更新于:2024-04-09T23:16:04+08:00
Apollo Cyber RT 调度系统解析
前言
上篇博客中 ,我简要地给大家介绍了 Apollo 系统,以及它的代码文件结构,并说明了一下 Cyber RT 在 Apollo 系统中的地位(是的,我调整了一下博客的内容,使之变得更加均衡合理)。Cyber RT 在系统的任务调度方面有重要的作用,又和实时系统要求密切相关。因此,我打算将调度系统作为一个切入点,在本篇博客中,我将会给大家介绍一下 Cyber RT 的调度系统。
Cyber中的调度
自动驾驶系统的有三大流程:感知、决策、执行 。例如,车上的传感器感知到障碍物,判断其类型、运动轨迹等,再做出决策,最后再到刹车、油门和方向的控制,这会经过一系列模块的计算。这些模块在计算过程中会产生数据依赖,如果用箭头将模块间的数据依赖表示出来,就会形成图的拓扑结构。
在 Apollo 项目中,通常使用 DAG file 来描述计算图 的拓扑结构。由于自动驾驶系统牵扯到很多的步骤,有很复杂的流程,相应的,这些计算图也十分庞大。因此,如何调度整个计算图使系统能满足各种时间约束,达到系统的实时性和确定性,是个巨大的挑战。
接下来,我们就详细地剖析一下 Cyber RT 的调度系统💪!
conf 配置文件
Cyber 调度的配置文件在 cyber/conf 文件夹中,配置文件详细说明了线程名、线程的 CPU 亲和性、调度策略,对于协程,还有分组情况、协程的优先级等等。
方便起见,我从官方文档 中举例,文档对每项设置的说明都非常具体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 scheduler_conf { policy: "classic" process_level_cpuset: "0-7,16-23" # all threads in the process are on the cpuset threads: [{ name: "async_log" cpuset: "1" policy: "SCHED_OTHER" # policy: SCHED_OTHER,SCHED_RR,SCHED_FIFO prio: 0 } , { name: "shm" cpuset: "2" policy: "SCHED_FIFO" prio: 10 } classic_conf { groups: [{ name: "group1" processor_num: 16 affinity: "range" cpuset: "0-7,16-23" processor_policy: "SCHED_OTHER" processor_prio: 0 tasks: [{ name: "E" prio: 0 } } ,{ name: "group2" processor_num: 16 affinity: "1to1" cpuset: "8-15,24-31" processor_policy: "SCHED_OTHER" processor_prio: 0 tasks: [{ name: "A" prio: 0 } ,{ name: "B" prio: 1 } ,{ name: "C" prio: 2 } ,{ name: "D" prio: 3 } } } }
