更新于:2024-04-09T23:18:23+08:00
深入理解计算机系统之实现动态存储分配器
简介
本实验需要用 C 语言实现一个动态的存储分配器,也就是你自己版本的 malloc,free,realloc 函数。我们需要修改的唯一文件是 mm.c,包含如下几个需要实现的函数:
int mm_init(void); 在调用 mm_malloc,mm_realloc 或 mm_free 之前,调用 mm_init 进行初始化,正确返回 0void *mm_malloc(size_t size); 在堆区域分配指定大小的块,分配的空间,返回的指针应该是 8 字节对齐的void mm_free(void *ptr); 释放指针指向的 blockvoid *mm_realloc(void *ptr, size_t size) 返回指向一个大小为size的区域指针,满足一下条件
动态内存申请
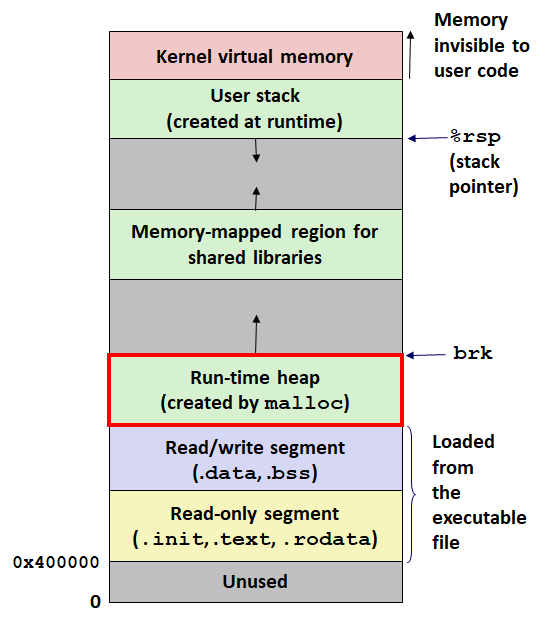
使用动态内存分配器 ,可为在程序运行时确定并申请虚拟内存空间。动态内存分配器管理的区域被称作堆 。每个进程的内存分布如下:
动态内存申请器将堆这块区域当作一系列大小不同的块来管理,块或者已分配的,或者是空闲的。
malloc & free
通常,有关内存管理, Linux 提供的系统调用主要有两种:sbrk() 函数:
1 2 3 4 5 #include <unistd.h> int brk (const void *addr) ;void *sbrk (intptr_t incr) ;
第二种方法使用的是 mmap() 函数
1 2 3 4 5 #include <sys/mman.h> void *mmap (void *start, size_t length, int prot, int flags, int fd, off_t offset) ;int munmap (void *start, size_t length) ;
值得注意的是,mmap() 还有另一个重要的作用就是实现快速的 I/O,它通过直接将文件映射到虚拟内存,可以直接对其进行读写操作,而不需要使用系统调用 read/write,大幅度提高了速度。
但在实际的使用中,我们不可能每次需要内存的时候,都用 sbrk 或 mmap 函数(系统调用速度很慢),这会大幅度降低我们程序的效率。通常我们采用的是一种类似于缓存的思想:先使用 sbrk 函数向内核索取一大片的内存空间,然后再使用一定的手段对这段空间进行管理。只有当这段空间不够用时,再向内核拿,这样就提高了效率。这也正是 malloc 函数库所起到的作用。
简单来说,malloc 函数主要是通过维护一个空闲列表来实现内存的管理的,具体涉及到的数据结构就是链表。对每一个内存块,我们使用链表将它们串在一起,当需要使用的时候,我们从链表中寻找大小适合的内存块,并且从空闲链表中删除,拿给用户。当用户用完某个内存块的时候,我们就将其重新插入回空闲链表,这样就实现了简单的内存分配和释放。
数据结构
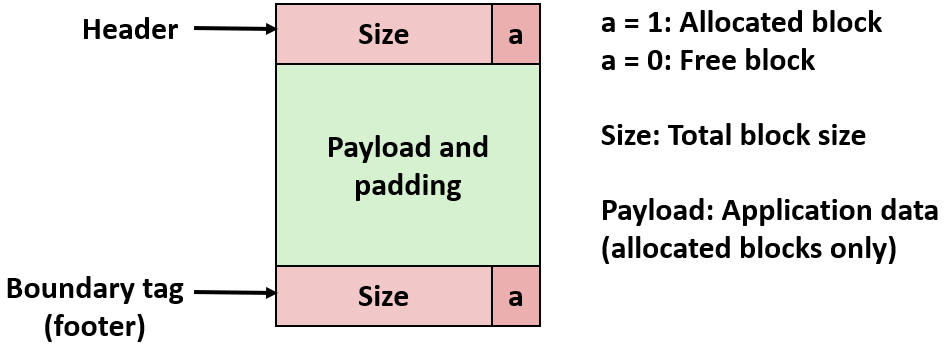
首先介绍实验中的内存分配块的数据结构,我使用边界标记的堆块的格式区分块的边界。其中,头部 (header) 和脚部 (footer) 分别占 4 字节大小,块地址双字对齐,大小为8的整数倍。这样做的好处是,如果用 32 位来存储块大小,低 3 位肯定都为0,相当于低 3 位可以预留出来,用作指示该块是否是一个空闲块。
块的数据结构确定后,需要一个空闲链表来管理空闲块,参考书本上关于空闲链表的表述,也采用下图方式管理。
具体实现
宏定义
对于这个实验来说,良好的宏定义可提高编程效率,方便阅读书写代码。下面列出部分关键宏,并加以解释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #define WSIZE 4 #define DSIZE 8 #define CHUNKSIZE (1<<12) #define PACK(size,alloc) ((size) | (alloc)) #define GET(p) (*(unsigned int *)(p)) #define PUT(p,val) (*(unsigned int *)(p) = (val)) #define GET_SIZE(p) (GET(p) & ~0x7) #define GET_ALLOC(p) (GET(p) & 0x1) #define HDRP(bp) ((char *)(bp)-WSIZE) #define FTRP(bp) ((char *)(bp)+GET_SIZE(HDRP(bp))-DSIZE) #define NEXT_BLKP(bp) ((char *)(bp)+GET_SIZE(((char *)(bp)-WSIZE))) #define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))
