RISC-V from Scratch 7
RISC-V from scratch 7:内存分页
接上一篇博客,今天我们继续写 RISC-V from scratch 系列博客。原本我打算将该英文系列全部翻译成中文,但原作者貌似没有把这一系列完成就咕咕了。为了将工作继续下去,最终完成一个基于 RISC-V 的迷你小内核。我将这些实验继续做下去,并将自己的实践内容和想法写在这里,与大家分享探讨。
往期回顾
欢迎再次来到 RISC-V from scratch ,先快速回顾一下我们之前做过的内容,为实现时钟中断,我费了很大的力气学习了 RISC-V 机器模式,又简单了解了中断的概念,我们还在 UART 驱动程序的基础上实现了 printf 等工具函数,在机器模式、监管者模式下实现了时钟中断,最终我们得到的实验效果是,我们的小内核可以定时地跟我们说 hello 。
当然,实现时钟中断的最终目的不是让它定时地和我们说你好,而是为了进程调度——时间片。这是我在第六章结尾挖下的坑,然而在后续实验中我发现这一想法太过激进,一下子难以实现。在实现进程之前,我们总得把内存进行分页,好让各个进程的内存相互独立,然后才能有多个进程,才会有进程调度吧😅。
搭建环境
如果你还未看本系列博客的第一部分,没有安装 riscv-qemu 和 RISC-V 工具链,那么赶紧点击上面标题的链接,跳转到 “QEMU and RISC-V toolchain setup” 。
内存管理的预备知识
不得不承认内存分页与管理是一门很大的学问。博主学习了 RISC-V 下的分页机制,也细读了 RISC-V 中文手册,又参考了两篇优质的英文博客 RISC-V OS using Rust chapter 3.1 和 RISC-V OS using Rust chapter 3.2 。再加上自己总结梳理的 RISC-V 特权架构,对整体的理论知识做了个梳理,才算是懂个大概😅。
当我们启动小内核时,代码和数据等所有东西都会被装载到 virt 机器的内存中,我们可以使用 riscv64-unknown-elf-nm 来查看我们程序中定义的符号、函数等位置。
1 | |
小内核严格遵循我们的要求(确切地说是链接器脚本地要求)将代码放在数据段前面。这样的安排在刚开始时确实没啥问题,但如果有多个进程开始执行任务,而数据全部存放在一起的话,那么稍有不慎就会影响其他进程的运行方式。为了让我们的小内核支持类 Unix 操作系统,也为了更好的内存保护,保证进程运行空间的独立性,我们需要良好的内存管理。
分页
如果各位不太明白什么是内存分页,那么分页机制图文详解会给你一个详细的入门介绍,只不过是 x86-64 架构的。而关于 RISC-V 的内存分页机制,以及 satp 寄存器在其中所起的重要作用,我在 RISC-V 特权架构介绍的非常多了,当然也有很多不足甚至错误的地方,也恳请指出。
总的来说,内存分页就是将内存划分为固定大小的页,在低特权模式下,地址(包括 load 和 store 的有效地址和 PC 中的地址)都是虚拟地址,访问内存时必须被转换为真正的物理地址,具体转换方式是通过遍历页表实现的。因而内存分页制度的关键,在于设计并管理虚拟页和物理页的对应关系,即页表的设计。
Sv39
