内部变量或计算数据。与之相反,END 块只能在awk 逐行遍历文件后执行,且执行一次
-
比较输入行/字段与模式。比较或匹配模式通常要涉及到正则表达式的相关知识,关于正则表达式可参考菜鸟教程。但 awk 还提供了类似 C 语言中的判断指令,从而做出更复杂的条件判断和算术逻辑。甚至可以完全抛弃文件,单独做一些复杂计算。
1
2
3
4
5例4:找到 test.txt 中最后一列大于 5000 的列并打印出来:
> awk '{if ($NF > 5000) print $NF}' test.txt
例5:使用 awk 命令计算 exp(5):
> awk 'BEGIN {param = 5; result = exp(param); printf "Result is %f.\n", result}'awk 有大量的内置变量和内置函数,具体介绍在后小节。
-
对匹配的行执行动作。awk主要的操作就是print,将数据按规定的格式打印出来。但需要注意,awk 命令一般不直接修改文件,只能将输出信息重定向到某一个文件中(非源文件)。
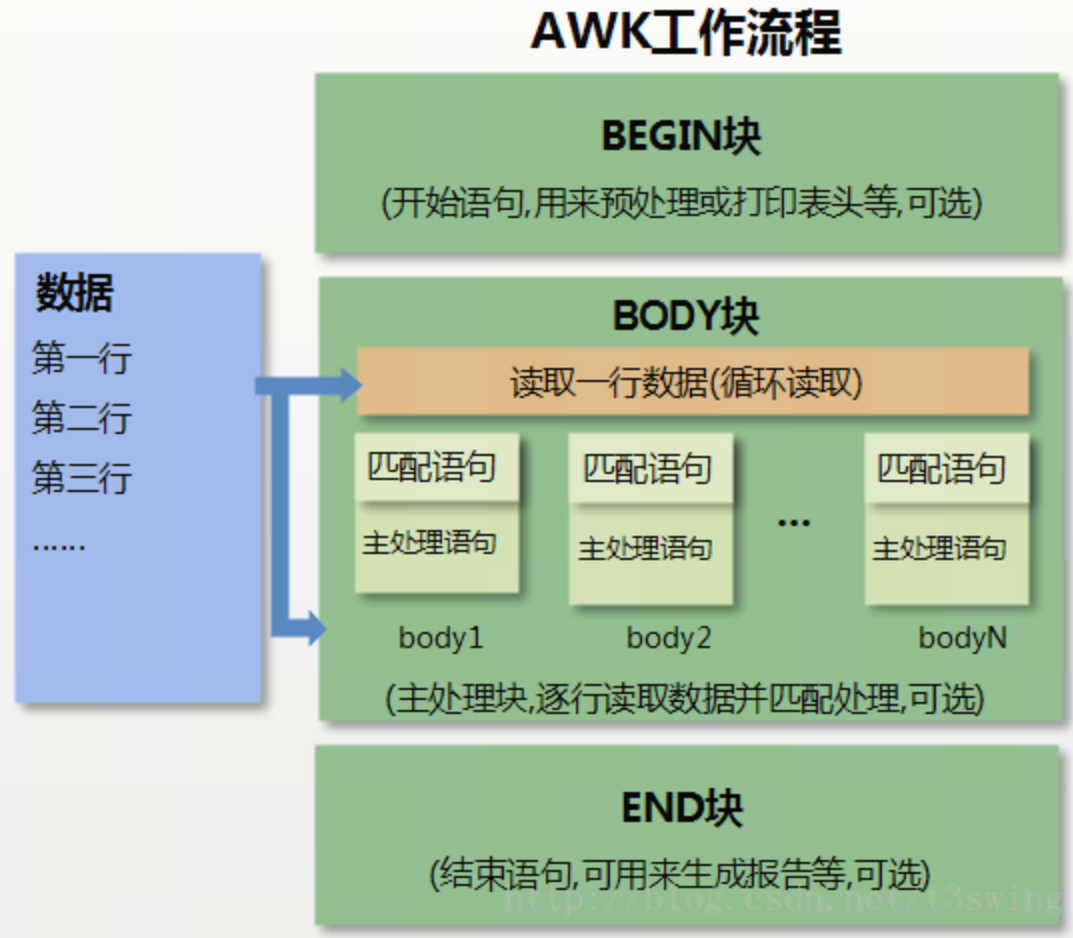
可用此图再回顾一下 awk 的四步流程。总结一下,awk 适用于数据文件转换和编制格式报告,并且能做到:1、格式化地输出信息。2、各种复杂的算术逻辑运算和字符串操作。3、配合逐行特性,实现条件和循环结构。
awk 命令格式和选项
语法形式
使用 awk 命令时,一般遵循下面两种形式书写:
1 | |
接下来的几个小节开始介绍 awk 各个部分的使用规则:
常用命令选项 —— [options]
- -F <fs> 或 --field-separator <fs> :fs 为指定输入分隔符,也可以是字符串或正则表达式。默认的分隔符是连续的空格或制表符
- -v <var>=<value> 赋值一个用户定义变量,将外部变量传递给 awk
- -f <scripfile> 从脚本文件中读取awk命令
- -m[fr] <val]> 对 val 值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
awk 模式和操作 —— ‘script’
首先回顾一下前文所说:
awk 的基本功能是搜索/匹配文件中包含特定模式的文本。当其中的内容匹配到了该模式时,awk 会在上执行指定的操作。awk 基本以行为处理单元,以这种方式一行一行地处理文本,直到遇到文件的末尾。
模式和操作无疑是 awk 命令中最重要的部分,而它们都会在 ‘script’ 处集中表达,其中
模式
模式可以是以下任意一个:
-
正则表达式:使用通配符的扩展集。
1
2例6:从 employee.txt 文件中找到含有 manager 的行并打印