GET 宏读取和返回指针 p 的引用,这里强制转换是非常重要的,类似地,PUT 宏将 val 存放到 p 指向的字中。GET_SIZE 宏和 GET_ALLOC 宏从 p 处的获得块的大小和分配标识位,注意到,这里的指针 p 应该指向整个块。
之后的指针 bp 指向的就是块的有效负载。HDRP 宏和 FTRP 宏分别指向这个块的头部和脚部,因为有效载荷紧挨着头部,头部大小为 4 字节,所以 (char *)bp-WSIZE 就是指向头部,脚部大小也是 4 字节,且 GET_SIZE 宏指的是整个块大小,因此要减去 8 个字节才是指到了脚部。而对于 NEXT_BLKP 宏和 PREV_BLKP 宏,情况更加复杂,程序需要读到上个块(下个块)的脚部(头部),才能通过加上块大小偏移量来获得下一个块的指针。
创建空闲块链表
在调用 mm_malloc 和 mm_free 函数之前,必须要调用 mm_init 进行初始化。mm_init 函数创建了一个空的空闲块链表,然后调用 extend_heap 函数,做最初的堆空间扩展。
参见上图空闲链表,mm_init 首先创建了一个不使用的填充字,然后创建 8 个字节的序言块,它只有头部和脚部,但它永不释放,类似于实现单链表时的链表头。最后创建一个结尾块,用于标识空闲链表的结束。加上了填充块后,开头的这几个块一共占用 16 个字节,正好是空闲链表所要求的的最小字节。
1 2 3 4 5 6 7 8 9 10 11 12 13 int mm_init (void ) if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1 )return -1 ;0 ); 1 * WSIZE), PACK(DSIZE, 1 )); 2 * WSIZE), PACK(DSIZE, 1 )); 3 * WSIZE), PACK(0 , 1 )); 2 * WSIZE);if (extend_heap(CHUNKSIZE / WSIZE) == NULL )return -1 ;return 0 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static void *extend_heap (size_t words) {char *bp;size_t size;2 ) ? (words + 1 ) * WSIZE : words * WSIZE;if ((long )(bp = mem_sbrk(size)) == (void *)-1 )return NULL ;0 )); 0 )); 0 , 1 )); return coalesce(bp);
其中 extend_heap() 函数用于堆拓展,每次拓展的大小都应该为 8 的倍数。在拓展完成后,需要注意到,如果堆顶端是一个空闲块 ,那么就需要调用 coalesce() 函数将空闲块合并。
合并块
coalesce() 函数是对书上所述的合并块方式的简单实现。注意到,引入序言块和结尾块的好处就是,我们可以少考虑一些复杂的边界情况,因为所有要处理的块都位于链表的“中间”。这样做可以减少编码复杂度,更不容易出错。然后,宏定义也帮助我们很多。比如获取上一个块(下一个块)的分配位和大小时,只需要使用 GET_ALLOC(FTRP(PREV_BLKP(bp))) 即可,代码更具可读性(虽然好像还是很麻烦):sweat_smile: 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 static void *coalesce (void *bp) {size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));size_t size = GET_SIZE(HDRP(bp));if (prev_alloc && next_alloc)return bp;else if (prev_alloc && !next_alloc){0 ));0 ));else if (!prev_alloc && next_alloc){0 ));0 ));else {0 ));0 ));return bp;