RISC-V 的分页方案以 SvX 的模式命名,其中 X 是以位为单位的虚拟地址的长度,Sv39 指的就是虚拟地址长度为 39 位。我们的内核是基于 RV64 的,简单起见,我打算使用 Sv39 分页模式,因此我先重点介绍一下 Sv39 分页模式。事实上,Sv39 与 在 RISC-V 特权架构介绍的 Sv32 样式基本没变,因此我就简单说一下哈。
为了方便解释,我画了如下示意图:

-
从
satp寄存器中取出 44-bit 的根目录地址,乘以 PAGESIZE (4 KiB) 后,得到 3 级页表地址。 -
取出相对应的 VPN[i],根据 VPN[i] 的值决定 PPN[i] 的页表偏移位置。
-
将得到的 56-bit 的 PPN[i] 取出,乘以 PAGESIZE (4 KiB) 后,得到 2 级页表地址,如此往复,直到遇到了叶 PTE。
-
物理地址的偏移量应等于虚拟地址的偏移量。
注意到:PPN[2] 的长度有 26 位,而整个物理地址的总长度不是 64 位,而是 56 位,使用零扩展了多余的位空间。
上面的这张示意图非常重要,代码实现时可不能没有它;我们提到的 4 点在代码实现时也需要注意。
到底要做什么
在介绍完分页和 RISC-V 的 Sv39 分页机制后,内存分页的理论知识其实就差不多学完了。然而,就如同大学的课程一样,就算认真学完了,你还是不知道具体该怎么做🐶。其中很大的原因,其实是我们不知道该做什么。因此,我先梳理一下在内存分页中,我们的小内核应该:
- 决定何时启动内存分页
- 决定使用何种内存分页机制
- 决定如何管理页块
- 决定页表、进程(用户态、内核态)的内存分布
- 决定某些特殊的物理地址的虚拟地址
- 决定如何处理页错误
我们的小内核不应该做:
- 访问虚拟地址时转换为物理地址
- 快表 (TLB) 的管理
数据结构设计
好了,终于准备完成。万事俱备,只欠东风,我们只差代码实现了。
空闲页块的管理
内存+基于页的分配,意味着分配内存就是以页为单位。俗话说万事开头难,有时候我们必须把自己当作机器才能取得突破。假设你是一个机器,你被受命去拿出一个页的内存给某个进程,你的第一反应是什么?Well,当然是找一个空的页块丢给那个进程。
那么哪里有空的页块呢?哪些块已经被使用了,哪些块用完以后又被进程还回来了呢?我们需要一个空闲页块管理!许多操作系统都会使用链表来帮助它们管理空闲页块,这里也不例外。
链表的头指针指向第一个空闲的页块,然后第一个空闲的页块拿出 8 字节来指向第二个页块,然后第二个页块指向第三个……

这是一个非常棒的做法,我们不需要额外空间(确切的说只要一个指针)就可以源源不断地从链表头部获得空闲块;而遇到回收的情况,也只需要将回收块放到链表头部,而它的代码表示也非常简洁:
1 | |
页的分配与回收
定义了上面的数据结构后,接下来就要考虑一下页的分配与回收问题了。根据链表图示,我们只需要从链表头部取出一个空闲页块,然后将链表头指针后移动就可以了。
1 | |
回收的动作也相似,将要回收的块放到链表头部,再让链表头指针前移。
1 | |
虚拟地址与物理地址
我们还有一个问题没有解决,那就是页表!其实页表自身没有那么深奥,说到底就是一个数组而已。而且在 Sv39 下其长度不会超过 512 。既然是个数组,那么就定义一个指向 64 字节的指针吧🤣。
1 | |