那么上面的 conf 文档描述了怎么样的调度策略呢?
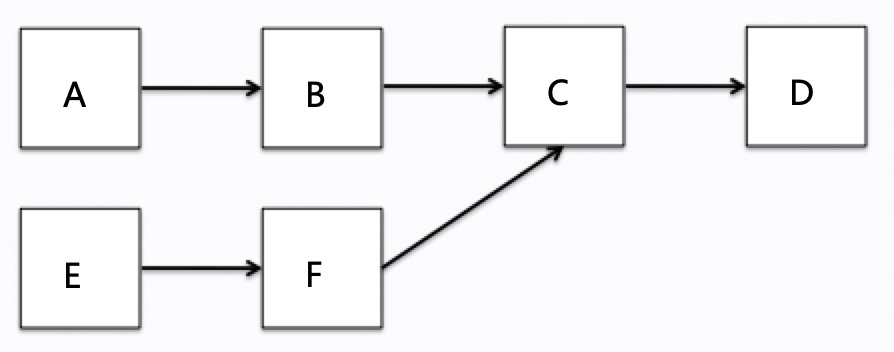
还是参考官方文档 ,对于配置文件中已经编排好的任务,其拓扑结构就依据优先级确定了。我们根据上面的 conf 文档,可以简单画出任务的优先级拓扑 情况,如下图,A、B、C、D 任务在第一个 group 中执行,E在第二个 group 中执行,对于没有出现在配置中的任务,比如F默认会放到第一个 group 中执行(下文会提到哦)。 而且配置中我们对于任务进行了优先级设置,A、B、C、D 的任务优先级依次增大,正好对应下图的拓扑依赖关系,在链路中越靠后的任务优先级越高。其实,数据也是这样在任务拓扑图中传递,数据走到最后,执行的任务优先级越高,这是为保证整个流程可以快速走完,不被其他流程的任务打断。
调度策略
Apollo 提供了两种调度策略,一种是 classic 策略,在代码中,用 SchedulerClassic 类实现;另一种是 Choreography 策略,代码中用 SchedulerChoreography 类实现。对于这两个策略,我们先给一个大致的描述,好让大家理解之间的差异,稍后在代码分析中,会详细解释这些实现 :smile: 。
classic 策略
较为通用的调度策略
如果对当前自动驾驶车辆上的 DAG 结构不清楚,建议使用此策略
相关协程任务以组为单位与线程作绑定
SchedulerClassic 采用了协程池 的概念,协程不会绑定到具体的 Processor,而是放在全局的优先级队列中。Processor 运行时,每次从最高优先级的任务开始调度执行。
choreography 策略
需要对车上的任务、结构足够熟悉
根据任务的执行依赖关系、任务的执行时长、任务 CPU 消耗情况、消息频率等,对某些任务进行编排
SchedulerChoreography 类采用了本地队列和全局队列相结合的方式。他将主链路 (choreography开头的配置)进行编排;而对非主链路的任务放到线程池中使用 classic 策略执行。
当使用 choreography 策略时,具体该怎么办?Well,根据任务优先级、执行时长、频率与调度之间的关系,任务编排有如下几个依据(经验):
在同一个路径上的任务尽量编排在同一个 Processor 中,如果 Processor 负载过高,可考虑将部分任务拆分到其他 Processor
为防止优先级倒挂,同一个路径上的任务从开始到结束,优先级应逐级升高
不同路径上的任务尽量不 混排
高频且短耗时任务尽量编排在同一个 Processor 上
另:据 Dig-into-Apollo 中的说法,该调度策略与 Go 语言中的 GPM 模型 相似。
Scheduler、Processor & Context
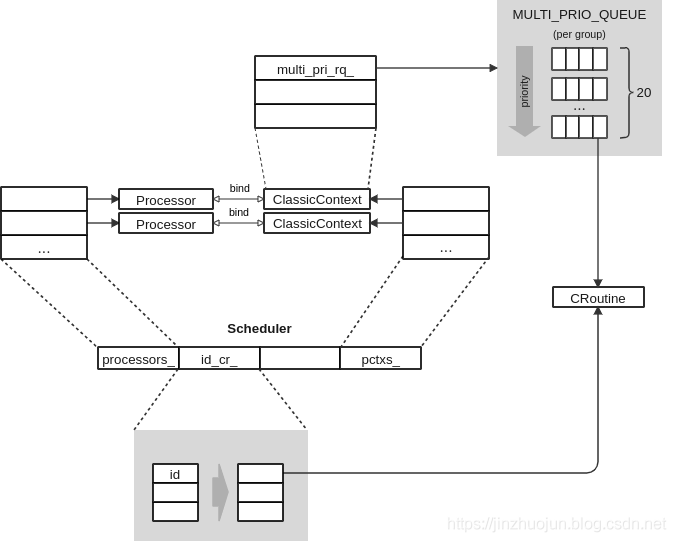
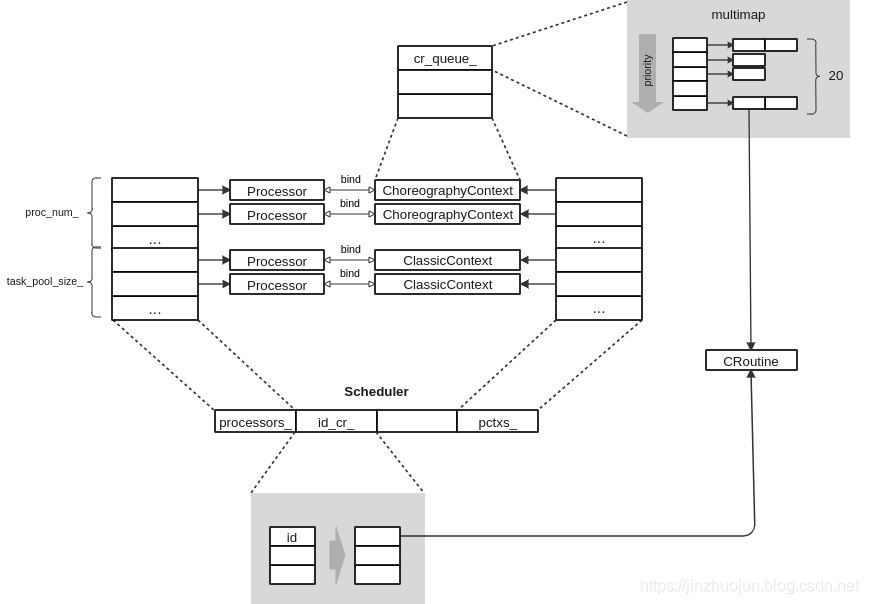
我从参考文献1 中找到一张不错的类关系图,可以很好地帮我说明一下这些类的关系:
Scheduler
Scheduler 类使用单例模式 ,Instance() 方法被第一次调用时会加载 conf 文件,此时会根据配置文件中指定的类型创建 SchedulerClassic 或者 SchedulerChoreography 对象。
这就涉及到 Scheduler 类的构造函数,在这里,我不想展示具体代码的任何细节,因为这只会把原本就复杂的事物越搞越乱(如果你真的想仔细了解,还是亲自下场看一下代码吧),我经过总结,认为其步骤:
读取 conf 配置文件,如果读取配置文件失败,会设置默认值
将内部线程信息保存到查询表中,并设置线程的亲和性和优先级等属性
将所有的任务按照配置文件的要求分为 group ,设置进程级别的cpuset
根据配置文件要求创建线程,并包装为 Processor(执行器),绑定上下文。
这边我要多提一句,对于 choreography 策略,在创建线程时会比较特殊,它依照配置文件的要求,把所有线程分为两个部分(就如你在本篇博客最末尾看到的那样),其中一部分线程与 ClassicContext 绑定,另一部分与 Choreography 绑定,这意味着 choreography 策略负责编排一部分任务:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void SchedulerChoreography::CreateProcessor () for (uint32_t i = 0 ; i < proc_num_; i++) {auto proc = std::make_shared <Processor>();auto ctx = std::make_shared <ChoreographyContext>();BindContext (ctx);SetSchedAffinity (proc->Thread (), choreography_cpuset_,SetSchedPolicy (proc->Thread (), choreography_processor_policy_,Tid ());emplace_back (ctx);emplace_back (proc);for (uint32_t i = 0 ; i < task_pool_size_; i++) {auto proc = std::make_shared <Processor>();auto ctx = std::make_shared <ClassicContext>();BindContext (ctx);SetSchedAffinity (proc->Thread (), pool_cpuset_, pool_affinity_, i);SetSchedPolicy (proc->Thread (), pool_processor_policy_, pool_processor_prio_,Tid ());emplace_back (ctx);emplace_back (proc);
除了构造函数之外,Scheduler 还负责分发、移除任务,也可以唤醒(Notify)某个任务。
Update at 11.00 29th Oct in 2020.