除了之前提到的,在 extend_heap 函数中需要调用 coalesce 函数来合并空闲块,在 mm_free 中也需要调用。事实上,只要有操作可以多出一个空闲块,都需要调用 coalesce 函数来合并。
1 2 3 4 5 6 7 8 9 void mm_free (void *bp) {if (bp == 0 )return ;size_t size = GET_SIZE(HDRP(bp));0 ));0 ));
分配块
使用 mm_malloc 函数来分配块,首先必须要调整分配大小,因为用户传入的数据是有效负荷需要的大小,不包括头部和脚部,而且没有实现 8 字节对齐。因此,必须先加上 8 字节后再对齐,才能进行分配。
调整完后,需要使用 find_fit 函数找到适合的链表空闲块,如果找到了,就放置在空闲块中,如果没有足够大的空闲块,那就需要调用 extend_heap 函数从堆中取出更多的内存了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void *mm_malloc (size_t size) {size_t asize;size_t extendsize;char *bp;if (size == 0 )return NULL ;if (size <= DSIZE) {2 * (DSIZE);else {1 )) / (DSIZE));if ((bp = find_fit(asize)) != NULL ) {return bp;if ((bp = extend_heap(extendsize / WSIZE)) == NULL ) {return NULL ;return bp;
对于 find_fit 函数,这里实现的是 first-fit 函数,从链表头开始搜索,只要找到了足够大的空闲块,就返回。
1 2 3 4 5 6 7 8 9 static void *find_fit (size_t size) {void *bp;for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0 ; bp = NEXT_BLKP(bp)) {if (!GET_ALLOC(HDRP(bp)) && (size <= GET_SIZE(HDRP(bp)))) {return bp;return NULL ;
放置函数 place 实现如下,特别注意,只有剩下的空间多于 16 字节时,才能组成一个空闲块。这意味着较小的碎片已经被我抛弃了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static void place (void *bp, size_t asize) {size_t csize = GET_SIZE(HDRP(bp));if ((csize - asize) >= (2 * DSIZE)) {1 ));1 ));0 ));0 ));else {1 ));1 ));
realloc
最后来关注一下 realloc 函数。这里由于时间关系,先实现了一个初步版本。排除了一些可能的极端情况后,先调用 mm_malloc 函数分配一个新的块。然后,就将旧数据从旧的地址移动到新的地方,并释放旧地址空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void *mm_realloc (void *ptr, size_t size) {size_t oldsize;void *newptr;if (size == 0 ) {return 0 ;if (ptr == NULL ) {return mm_malloc(size);if (!newptr) {return 0 ;if (size < oldsize)memcpy (newptr, ptr, oldsize);return newptr;
事实上,realloc 函数有很多可以优化的点。首先,如果 realloc 传入的 size 比之前还小,显然我们不需要进行拷贝,直接可以考虑对当前块进行分割。其次,如果下一块是一个空闲块的话,我们可以直接将其占用。这样的话可以很大程度上减少外部碎片,充分地利用了空闲的块。接着,如果下一个块恰好是堆顶,我们也可以考虑直接拓展堆,这样的话就可以避免再去搜索空闲链表,提高效率。
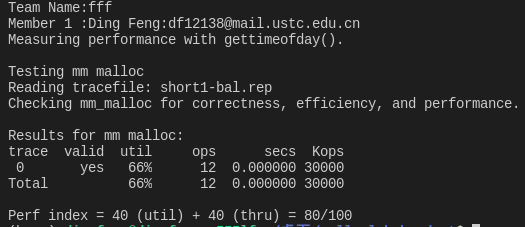
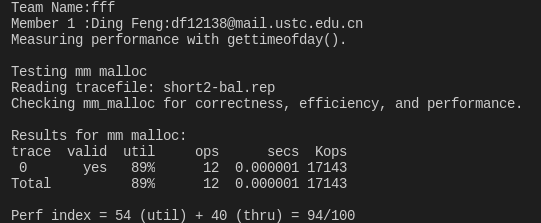
实验结果
由于时间关系,本次实验仅仅实现了一个非常简陋的 malloc 版本,因此得分较低。