Why RISC-V ?
Why RISC-V ?
在讲完 RISC-V 的基础 ISA 和标准扩展后,我们把注意力集中到 RISC-V C 上,RISC-V Compressed 简称 RVC ,它在基础 ISA 中引入了双长度指令,将最频繁的指令编码为更密集的格式来减少静态代码大小和动态取指令的流量。因为更小的指令占用空间可以降低嵌入式系统的成本(指令存储在嵌入式系统中的成本非常可观),并提高了指令缓存的命中率,提升了缓存系统的性能。取指令消耗了大部分能量,因此从内存中取出更短的指令(意味着更少的字节),也可以显著减少能量消耗。
背景介绍
在嵌入式系统领域,有限的指令内存容量和带宽往往不利于 RISC 架构。为了扩大他们的市场,RISC 供应商给 MIPS 和 ARM 创造了他们的 ISAs 的变种,分别叫做 MIPS16 和 Thumb,它们可以被编码为更窄的 16 位固定宽度指令。这些指令中的大多数与基本 ISA 相似,但对寄存器访问模式和操作数大小有限制。虽然这些压缩的 RISC ISAs 大大降低了代码大小,但它们也有一些缺点。最重要的是,基础 ISAs 的设计者没有考虑到这些压缩指令集:没有充足的编码空间给压缩的指令,因此唯一方法是创建新的、不兼容的指令集。但这就无法与基础 ISAs 混合在一起执行。例如,在 MIPS16 中,ISAs 只能用特殊的跳转指令交换,因此 MIPS 和 MIPS16 代码只在过程调用时混合。
不可与基本 ISA 指令混用对性能有显著的影响。因为有些操作可以很容易地编码在一条 32 位的指令中,比如加载一个大的常量。但现在就可能需要三条 16 位的指令,而且保存额外的中间结果会使压缩的 ISAs 的寄存器数量更加捉襟见肘,此外,用 16 位编码整个 ISA 意味着重要的功能,如浮点,必须被忽略。后来压缩 RISC ISA 变体,如 microMIPS 和 Thumb-2,纠正了这个缺陷,设计了新的 32 位指令,并允许 16 位和 32 位的指令混用。然而因为 32 位指令仍然与基础 ISA 中的指令不一样,所以实现工程师被迫设计和验证两个指令译码器,增加了硬件成本,大大增加了软件生态系统的复杂性。
对基础 ISA 的影响
有了前车之鉴,我们在设计 RISC-V 时在一开始就考虑了如何无缝地支持双长度的指令。当然至关重要的前提是,基本 ISA 和标准扩展只占其编码空间的一小部分,可以给压缩指令充足的编码空间。不像早期的 RISC ISAs 那样,密集地填充着 32 位的编码空间,比如 SPARC,花了 1/4 编码空间在 CALL 指令,相比之下,RISC-V 的基本 ISA 编码消耗小于 1/4 的 32 位编码空间。我们有意识地保留了 3/4 的空间,留给压缩 ISA 扩展指令。这样编码的另一个重要结果是,我们很容易检测一条指令的长度是 16 位还是 32 位:只需要检查两个操作码位。该方案极大地加快了超标量指令的译码速度,因为它要求对指令进行连续扫描以确定其边界。
另外,RISC-V 的基本控制流指令的最小寻址单位是 16 位,而不是 32 位。这样的设计也是为了压缩指令的扩展考虑的——在支持压缩指令时,RISC-V 就不要新增分支和跳转指令。更进一步,我们发现支持任意字节对齐的指令也是很简单的。然而,我们发现 16 位指令就可以节省很多成本了, 8 位和 24 位指令带来的好处,与取指令单元中增加的硬件复杂性相比,可能是不太明智的。更重要的是,这将进一步减小分支和跳转的范围,从而增加了指令数,抵消了新指令宽度所带来的一些代码大小和性能改进。