一开始写这篇博客时,并没有把Scheduler 类的创建、分发、唤醒、移除任务讲清楚,那么今天我来把这个坑补上。
首先是创建任务,在 Cyber RT 组件 中,我说过 Component::Initialize() 中创建的处理消息函数,会被首先用于创建协程工厂,然后 Scheduler 会使用 CreateTask() 函数创建协程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 bool Scheduler::CreateTask (std::function<void ()>&& func, const std::string& name, std::shared_ptr<DataVisitorBase> visitor) if (cyber_unlikely (stop_.load ())) {auto task_id = GlobalData::RegisterTaskName (name);auto cr = std::make_shared <CRoutine>(func);set_id (task_id);set_name (name);if (!DispatchTask (cr))return false ;if (visitor != nullptr ) {RegisterNotifyCallback ([this , task_id]() {if (cyber_unlikely (stop_.load ()))return ;this ->NotifyProcessor (task_id);return true ;
在上面的代码中,可以看到协程创建完毕后,还会被分配任务,那么分配任务具体做什么呢?在 SchedulerClassic 类中,DispatchTask() 首先把协程 id 和其指针一一对应起来,放入到 id_cr_ 表中(下图),然后根据配置文件设置这个协程的优先级和协程组,如果配置文件中没有提到该协程,默认放入组 0 中 ,最后将该协程根据其优先级,放入到队列 (下图就有)中,最后唤醒所在组的上下文;对于 SchedulerChoreography 类,还需要多一步来判断协程对应的 Processor 类。那么相似的道理,移除任务就是先将协程停止,从表中、队列中移除。
最后 Scheduler::NotifyProcessor() 会唤醒 Processor ,它首先检查传入 id 对应的协程的状态,然后就调用了上下文的 Notify() 函数,让控制线程的条件变量 唤醒一个线程(Processor 类)。那么等待一个线程呢?也是控制这个条件变量就行了😂,使用 Wait_for 函数就可以满足要求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void ClassicContext::Notify (const std::string& group_name) Mutex ().lock ();Mutex ().unlock ();Cv ().notify_one ();void ClassicContext::Wait () std::unique_lock<std::mutex> lk (mtx_wrapper_->Mutex()) ;Cv ().wait_for (lk, std::chrono::milliseconds (1000 ),return notify_grp_[current_grp] > 0 ; });if (notify_grp_[current_grp] > 0 )
Processor
前面说到,调度器中会创建线程,并包装为 Processor。Scheduler 根据 conf 文件初始化线程,并创建若干个 Processor。注意,我再此强调 Processor 并不是物理上的处理器,本质就是一个线程而已。为了加强印象,也为了后续方便理解,我在这里给出 Processor 的定义代码:
1 2 3 4 5 6 7 8 9 10 11 class Processor {public :private :pid_t > tid_{-1 }; bool > running_{false };