我们之前刚刚实现完页的分配,那么我们就给 kernel_pagetable 页表分配一个页块吧。哦,在这之前,我们必须把空闲块全部用链表串起来。之所以倒序循环,是为了让第一个被分配的页的地址排在前面,不然感觉怪怪的。
1 | |
现在,就要对照着 Sv39 示意图,开始慢慢实现虚拟地址映射到物理地址的代码了。在给定虚拟地址 VA 和物理地址 PA ,要把它们映射起来,使得访问虚拟地址 VA 就是访问物理地址 PA 。
第 1 步,要将 satp 寄存器中的 PPN 转换为页表首地址,这需要我们将特定的值写入到 satp 寄存器中。参考下图,

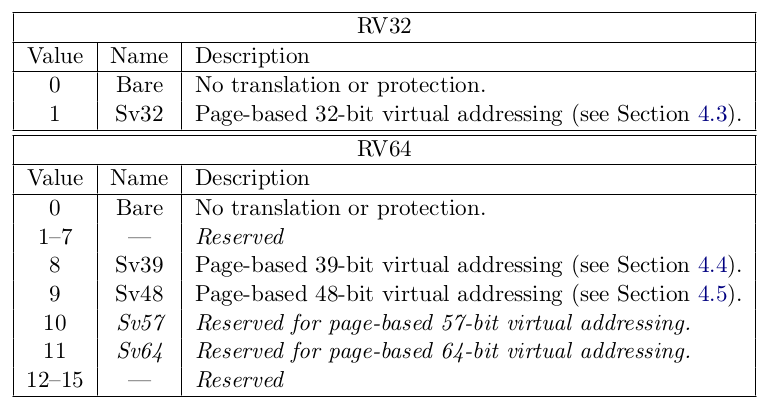
在清楚地知道 satp 寄存器和 SFENCE.VMA 的用法后,写出以下汇编代码。特别注意到,当程序运行完下段汇编代码后,分页就会开启,之后的地址全都是虚拟地址了。因此,这些汇编代码必须在所有准备工作完成后才能执行。
1 | |
第 2 步,从虚拟地址中提取出 VPN[i] ,当虚拟地址为 VA 时,对其进行相应的移位操作,就可以得到偏移量了。具体的函数实现如下:
1 | |
第 3 步,在访问页表并得到对应的 PTE 后,首先要判断:1)是否有效。2)是否为叶 PTE。3)是否有权限访问。然后根据 RISC-V 特权架构和 RISC-V privileged ISA manual 的具体要求,要么产生页错误,要么进行下一级别的页表访问,要么继续得到物理地址等。哦,天哪这可太复杂了,我必须进行简化:
- 忽略页错误
- 不要超级页,默认最后一级的 PTE 就是叶 PTE,其他的都是非叶 PTE
这样的话,我们的代码复杂度会降低很多(当然我们以后会加上),我们先解决一下 PTE 转为页表起始地址的问题:
1 | |
然后再来解决一下遇到的 PTE 无效的问题,可能你会觉得遇到无效的 PTE 直接产生页错误不就好了的错觉。emmm……我们以后确实会这么干,但如果在建立内存分页的过程中也这么干的话,就有点灰色幽默了:你要建立一片内存的分页,首先要创建一个页表(PTE),还未创建的 PTE 当然是无效的(内存全 0 ),如果此时产生页错误,会让我们永远都无法建立这个新页表!我们应当:分配一个空闲页块,置相关的位域,记录其起始地址并将地址回填到相关的 PTE 中。
1 | |
第 4 步,得到了叶 PTE 后就非常轻松了,只要把 PA 存到 PTE 就行了,页偏移量我们不需要手动赋值。
1 | |
等值映射
为什么我们要实现对给定虚拟地址 VA 和物理地址 PA 建立映射关系,因为对某些特殊的物理地址,我们要求其虚拟地址的值与物理地址相同。这被称为等值映射。
等值映射就是虚拟地址的值与物理地址的值相同的情况。为什么要强调等值映射?如果大家还记得 UART 驱动程序的内容,那么应该不会忘记 0x10000000 开始就是 UART 的内存映射寄存器的位置了。在未分页时,我们访问的地址都是物理地址,然而分页后,监管者模式和用户模式下访问的地址就是虚拟地址了,如果没有等值映射,会导致最终访问的物理地址不再是 0x10000000 ,程序也就无法运行下去了。那么,哪些地址需要等值映射呢?先不管那么多,要不就让所有用到的内存地址都等值映射吧。
最后的实现
好了说了这么多零零散散的内容,我们把所有的东西整合起来看一下吧。