为了支持 RVC,基础 ISA 唯一改变的是放松了指令的对齐限制,允许它们在任何 16 位对齐的地方开始。显然,保持对齐限制会有一些好处,因为它可以简化指令获取硬件。但是这样做,我们被迫放弃很多代码密度的提升效果。虽然该影响可以通过代码调度在某种程度上减轻,但是对编译器进行这样的额外约束,会出现更多的数据冒险并降低性能,特别是对于静态调度的实现。
RVC 设计理念
两个主要的设计理念引导着 RVC 的设计。首先,RVC 程序不应该比对应的 RISC-V 程序使用更多的指令,并在性能上也至少如此。这个目标很容易实现——保证基本 ISA 指令总是可用的就行。这种设计带来的结果是,RVC 不是一个独立的 ISA,因此宝贵的 RVC 编码空间可以不用花在基本但相对不频繁的操作上,比如用系统调用调用操作系统,而花在可以减小最常见代码序列的规模上。
第二点,每个 RVC 指令必须可扩展为单个 RISC-V 指令。提出这条的原因有两方面,最重要的是,它简化了 RVC 处理器的实现和验证:在指令译码期间,RVC 指令可以简单地扩展为对应的基础 ISA 指令,这样一来,处理器的后端就可以几乎不知道 RVC 指令的存在。此外,汇编程序员和编译器也不需要知道 RVC:代码压缩可以留给汇编器和链接器(当然,若编译器对 RVC 了解更多,也可以为代码压缩提供更多优化)。然而,这种约束确实阻止了一些重要的代码大小优化:比如 load-multiple 和 store-multiple 指令,这是其他压缩 RISC ISAs 的共同特性,不适合此模板。
设定了这两个理念之后,RVC 的设计问题就被简化成了压缩率与译码成本的 tradeoff 的问题。在极端情况下,我们可以将每个可用的 RVC 编码映射到常见的 RISC-V 编码,甚至做出一个指令翻译“字典”。虽然这可以达到最大的压缩率,但有三个主要缺点:字典查找是昂贵的,抵消了取指令节省的能源;增加了指令解码的延迟,可能会降低性能并进一步抵消所节省的能源;最后,字典添加到架构中,会增加上下文切换时间和内存使用。
幸好,RISC-V 指令流的四个属性使得上述方法没有必要:
-
指令中的寄存器有巨大的空间局部性。RISC-V 提供了充足的寄存器数量,减少寄存器数量不足导致的溢出、内存交换等。但即使如此,多数访问仍集中在对少数寄存器。下图展示了在 SPEC CPU2006 benchmark 中寄存器的使用频率。

-
指令只有很少的唯一操作数。一些指令集,比如 Intel 80x86 ,只提供很多破坏性的操作形式:其中的一个源操作数会被结果覆盖。这实质上增加了一些程序的指令数量,因此 RISC-V 的指令都是寄存器——寄存器的非破坏性形式。但是,破坏性算术操作是常见的:SPEC CPU2006 中 47% 的静态算术指令与目标寄存器共享至少一个源操作数。但是,RISC-V 指令只需要通过一些小技巧就可以表达常见的用法。例如,当 ADDI 指令的一个源操作数是
x0时,事实上就是将一个小常量装载到了目的寄存器中。 -