好了,Processor 最重要的部分还是它如何运行。重要到什么程度?额嗯,我甚至可以花大篇幅把这部分代码完整地列出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void Processor::Run () store (static_cast <int >(syscall (SYS_gettid)));store (tid_);while (cyber_likely (running_.load ())) {if (cyber_likely (context_ != nullptr )) {auto croutine = context_->NextRoutine ();if (croutine) {store (cyber::Time::Now ().ToNanosecond ());name ();Resume ();Release ();else {store (0 );Wait ();else {lk (mtx_ctx_);wait_for (lk, std::chrono::milliseconds (10 ));
其实 Processor::Run() 的逻辑很简单,就是不断地调用 ProcessorContext::NextRoutine() 函数,取得下一个协程(任务)。如果没取到,就调用 ProcessorContext::Wait() 等待。如果取到了,就调用 CRoutine::Resume() ,让任务继续运行。
看起来关键是 NextRoutine() 是如何挑选下一个任务的。参考上图,ProcessorContext 有两个派生类 ClassicContext 和 ChoreographyContext 。它们的实现因调度策略不同而不同。前者是按优先级从高到低从所在 group 对应的任务队列中取任务,取到后,需要判断其状态是否为 READY;后者也是按优先级从高到低的顺序,会将主链路上的任务与非主链路的任务分开列队,并且会为主链路上的任务提供指定的 Processor 。具体的内容很快我们就会在下一小节看到😀。
Context
ProcessorContext 类是一个抽象基类,它的实现非常简单,你甚至不用怀疑你的第一直觉,没错,NextRoutine() 和 Wait() 函数就是它最重要的部分。
1 2 3 4 5 6 7 8 9 class ProcessorContext {public :virtual void Shutdown () virtual std::shared_ptr<CRoutine> NextRoutine () 0 ;virtual void Wait () 0 ;protected :bool > stop_{false };
我们重点关注 ClassicContext 和 ChoreographyContext 。首先,看一下最关键的 ProcessorContext::NextRoutine() 的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 std::shared_ptr<CRoutine> ClassicContext::NextRoutine () {if (cyber_unlikely (stop_.load ()))return nullptr ;for (int i = MAX_PRIO - 1 ; i >= 0 ; --i) {ReadLockGuard<AtomicRWLock> lk (lq_->at(i)) ;for (auto & cr : multi_pri_rq_->at (i)) {if (!cr->Acquire ())continue ;if (cr->UpdateState () == RoutineState::READY)return cr;Release ();return nullptr ;std::shared_ptr<CRoutine> ChoreographyContext::NextRoutine () {if (cyber_unlikely (stop_.load ()))return nullptr ;ReadLockGuard<AtomicRWLock> lock (rq_lk_) ;for (auto it : cr_queue_) {auto cr = it.second;if (!cr->Acquire ())continue ;if (cr->UpdateState () == RoutineState::READY)return cr;Release ();return nullptr ;