首先是空闲页块链表,在使用前,必须先初始化,把空闲页块全部串起来:
1 | |
然后,就是页表的等值映射问题,先分配出一个页表,然后再使用 map 函数,它可以将给定的物理地址和虚拟地址联系在一起,在一开始,我们不分三七二十一,直接把用到的所有地址都进行等值映射。
1 | |
map 函数的实现要难很多,大家要细看虚拟地址与物理地址,函数从第三级页表开始,一步一步地找到虚拟地址对应的叶 PTE。
1 | |
virt2phys 函数中:
pte = &table[get_pagenum(level, va)]利用偏移量找到对应的 PTE 。if (*pte & PTE_V)判断是否有效。if (*pte & PTE_R || *pte & PTE_X)判断是否为叶 PTE 。- 如果无效,需要重新分配出一个页,并且将页的地址放入到 PTE 中。
- 最终,返回叶 PTE 。
最后,不要忘记打开内存分页“开关”:
1 | |
最终,为了方便大家理解虚拟内存和物理内存的分布,我特意画了一幅图。在我的设计中,UART CLINT 等设备的内存映射寄存器的所在地都是等值映射,在未启动分页前的函数也应当在等值映射的范围内,这是方便启动分页后这些函数无需进行重新映射也可以被找到。
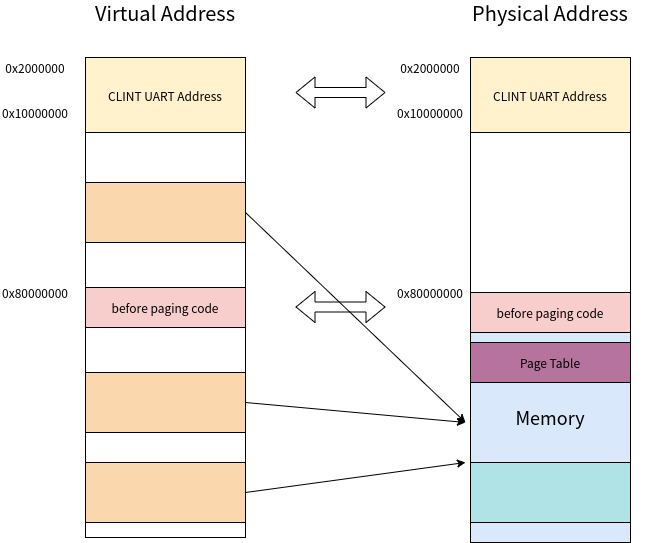
一些疑问
博主在实现内存分页时遇到过很多问题,经过思考后将某些问题的回答记录在此,方便自己和大家更好地理解内存分页机制。
当我注意到 RISC-V 64 支持的分页模式有 Sv39 Sv48 后,我发现 RV64 的分页模式至少有三级分页,而 QEMU 提供的 virt 机器内存大小只有 128 MB ,这难道不会在页表上浪费很大的空间么?经计算我发现,空间占用确实比二级页表、一级页表要大,但不需要很担心空间的问题。事实上在虚拟内存有 128 MB 时,三级页表只有一个 PTE ,因此只存在一个二级页表,而二级页表的 PTE 也只有 64 个,意味着有 64 个一级页表,总共 66 个页表,每个页表占 4 KiB,因此只需要 264 KiB 。相比 128 MB 的物理内存空间,无需担心。我们真正需要担心的是页内空间的浪费,因为我们现在只实现了基于页的内存分配,如在处理 C 语言中 malloc(8) 时也只能分配给 4 KiB 的内存,太不合理了,我们需要实现基于字节的内存分配。这里留个坑,我们可以在进程实现之后再来处理这个问题。
虚拟地址可以比物理地址大么?确实可以,不同的虚拟地址可以映射到同一个物理地址,实现代码/数据的共享。
到底哪些地址必须使用等值映射?博主经过多次实验,发现目前我们所写的代码/数据几乎都需要等值映射。在 RISC-V 64 中,机器模式使用物理地址,而监管者模式、用户模式使用虚拟地址,我认为只要在机器模式下确定的地址,且需要在监管者模式下使用的,基本都需要等值映射,包括程序代码、全局 section 、UART 等等。
接下来
之前我打算攻克下一个难题——进程。但在做初步调研后,发现做进程之前,先完成内核分页可能更加合适。然后我就一头栽进了内核分页这个大坑。弄懂内核分页并实现确实不容易,有很多地方仍需要自己慢慢学习。那么,接下来,我们需要好好消化一下学到的东西,整理一下日益凌乱的文件夹,然后一鼓作气,向进程进军!