立即数和偏移量都往往很小。大约一半的立即数可以用 5 位表示。静态的,分支和跳转的偏移量通常很大;然而,动态的,几乎 90% 的都在 8 位以内,反映了小循环的优势。此外,由于这些数据是从未压缩的 RISC-V 程序中收集的,因此分支和跳跃的偏移是 RVC 程序的两倍。实际上,对于 RVC 程序,CDFs 最多可以向左移 1 位。
-
一小部分独特的操作码占主导地位。在 SPEC CPU2006(74%)中,绝大多数静态指令是整数装载、加法、存储或分支。如下表所示,20 种最常见的 RISC-V 操作码占静态结构的 91%,占动态指令的 76% 。最常见的指令 ADDI,静态地占指令的四分之一,动态地占七分之一。

根据这些观察结果,我们提出了一种 RVC 设计,它可以表达最常见指令的最常见形式,同时保留编码规则,从而简化实现。
RVC
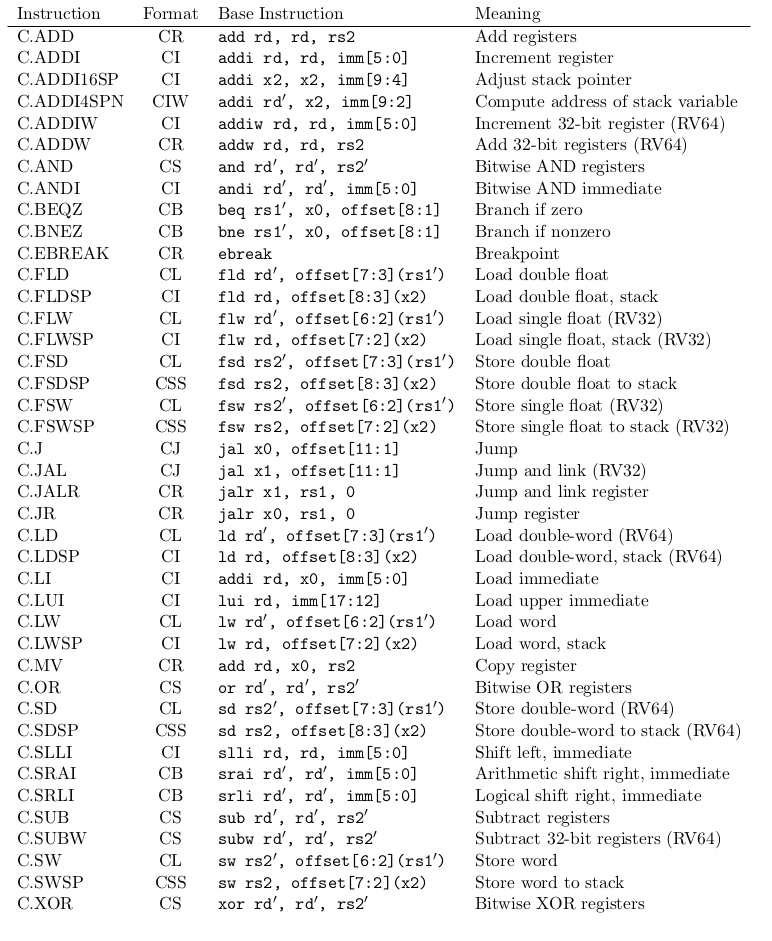
在 RISC-V Compressed ISA 的扩展中,指令使用了 5 位进行编码,目前我们使用了 24 个操作码,占用了编码空间的 3/4 ,留下 11 位给操作数编码。下表列出了主要 RVC 指令的编码格式;几种次要格式在立即数的编码上有所不同。CR、CI 和 CSS 格式可以访问所有的 32 个寄存器,通常为最常见的操作保留,比如复制寄存器或访问堆栈。

考虑到一些寄存器的访问频率远远高于其他寄存器,为了节省编码位数,多数指令被限制为仅可以访问少数最常用的寄存器。例如,CIW 和 CL 指令只能访问 8 个被称为 RVC 寄存器 x8 - x15。在标准调用规范中,这些寄存器对应了两个被调用者保存(callee-saved)的寄存器 s0 和 s1 ,和 6 个调用者保存(caller-saved)的寄存器 a0 - a5。
另外,还有些指令隐式地访问了 ABI 中具有特殊意义的寄存器:零寄存器 x0、链接寄存器 ra 和堆栈指针 sp 。虽然此决策增加了译码的复杂性,但对于在有限的编码空间中捕获一些常见现象(如寄存器溢出)是必要的。事实上,译码电路增加的复杂性是有限的,因为上述几个寄存器的前 3 个 MSB 位都是一样的。
大多数指令格式都包含一个立即数。然而,对于不同指令而言,最常见的立即数值差别很大。例如,而一些 RISC-V 指令通常具有负立即数,其他指令很少这样。前一种情况的典型例子是向后分支等情况。另一方面,相对于堆栈的 loads 和 stores 就不会有负的偏移量,因为使用堆栈指针之下的空间是非法的。因此,不像在基本 ISA 中,它只有符号扩展的立即数,一些 RVC 指令有零扩展。如果我们仅对立即数进行符号扩展,则可压缩的 loads 和 stores 将减少 12%。
类似地,几乎所有的 loads 和 stores 在 RISC-V 程序中都是对齐的,在这种情况下,它们的偏移量可以被字的大小整除。考虑到这个属性,RVC 中的所有 loads 和 stores 偏移量都按字大小对齐。如果我们不这样做,可压缩的 loads 和 stores 将减少 44%。如果我们对这些立即数进行符号扩展,损失将增加到 62% ——或减少 19% 的总压缩量。
RVC 指令编码
下图表示了 RV32C 和 RV64C 指令的编码情况,以及对应的基础 ISA。ISAs 总共有 44 条指令,其中 RV64C 39 条,RV32C 32 条。