我们仔细比较一下上文的两个函数,emm……乍一看似乎没什么区别,确实,但细节往往隐藏了海量信息。注意到,ClassicContext 使用的队列是 multi_pri_rq_,ChoreographyContext 使用的队列是 cr_queue_ ,两者类型如下:
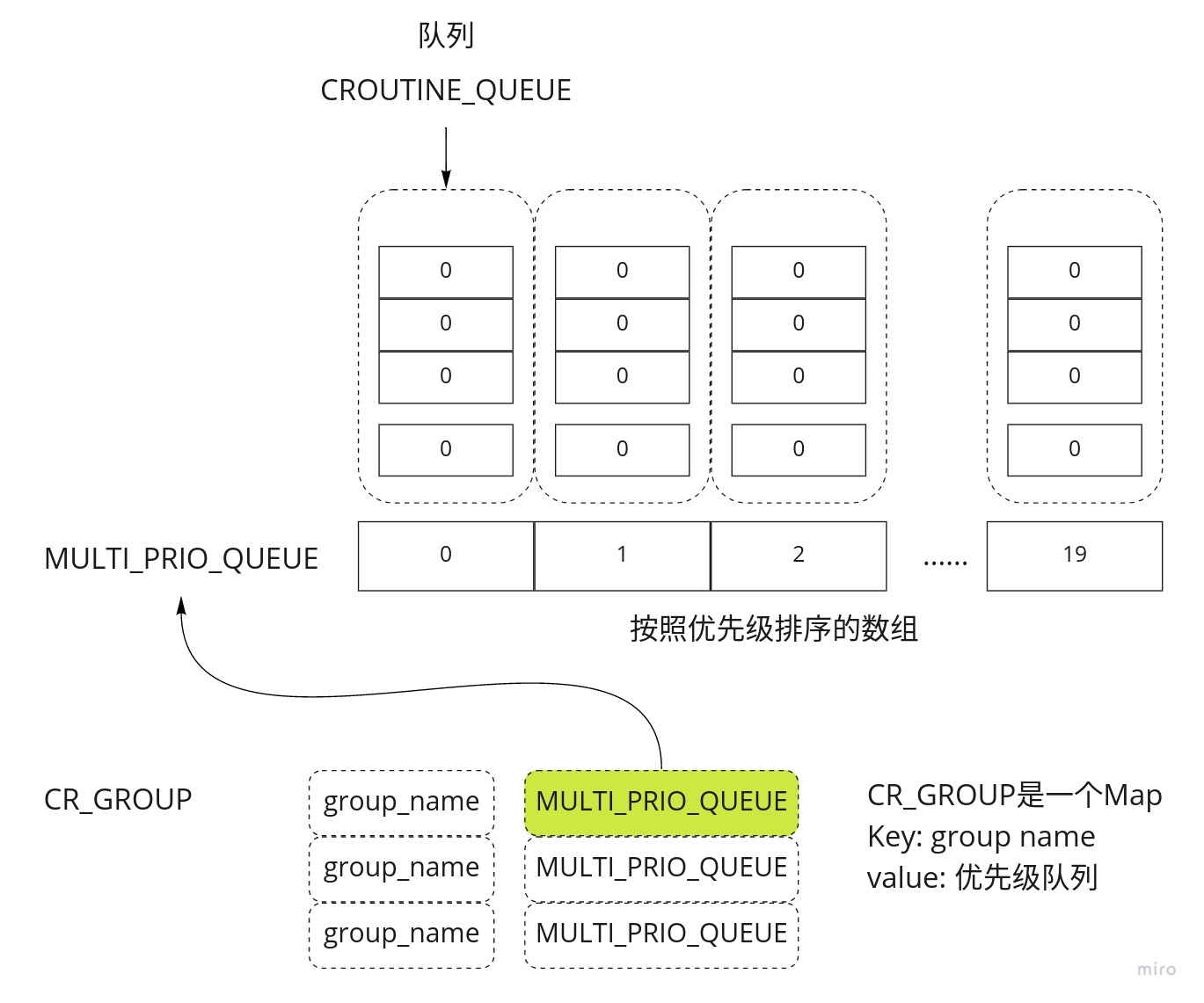
1 2 3 4 5 6 7 using CROUTINE_QUEUE = std::vector<std::shared_ptr<CRoutine>>;using MULTI_PRIO_QUEUE = std::array<CROUTINE_QUEUE, 20 >;using CR_GROUP = std::unordered_map<std::string, MULTI_PRIO_QUEUE>;uint32_t , std::shared_ptr<CRoutine>, std::greater<uint32_t >> cr_queue_;alignas (CACHELINE_SIZE) static CR_GROUP cr_group_;
看清楚了吧,事实上 ClassicContext 使用了多个优先级队列,而ChoreographyContext 用的“队列”只是了一个表(对于 multimap 和 map ,我更喜欢用表格称呼它们)。如果你想进一步了解 multi_pri_rq_,那么可以仔细看一下下面这张图。再结合上面的代码,可以得出两点结论:
CR_GROUP 相当于组名与优先级队列的表格,是一个全局变量,有序地存放了系统中所有的协程。所以说,在 Classic 策略中,“协程是放在全局的优先级队列中处理的”。每一个协程组与一个 ClassicContext 对象对应,一个 ClassicContext 也与一个 Processor 绑定,即与一个线程绑定。这就是我前文所说的“相关协程以组为单位与线程做绑定”的直接证据。
而反观 Choreography 策略,`ChoreographyContext` 只管理那些**主链路**上的协程(任务),不会对协程进行分组。而对于非主链路上的任务,Choreography 策略会把它们扔给 `ClassicContext` 上下文处理。
说完这个,我们再看看 Processor 的线程阻塞和唤醒是怎么操作的:没错,通过上下文的 Wait() 和 Notify() 函数 :man_shrugging:。
1 2 3 4 5 6 7 8 9 10 11 void ClassicContext::Wait () std::unique_lock<std::mutex> lk (mtx_wrapper_->Mutex()) ;Cv ().wait_for (lk, std::chrono::milliseconds (1000 ),return notify_grp_[current_grp] > 0 ; });if (notify_grp_[current_grp] > 0 ) {
1 2 3 4 5 6 7 8 9 void ClassicContext::Notify (const std::string& group_name) Mutex ().lock ();Mutex ().unlock ();Cv ().notify_one ();
看来唤醒和等待都是通过上下文的条件变量 cw_ 实现的,对于 Choreography 策略来说,实现也是类似的。
整体结构
现在,我们跳出这些恼人的代码,俯视整个调度结构。幸运的是,参考文献 [1] 已经提供了两张非常好的图片:我在这里也不厌其烦地重复说一下吧😓
调度系统中,Scheduler 类统管了所有资源,很显然,它必然是单例。
每个 Processor 封装了一个 std::thread ,并于一个 ProcessorContext 对象绑定。
切换协程(任务)由上下文完成,过程几乎都是优先级从高到底遍历,选中已经就绪的协程开始运行。
在一个完整的动作流程中,任务的优先级几乎都是从低到高的。
Choreography 调度策略,主要是针对主链路上的任务进行编排,这些任务会被分配到程序员指定的 Processor 上,且执行先后关系明确,需要对系统有足够深入的了解。
参考文献
[1] 自动驾驶平台Apollo 5.5阅读手记:Cyber RT中的任务调度
[2] 百度 Apollo Cyber Docs
[3] Dig-into-Apollo
[4] Golang 中的协程
[5] 自动驾驶平台Apollo 3.5阅读手记:Cyber RT中的协程