> awk '/manager/ {print}' employee.txt‘/manager/’ 即要匹配字符串中含有 manager 的子串。找到后打印文件所在行,{print} 默认打印一行的所有列。
-
关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。
1
2例7:打印 log.txt 中第一列大于2并且第二列等于 'Are' 的行的前三列:
> awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt$1>2 && $2==“Are” 表示第一列大于2且第二列为 ‘Are’,可以仅写一个条件,也可以完整地写出 if 语句结构,见下例。
-
模式匹配表达式:用运算符~(匹配)和!~(不匹配)。
1
2例8:打印 test.txt 文件中第二列,并匹配以80开头并以80结束的行:
> awk '{if ($2 ~ /^80$/) print}' test.txt -
BEGIN 语句块、pattern 语句块、END 语句块。
1
2例9:找到 test.txt 文件中最长行的所占的字符数
> awk 'BEGIN{max=0} {if (length($0) > max) max=length($0)} END{print max}' test.txt由三个语句块组成的模式甚至可看成一个简单 C 程序。length() 是 awk 的内置函数。更多函数可见菜鸟教程的整理
由于 awk 的逐行处理文本的特性,很多重要的全局信息往往通过内置变量表达,在书写 awk 命令时常需要快速查表并使用。限于篇幅不详细介绍内置变量的使用了,不太懂的话可以参考这篇博客:
| 内置变量 | 含义 |
|---|---|
| NF | 字段个数,(读取的列数) |
| NR | 记录数(行号),从1开始,新的文件延续上面的计数,新文件不从1开始 |
| FNR | 读取文件的记录数(行号),从1开始,新的文件重新从1开始计数 |
| FS | 输入字段分隔符,默认是空格 |
| OFS | 输出字段分隔符 默认也是空格 |
| RS | 输入行分隔符,默认为换行符 |
| ORS | 输出行分隔符,默认为换行符 |
| FILENAME | 输入的文件名 |
1 | |
操作
操作由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大括号内,主要部分是:
变量或数组赋值
输出命令
内置函数
控制流语句
awk 的变量 —— [var=value]
除了之前提到的内置变量外,用户在使用 awk 时也可以自定义变量:var=value。当然也可以直接使用 awk 语言定义
1 | |
回顾例9,变量的设置可以帮助程序员用类C的语法完成更加复杂的任务。
1 | |
awk 常常与其他 shell 指令合用,在传递数据时也需要通过变量:
1 | |