整数算术运算是最常见的一类指令,占用了 19 个操作码。5 个 RVC 指令扩展到 ADDI ,这反映出其使用非常频繁:加法(C.ADDI)、累加堆栈指针(C.ADDI16SP)、生成堆栈相对地址 (C.ADDI4SPN)、立即数加载(C.LI)和 C.NOP。许多算术运算是破坏性的,只针对 RVC 寄存器;最常用的指令可以操作任何寄存器。
loads 和 stores 是下一个最具代表性的指令类,占 16 个操作码。RV32C 可以移动 32 位整数和浮点数,以及 64 位浮点数;RV64C 支持 32 位和 64 位整数,但只支持 64 位浮点数(RV32C 32 位浮点加载和存储与 RV64C 64 位整数加载和存储占用相同的操作码空间)。对于每个数据类型,有两种寻址方式:基址加偏移量,基址从 RVC 寄存器中取得,以及相对于栈指针的寻址方式,该方式有一个更远的偏移量。在所有情况下,偏移量都是无符号的,并以数据类型的大小为基本单位。
RVC 提供了条件分支,用于检测是否等于零(C.BEQZ 和 C.BNEZ)、无条件直接跳转(C.J)和寄存器—间接跳转(C.JR)。另外,后两者会链接到 x1,C.JAL 和 C.JALR 指令在标准调用规范下适合函数调用(由于操作码空间有限,RV64C 除去了 C.JAL)。C.EBREAK 是一个断点指令,简化了 RVC 程序的调试。
下图详细地展示了 RV64C 的编码情况。其中 loads 和 stores 就占了 50% 的编码空间,在其余的空间中,算术指令占了 3/4 ,剩下的就是控制流指令。

这一编码方案的明显特征是有大量的立即数编码格式,这是压缩编码空间的结果。然而,就像在 base ISA 一样,立即数编码被打乱了,为的是能最小化产生的立即数的成本。在 12 个立即数选择中,18 个立即数位中的 8 个总是来自指令中相同的位;其中 5 位来自两个地方;4 个来自三个位置;一个来自四个位置。
还有其他一些微妙之处值得注意。对于带有符号扩展的立即数的指令,符号位总是在相同的位置,第 12 位。此外,这些指令都位于不同的操作码空间中,与那些具有零扩展立即数的指令不同;因此,MSB 立即数位(即第 18 位及以上)可以由三个指令的位生成。
对寄存器的译码其实也比你想象的要简单。除了某些指令会对隐式寄存器 x0 x1 x2 访问外,寄存器说明符至多来自三个位置,来计算在基本 ISA 中对应寄存器的编码位置,而译码也只需要检查三个操作码位。尽管如此,对寄存器说明符的译码对于许多实现来说都是至关重要的,尤其是超标量,它必须分析发射的指令集中的数据冒险。激进的实现可能需要额外的流水线阶段来处理增加的延迟,或者加上额外的交叉检查逻辑和寄存器映射表来推测地译码寄存器说明符的所有组合。
或许你已经注意到,还有很多的编码空间被保留了起来。指令 0x0000 在其他情况下会映射到一个冗余指令中,并被永久保留,以提高捕获错误代码的几率。此外,尽管使用所有的编码空间可以最大限度地压缩代码,但我们将一个主要的操作码和几个次操作码保留了下来,以防 RVC 在将来的软件中无法捕获重要的模式。最后,除了规范的 no-op 外,所有不修改体系结构状态的指令形式(例如,将寄存器的值加 0)都被保留下来。若在某个实现上,上述这些目前还没有意义,那么它们也将正确地不执行任何操作,不产生额外的硬件成本。